

* How to Conveniently Implement Stored Procedures in Hive
Implementing stored procedures in Hive with HPL/SQL is very inconvenient. The open source tool has many restrictions on the use of cursor, which makes it impossible to implement a lot of features. It imposes such strict rules on the use of variables that gives rise to compatibility problems. Both are not fatal flaws if basic debugging functionality functions properly after error in the code reports. The biggest problem is that it is “undebuggable”. That is awkward.
To make things worse, HPL/SQL doesn’t provide the JDBC interface. To embed it into a Java program, you need to run command line to execute the HPL/SQL script and write the result back to a Hive temporary table and then read it through Hive’s JDBC in the Java program.
An alternative, indirect and not better, is Java UDF. Java lacks class libraries for processing structured data, so it implements all algorithms through hardcoding. For example, it writes a two-dimensional table using the combination of “ArrayList+HashMap”, achieves group and aggregate with dozens of lines of code and implements joins with much too lengthy code. There’s no uniform phrasing with hardcoding even for similar business logic. The various solutions make code difficult to read and maintain.
Another problem with Java stored procedures is the tight coupling. Java classes are not hot-deployable, making it impossible to change what’s currently deployed without redeploying it and restarting Hive service. This affects the development environment in a bad way. Though we can choose to design a smart structure to loosen the coupling, we are sure to see an increase in the cost.
There would be no such problems if we had use esProc to write stored procedures. All will be much easier.
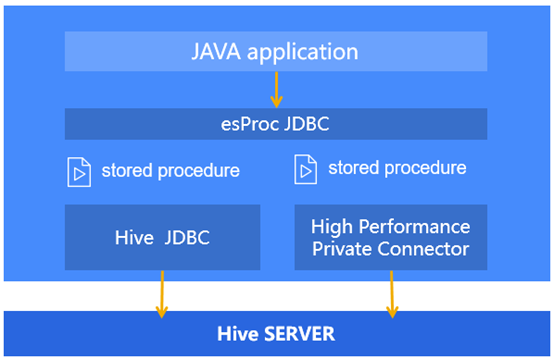
esProc provides a rich variety of class libraries for structured data processing. There are embedded functions for performing retrieval, sorting, aggregation, group & aggregation and joins. The computing tool is also equipped with branch statement, loop statement and agile syntax to implement complicated business logic effortlessly. It allows setting a breakpoint and using trace & debug to facilitate quick error correction; and offers the standard JDBC interface through which the stored procedure, which is saved as a separate script file, can be invoked by the up-level Java program. You can edit the script file as needed and won’t affect the Java code and Hive service. To bring the interface down, esProc supports standard Hive JDBC as well as high-performance proprietary interface to execute HSQL statements.
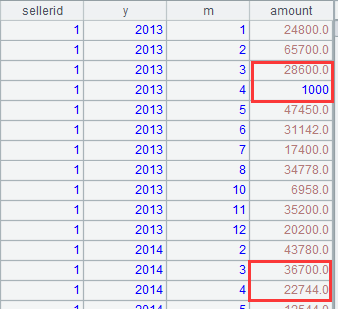
Here’s an example. The Hive table sales is grouped and summarized by seller, year and month as follows:

A query with stored procedure could be this. We need to adjust the amounts for each seller by transferring 1000 from April’s amount to March’s for each seller in each year. If the amount in March is null, append an empty record with amount -1000 to it to balance the account; if the amount in April is null, append an empty record with amount 1000 to it; if both months have nulls, no balancing will be made.
Below is the expected result:
esProc script for implementing the stored procedure:
A |
B |
C |
D |
|
1 |
=connect@l("hiveDB") |
/Connect to Hive via JDBC |
||
2 |
=A1.cursor@x("select sellerid,year(orderdate) y,month(orderdate) m,sum(amount)amount from sales group by sellerid,year(orderdate),month(orderdate) order by sellerid, year(orderdate),month(orderdate)") |
/Run HSQL |
||
3 |
=A2.create() |
/Create an empty result table |
||
4 |
for A2;[sellerid,y] |
/Batch process data in each year for a seller |
||
5 |
=A4.select(m==3) |
=A4.select(m==4) |
/Records in Mar. and Apr. |
|
6 |
if B5!=[] && C5!=[] |
>B5.amount=B5.amount-1000 |
/If both exist then modify values in batch |
|
7 |
>C5.amount=C5.amount+1000 |
|||
8 |
else if B5==[] &&C5!=[] |
>A3.record([A4.sellerid,A4.y,3,-1000]) |
/If Mar. is null then add new record to the result table |
|
9 |
>C5.amount=C5.amount+1000 |
/Batch modify |
||
10 |
else if B5!=[] &&C5==[] |
>B5.amount=B5.amount-1000 |
/If Apr. is null then add new record to the result table |
|
11 |
>A3.record([A4.sellerid,A4.y,4,1000]) |
/Batch modify |
||
12 |
>A3.paste@i(A4.(sellerid),A4.(y),A4.(m),A4.(amount)) |
/Union up this batch to result |
||
13 |
return A3.sort(sellerid,y,m) |
/Sort result and return it |
||
Read How to Call an SPL Script in Java to learn how to deploy esProc JDBC to call the SPL script.
About esProc installation, free license download and relevant documentation, see Getting Started with esProc.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_SPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL

