

Goodbye, Stored Procedures - the Love/Hate Thing
The debate on the advantages and disadvantages of stored procedures has long existed. Here again, we will examine them one by one.
Pros
Of course, stored procedures have their merits because there is no shortage of applications.
Procedural SQL coding
Seldom is it considered an advantage because people have been accustomed to taking it for granted. SQL syntax requires that data processing code be written in one single statement even if numerous nested queries are needed, bringing disasters for achieving complex data processing logic. Stored procedures enable SQL to accomplish a computation step by step and overcome not a few data processing difficulties through their procedural programming – even if they are a concatenation of individual SQL statements, involve writing temporary tables frequently, and process full of many other imperfections.
Yet the procedural programming ability is not unique to stored procedures. Java can empower SQL to have it, too. Obviously, it is not the only reason to win programmers’ favor.
Separation of UI and business logic
It is a basic principle that the user interface and business logic should be separated. Compared with the backstage data processing logic, the user interface has more varied environments, such as PC and mobile phone, and more volatile display and infrastructure. Decoupling them means that the development and maintenance of the user interface becomes a separate action without involving business logic, as well as cost-effective.
Stored procedures can achieve the separation of the user interface and the business logic. They operate within the backstage database and are only responsible for feeding data to the frontend applications without being affected by the UI environment and any change to the interface’s display and form. Writing all data processing logic as stored procedures helps to create a uniform gateway for data import and export and makes it convenient to achieve access control.
Yet again, the stored procedure is not the only one that has the ability to decouple the user interface and business logic. Another alternative is to write a data access layer and make it the only gateway for data in and out. Actually, it had already been used before microservices became so popular but only failed to become the mainstream practice due to the high degree of development complexity. It is far easier to process structured data in SQL than in Java. The compulsory use of Java for achieving data processing logic under the microservice framework, however, sacrifices the development efficiency.
High performance
Usually, the stored procedure offers better data processing performance than Java that employs SQL to process data outside the database. The former wins because the database requires that data should be processed inside it. An external application must use the database supplied driver to access data in the database, but most of the drivers have unsatisfactory performance, particularly those JDBC drivers intended for Java programs. It is always slow to invoke the JDBC driver to execute SQL in the database. When the application and the database are not in the same physical machine, there will be some network delay, though it is no match for the low-performance JDBC driver. For computations outside the database, it often takes longer to retrieve data from the database than to compute it.
So, the stored procedure enjoys its good performance thanks to the database’s low-efficient access driver.
Here’s a summary of sources of the stored procedure’s advantages: One is SQL’s data processing ability, which is, at least at the present time, much stronger than Java in dealing with structured data computations – particularly the complex ones; the other is the convenience of computing data inside the database, which reduces IO costs that greatly affect the performance of data-intensive tasks.
Cons
It is said that Alibaba, the IT giant, has a strict rule against using stored procedures for the reason that they are hard to debug and scale and, most importantly, unportable. Here let’s look at the demerits of stored procedures.
Low portability
It is very hard to migrate stored procedures. The stored procedure written for achieving the complex enough logic will be certain to use features and syntax unique to the current database. When we switch to another type of database, the part of code containing those features and syntax should be rewritten. It is not so cost-ineffective when only function names and parameter rules (such as date conversion) need to be replaced. When a certain feature that the new database does not support is contained, we need to work out a new algorithm to express the computational logic. And it is almost an impossibility if we want to maintain a satisfactory performance at the same time.
Difficult debugging
Editing and debugging stored procedures is always hard because there isn’t a specific, easy-to-use IDE for them. Often a SQL statement is extremely long, and we need to split it up to debug different parts separately. This is a big hassle. A stored procedure often contains a lot of long SQL statements and has this issue, too. Though the stored procedure uses stepwise coding, we have to output each intermediate result in order to find out the error source due to the lack of an ideal IDE. It is truly inconvenient.
Though matters have improved somewhat in these years, it is far from being smooth and practical, and it seems that database vendors lack interest in working out a solution, in sharp contrast to Java, which has a mature development environment. The debugging difficulties naturally lead to inefficient development.
The closed system
The disadvantage originates from a database defect. The database is based on the concept of “base”, which requires that the external data should be loaded into it for computation. Diverse data sources have become common for today’s applications, but ad hoc data loading is too slow (because of high database IO costs) to meet intensive database access requests, and batch loading data at regular intervals is prone to miss the latest data, getting a less real-time result. What’s more, usually ETL has a time window (from hours deep into the night to the early hours in the next morning), and, when business is busy, the time could be insufficient, and the ETL job cannot be finished in time, affecting business the next day.
Loading and storing external data in a database produces a lot of intermediate tables that will cause relative problems. Usually, data scrapped directly from websites is of multilevel JSON or XML format, and multiple associative tables need to be created in a relational database to store it, exacerbating the intermediate table problem and occupying too much precious database space
The database-based stored procedures thus become as closed and it is inconvenient to compute external data coming from diverse sources with them.
Tight coupling
Usually, stored procedures serve the front-end applications and should, in theory, be stored along with the latter to form a completely functional business component. In practice, the stored procedure is tightly coupled with the database, and thus physically separated from the front-end application, making it impossible to employ one data processing technique for both. As both the stored procedure and the front-end application belongs to the same functional component, maintaining one entails the maintenance of the other. But as the two are separated physically, maintaining them becomes hard and the inability to use one technique to do this makes it harder.
Tightly coupled with the database and separated from the front-end application, a stored procedure is made prone to be used by multiple front-end applications. Over time, it is hard to find out which applications are using the stored procedure. When the data processing code changes in any of the applications, the administrator, facing the messy situation, has little choice but to create a new one rather than trying to modify the existing stored procedure. Thus, stored procedures accumulate and get more intertwined with more applications until the situation becomes hopeless.
Management difficulties
A stored procedure directory has a flat structure instead of the tree structure a file system uses. It is not so inconvenient when there are only a small number of scripts, but as the number grows the directory will get into a mess. Imagine that under one directory where stored procedures of multiple projects, of different modules of the same project, of different years or versions of the same modules are jumbled together. It is extremely hard to distinguish the confusing, messy collection of script files unless we can distinguish them clearly, for instance, by naming them by project, module, year and version – obviously the rule will slow down development. But the regulation is prone to be ignored when a team with lax management is faced with a deadline for rolling out the project, and the naming issue is more likely to be forgotten after the project is finished, leaving the messy status as it is forever.
Low security
Stored procedures, on many occasions, serve queries and analyses whose targets are volatile. As they are closely knitted with the database, each modification will be submitted to database administrator for compilation and publishment, which will definitely increase administration load. The general practice is to grant programmers advanced privileges, or at least the privilege of creating stored procedures, which reduces database administrators’ workload, increases efficiency, but poses serious security threats. Actually, read privilege is enough for handling report queries but stored procedure compilation privilege is nearly the highest one. There is a potential security incident because programmers may mistakenly modify or delete certain data.
Creating the outside database stored procedure using open-source SPL
The list has more cons than pros. So, it is understandable that Alibaba requires that stored procedures be avoided as much as possible. But a more reasonable policy is to use the stored procedure or not to use it according to the characteristics of the current computing scenario.
Actually, there is a better replacement for the stored procedure. The open-source SPL has the merit of stored procedures while overcoming its demerits. We can use it to achieve the “outside database stored procedures”.
esProc SPL is a specialized open-source data computing engine. It offers computational capabilities independent of databases, enabling a switch-over to another type of database without modifying the SPL script and offering a solution to stored procedures’ portability issue. It has a concise and easy-to-use IDE equipped with a complete set of editing and debugging functionalities, making it convenient to achieve various algorithms. The SPL system is open and allows accessing and using non-database data sources directly. The computing engine enables the separate “outside database stored procedure” that can be stored together with the corresponding application, getting rid of the tight coupling issue and script management using the file’s system’s tree structure. And the stand-alone SPL system boasts strong anti-risk ability.
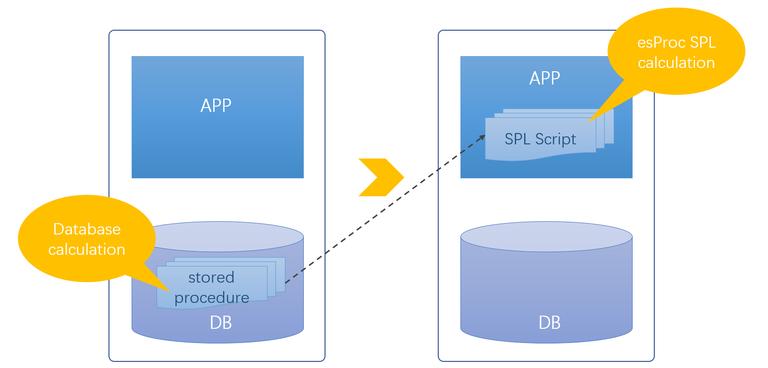
The SPL-based, outside-database stored procedure gets rid of database-related problems.
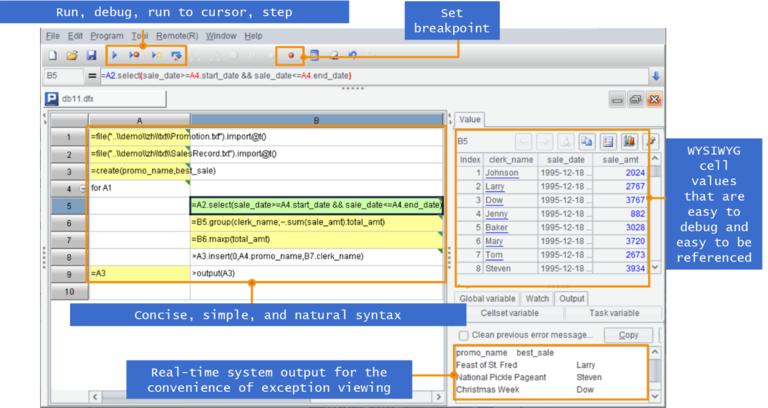
Intuitive and easy to use IDE
SPL has a simple and easy to use develop environment that offers rich functionalities, such as Step, Set breakpoint and WYSIWYG value viewing pane, for efficient development.
Loose coupling, high portability and security
SPL’s outside database computing style does not rely on the database’s computing abilities. The two indispensable features stored procedures have – computing ability and stepwise coding style – find better SPL replacements that help achieve the “outside database stored procedure”. The computing logic tightly coupled with the database is thus able to be divorced from the latter and placed with the corresponding application, creating a loosely coupled architecture.
Decoupling means that the change of database type does not involve modifying the SPL computing logic. This makes code migration convenient. Creating and using the SPL “outside database stored procedure” does not require the database write privilege, which completely eliminates the security problems stored procedures have.
The interpreted execution SPL intrinsically supports hot-swap during operation and for maintenance. It suits really well volatile business requirements under the microservices framework by enabling a modification of application to take effect instantly.

SPL stores the data processing logic in a .splx file. Modifications in the file come into effect in realtime. It is much more efficient than restarting server in such cases in Java and other compiled languages
SPL manages files using the file system’s tree structure, which arranges computing logic for different applications and modules clearly and orderly, making their usage and administration convenient and efficient.
Diverse data source support and open system
Unlike databases that require loading data into them for further computations, which is time-consuming and inefficient and cannot always ensure that data at hand is real-time, SPL computes data coming from different types of data sources directly. Computing data directly lets SPL access and enjoy the advantages of each type of data source, such as the file system’s efficient IO, the NoSQL database’s ability of storing document data and the RDB’s strong computing ability while loading all data into the database keeps the benefits away.
The highly open data source support includes almost all existing data sources, enabling both data retrieval and efficient cross-data-source mixed computations by making effective use of the data sources’ advantages.

The SPL system discards the concept of “base”, enabling it to make good use of and giving full play to the characteristics of each type of data source
Concise and efficient procedural coding
Though stored procedures support procedural programming, SQL lags behind in failing to efficiently dealing with complex computations due to a series of its weaknesses, such as lack of discreteness and inadequate set-orientation. The following example shows this clearly. It counts the largest number of days when a certain stock rises in a row in SQL (Oracle) according to the stock record table:
SELECT code, MAX(ContinuousDays) - 1
FROM (
SELECT code, NoRisingDays, COUNT(*) ContinuousDays
FROM (
SELECT code,
SUM(RisingFlag) OVER (PARTITION BY code ORDER BY day) NoRisingDays
FROM (
SELECT code, day,
CASE WHEN price>LAG(price) OVER (PARTITION BY code ORDER BY day)
THEN 0 ELSE 1 END RisingFlag
FROM stock ) )
GROUP BY NoRisingDays )
GROUP BY code
SQL uses a roundabout way to try to achieve the target. Actually, three steps are enough to get it done effortlessly.
The SQL-based stored procedure inherits the language’s incompetence to handle complex computations efficiently. It is not a rare thing to have a stored procedure with about a thousand lines and of nearly 100KB.
SPL naturally supports procedural programming. The paradigm implements data processing logic step by step and according to a more direct and natural way of thinking. SPL also offers a rich collection of class libraries, and it has agile syntax, making it more convenient in dealing with complex logic.
Let’s look at an example:
【Computing goal】To get the order's records for the first N big customers whose amount takes up at least half of the total.
A |
|
1 |
=file(“/opt/ods/orders.csv”).import@tc() |
2 |
=A1.groups(customer;sum(amount):amount).sort(amount:-1) |
3 |
=A2.sum(amount)/2 |
4 |
=0 |
5 |
=A2.pselect((A4=A4+amount,A4>=A3)) |
6 |
=A2.(customer).to(,A5) |
7 |
=A1.select(A6.pos(A1.customer)) |
SPL breaks down the task into multiple steps – finding the eligible big customers and then querying the details of their orders. It handles computations outside the database and even can use a file source directly. Compared with the stored procedure counterpart, the SPL procedural computation is clearer and more efficient, and its syntax is more concise.
SPL solves the above stock problem in the following way:
A |
|
1 |
=db.query("select * from stock order by day") |
2 |
=A1.group@i(price<price[-1]).max(~.len())-1 |
SPL sorts records in the stock table by trading dates, puts records with continuously rising prices into the same group, and calculates the largest rising days by subtracting 1 from the longest group length. The logic is natural and straightforward. SQL is convenient in dealing with certain scenarios, but comprehensively, it is outperformed by Java. SPL not only supports procedural programming but enables more convenient ways of handling complex computations, making it a better choice than SQL.
Lighter database load and higher performance
SPL, as an outside database computing engine, needs to retrieve data from the database for further computation. When the amount of data needed is large, performance could decrease due to slow database IO.
SPL copes with the issue by moving the large amount of historical cold data from the database to files. SPL reads data directly from files for further processing. This reduces database workload (as database does not need to be responsible for data storage and computing), and makes use of the fast file IO.
Moving data out of the database, along with SPL’s diverse source mixed computation ability, makes it easy to achieve T+0 queries. After retrieving the currently hot data from the database reading the historical cold data from the file system, SPL performs a mixed computation to accomplish the real-time T+0 whole-data query.
SPL also brings about much higher computing performance.
The language provides a variety of high-performance data storage and algorithmic mechanisms that are critically important to software performance. It is easy and simple to achieve a lot of high-performance data storage schemes and algorithms in SPL that are hard to express in SQL.
One example is that SPL treats TopN calculations as a kind of aggregate operations. In this way SPL successfully transforms computations involving complex sorting to relatively simple aggregate operations and finds a wider range of application scenarios.
A |
||
1 |
=file(“data.ctx”).create().cursor() |
|
2 |
=A1.groups(;top(10,amount)) |
Get orders records where amount rank in top 10 |
3 |
=A1.groups(area;top(10,amount)) |
Get orders records where amount rank in top 10 in each area |
SQL handles TopN problems through the low-performance full-table sorting, and turns to database optimization to improve the situation. Yet for even slightly complex scenarios like A3 where a grouping operation is accompanied, the database optimizer becomes useless.
In a word, SPL is the more convenient, efficient, simple and easy-to-use replacement for the stored procedure, as well as its effective extension.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version