

esProc SPL captures web page data
The data source on the website is an important information source for our statistical analysis. When we browse the web page and see the data content we are interested in, we hope to quickly capture the data on the web page, which is extremely important for data analysis related work, and is also one of the necessary skills. However, most of the network data capture needs complex programming knowledge and complicated operation. This paper introduces how to use esProc SPL to quickly capture web data.
1. Basic flow chart2. Interface to capture web data
3. Define rules
A. web_info
B. init_url
C. help_url
D. target_url
E. page_url
4. Capture stock history data
5. User defined program
A. Data extraction program interface
B. Data saving program interface
C. Data extraction program example
D. Data saving program example
E. Use of user defined program
1. Basic flow chart
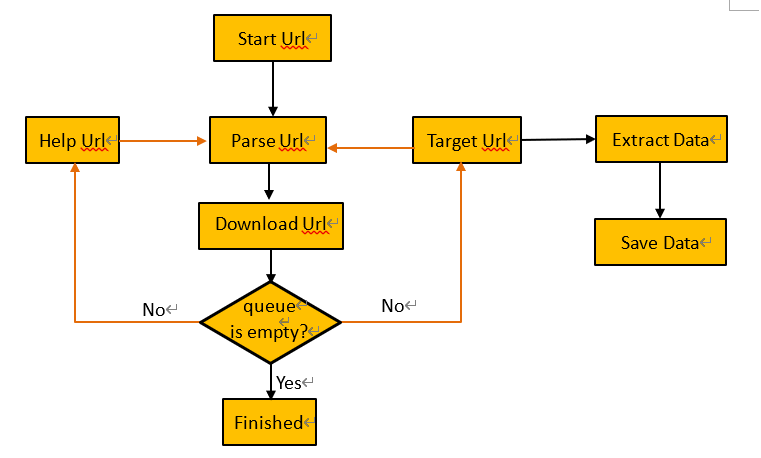
Traverse from the given starting URL, put the parsed and filtered URLs into the download URL queue, and divide it into help_url and target_url. The help_url only collects the web URLs, and the target_url can collect the web URLs, and can also extract the data, and save the extracted data. Crawl the web data until the traversed URL is empty, then the crawl is finished.
2. Interface to capture web data
Web_crawl(jsonstr) is the interface to capture web data. The parameter jsonstr is a string to define rules. When capturing data, it traverses the URL, downloads, extracts and saves relevant content data according to the rules.This interface depends on the external library webcrawlCli of esProc. It is installed in the esproc \ extlib \ webcrawlCli path of the esProc software by default. Check the webcrawlCli item in the external library settings of esProc. After esProc is restarted, you can use the web_crawl interface.

For simple usage of web crawl, such as fetching specified stock data, SPL script demo.dfx:
| A | |
| 1 | [{web_info:{save_path:'d:/tmp/data', save_post:'false'}},{init_url:['http://www.aigaogao.com/tools/history.html?s=600000']},{page_url:{extractby: "//div[@id='ctl16_contentdiv']/",class:'default'}}] |
| 2 | =web_crawl(A1) |
| 3 | =file("D:/tmp/data/raqsoft.com/600000.txt").import@cqt() |
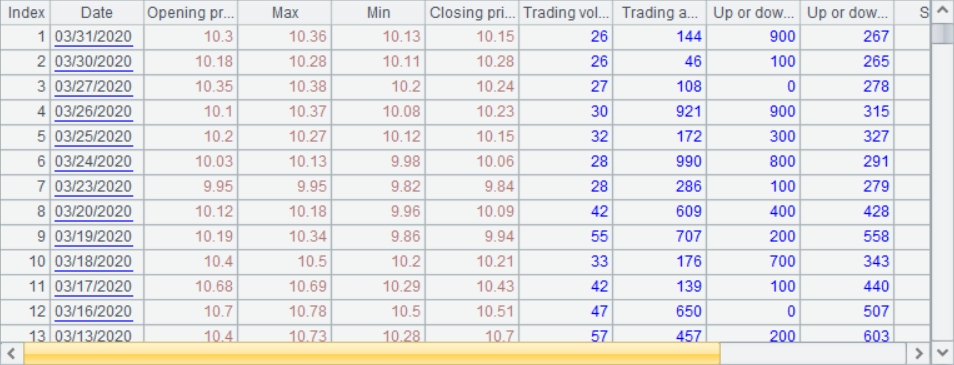
To obtain the data file of stock code 600000:

File content:
3. Define rules
According to the basic flow chart, the definition rules are divided into five parts: website information, initial URL, help URL, target URL and data extraction. The details are as follows:[
{ web_info:{domain:'www.banban.cn', save_path:'d:/tmp/data/webmagic', thread_size:2, cookie:{name:"jacker", laster:"2011"},
user_agent:'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0'}},
{ init_url:['https://www.banban.cn/gupiao/list_cybs.html', 'https://www.banban.cn/gupiao/list_sh.html']},
{ help_url:['gupiao/list_(sh|sz|cyb)\.html', '/shujv/zhangting/', '/agu/$']},
{ target_url:{reg_url:'/agu/365\d'}},
{ target_url:{filter:'gupiao/list_(sh|sz|cyb)\.html', reg_url:'gupiao/[sz|sh]?(60000\d)/',new_url:'http://www.aigaogao.com/tools/history.html?s=%s'}},
{ page_url:{filter:'history.html\?s=\d{6}', extractby: "//div[@id='ctl16_contentdiv']/"}},
{ page_url:{extractby: "//div[@id='content_all']/"}},
{ page_url:{filter:'/agu/365\d', extractby: "//div[@id='content']/"}}
]
Brief description of rules:
web_info:website information. According to the website to be downloaded, set the domain name, local storage location, user agent information, user-defined program and other relevant information.
init_url:initial URL. The entry URL for URL traversal.
help_url:define rules of web page, collect URL in web content, but do not extract data content of this page.
target_url:define download page rules, collect URL in the page content, and extract the content of this page at the same time.
page_url:extract data. Define page content extraction rules, and extract content according to these rules in target_url.
Note: JSON the structure details. [] in node {} represents the list, and {} in node {} represents the map key value structure. Pay attention to the writing, otherwise, incorrect writing may cause parsing errors.
Description of rules:
A. web_info
Set the information to download, including:Domain: set the domain name.
save_path: file save path.
user_agent: refers to user agent information. Function: enable the server to identify the operating system and version, CPU type, browser and version, browser rendering engine, browser language, browser plug-in, etc. used by clients.
sleep_time: crawl interval.
cycle_retry_times: number of retries.
charset: set the encoding.
use_gzip: whether it is gzip compression.
time_out: fetching timeout setting.
cookie_name: Cookie information, key value structure. thread_size: number of threads when fetching.
save_post: whether to append string to the saved file name to prevent the downloaded file from being overwritten. The default value is true. For example, books/a.html and music/a.html are all pages to download. If this parameter is true when saving, the stored file names are a_xxxcgk.txt and a_xabcdw.txt respectively, and the file will not be overwritten. If it is false, the saved file names are a.txt, and then the stored file will overwrite the existing file with the same name.
class_name: user defined storage class.
class_argv: the string parameter passed to the class_name class.
B. init_url
Initial URL.It’s a list structure, and multiple URLs can be set.
C. help_url
The help_url mainly defines the URL filtering rules to be collected. URLs that meet the rules will be added to the download URL queue, but the specific content will not be extracted. Filtering rules support regular expressions, such as: gupiao/list_(sh|sz|cyb)\.html means that only the links of gupiao/list_sh.html, gupiao/list_sz.html and gupiao/list_cyb.html can be passed.It’s a list structure, and multiple rules can be defined.
D. target_url
The target_url is the URL to retrieve the content, from which the content needs to be extracted. If this URL complies with the help_url filtering rules, then the URL will also be collected in this page. Format of definition rule:
{target_url:{filter: pageUrl, reg_url:urlRegex, new_url:newUrl}}, indicates that in the page that meets the pageUrl condition, find the href link that meets the urlRegex condition. If newUrl is defined, it can be combined with the urlRegex filtering result to form a new URL. For example, if you find the link a_100.html in the page that meets the filter condition reg_url=a_(\d+)\.html, there is newUrl=b_%s.php, then the result of urlRegex filtering a_100.html is 100, which will be merged with newUrl, and the new download page is b_100.php.
Where filter represents the URL rule defining the filter; if there is no such definition, it means that all target_url should use this rule.
reg_url indicates the URL rules to be collected, which are required; target_url rules without reg_url are meaningless.
new_url means to define a new page, which needs to be combined with reg_url filtering result to form a new URL.
For example:
3.1 Define rules :{target_url:{filter:'gupiao/list_(sh|sz|cyb)\.html', reg_url:'gupiao/([sz|sh]?6000\d{2})/',new_url:'http://www.raqsft.com/history.html?s=%s'}}
In the download page, gupiao/list_sh.html, the following contents are included:
<li><a href="/gupiao/600010/">BaoGangGuFen(600010)</a></li>
<li><a href="/gupiao/600039/">SiChuanLuQiao(600039)</a></li>
<li><a href="/gupiao/600048/">BaoLiDiChan(600048)</a></li>
A. gupiao/list_sh.html meets filter conditions
B. The href string matches the reg_url condition and will result in [600010, 600039, 600048]
C. Filter result and newUrl generate new URL:
http://www.raqsft.com/history.html?s=600010
http://www.raqsft.com/history.html?s=600039
http://www.raqsft.com/history.html?s=600048
%s in the new_url is a placeholder for the merged string.
3.2 Define rules:
{target_url:{reg_url:'/ gupiao/60001\d'}},
In the download page, gupiao/list.html, the following contents are included:
<li><a href="/gupiao/600010/"> BaoGangGuFen(600010)</a></li>
<li><a href="/gupiao/600039/"> SiChuanLuQiao(600039)</a></li>
<li><a href="/gupiao/600048/"> BaoLiDiChan(600048)</a></li>
If the conditions of reg_url are met, the collected URL is:
http://www.xxx.com/gupiao/600010/
The other two href do not meet the filter conditions.
The purpose of setting filter is to collect URLs in the filtered pages. When there are many help_urls, the filtering reduces the scope and improves the efficiency.
The target_url rule can define multiple rules to adapt to different conditions.
E. page_url
Data extraction. It is mainly used to extract the content of the download page. It means to use this extraction rule to save the extracted results. Refer to the xpath instructions for defining this rule. It only extracts the main content, and it also needs the className to extract the content details.Format of definition rule:
{page_url:{filter: pageUrl, extractby: contentReg, class: className }},
Where filter represents the URL rule that meets the filtering conditions. If there is no such definition, it means that all target_url should use this rule.
Extractby represents the page content extraction rule. If class is defined, it means content extraction is performed by className class; if classname=”Default”, it means to extract data in the current default way, that is, to extract data for the content in the table. If the default extraction does not meet the requirements, the user can customize the class to implement. For specific implementation, refer to the user-defined program later.
For example:extractby :"//div[@class=news-content]/text()".Extract the data under this node from the web page.
Page_url can make different rules for different pages. Extracting data through the filtered page to reduce the number of URLs to be processed. When there are many target_urls, the efficiency can be improved.
If there is no extractby rule, it means to extract all the content in the target_url page.
If more than one page_url rule is defined, the first content meeting the rule will be extracted.
If the content of page A conforms to the rules R1, R2 and R3, R2 is the first step to extract the content, then the data will not be extracted according to the rules R1 and R3.
Note: if the target_url rule is not defined, but the current page has a suitable page_url rule, the content of this page will also be extracted.
4. Capture stock historical data
Next, we will use capturing the stock historical data to illustrate how the web_crawl() interface is applied. Basic operation: first obtain the stock code, then query the historical data through the stock code, extract the data from the download page and save it.
A. Extract the stock codes of Shanghai Stock Exchange, Shenzhen Stock Exchange and GEM at the help_url of https://www.banban.cn/gupiao/list_xxx.html.
B. Combine the stock code with http://www.aigaogao.com/tools/history.html?s=%s to generate the target_url to download.
C. Extract the content in the target_url.
D. Display the extracted content.
SPL code is stock.dfx:
| A | B | |
| 1 | [{web_info:{domain:"www.banban.cn", save_path:"d:/tmp/data/webcrawl", save_post: "false",thread_size:2 }},{init_url:["https://www.banban.cn/gupiao/list_cybs.html", "https://www.banban.cn/gupiao/list_sh.html"]},{help_url:["gupiao/list_(sh|sz|cyb)\.html"]},{target_url:{filter:"gupiao/list_(sh|sz|cyb)\.html", reg_url:'gupiao/[sz|sh]?(\d{6})/',new_url:"http://www.aigaogao.com/tools/history.html?s=%s"}},{page_url:{filter:"history.html\?s=\d{6}", extractby:"//div[@id='ctl16_contentdiv']/"}},{page_url:{extractby:"//div[@id='content_all']/"}}] | |
| 2 | =web_crawl(A1) | |
| 3 | =file("D:/tmp/data/ webcrawl/www.banban.cn/600010.txt").import@cqt() |
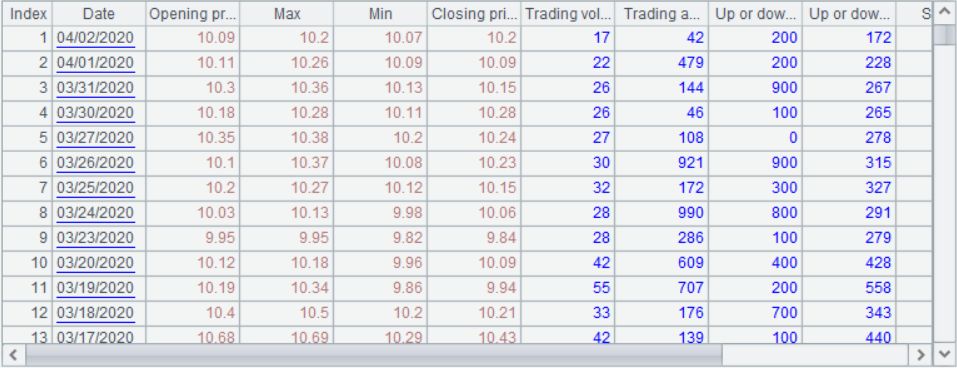
Load the stock 600010 data as follows:
5. User defined program
For content extraction, table content in html is extracted by default. Just as there is no one webpage that is the same for all in the world, there is no once and for all extraction algorithm. In the process of using web data capture, you will encounter various types of web pages, and you need to implement the corresponding extraction method for these web pages. The storage method is similar. By default, file saving is provided. If you want to use other methods such as database storage, you need to develop your own program. Refer to the following interface to integrate the custom program into the web data capture process.A. Data extraction program interface
The content of the download page is in various forms and has different features. In order to meet the needs of more content extraction, users can customize the data extraction program. Interface program:
package com.web;
import us.codecraft.webmagic.Page;
public interface StandPageItem {
// Data extraction processing.
void parse(Page p);
}
You need to implement the com.web.StandPageItem interface parse (Page p), where data extraction is implemented.
B. Data saving program interface
There are many ways to store extracted data. In order to meet the needs of more data storage, users can customize the data storage program.Interface program:
package com.web;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
public interface StandPipeline extends Pipeline {
public void setArgv(String argv);
public void process(ResultItems paramResultItems, Task paramTask);
}
You also need to implement setArgv()and process() in the com.web.StandPipeline class.
setArgv()input parameter interface, process() process storage data interface.
C. Data extraction program example
Implement com.web.StandPage interface parse(Page p).Reference code :
package com.web;
import java.util.List;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.selector.Selectable;
public class StockHistoryData implements StandPageItem{
@Override
public void parse(Page page) {
StringBuilder buf = new StringBuilder();
List<Selectable> nodes = page.getHtml().xpath("table/tbody/").nodes();
for(Selectable node:nodes){
String day = node.xpath("//a/text()").get();
List<String> title = node.xpath("//a/text() | tr/td/text()").all();
if (title.size()<5) continue;
String line = title.toString().replaceFirst(", ,", ",");
buf.append(line+"\n");
}
page.putField("content", buf.toString());
}
}
The data to be saved is stored in the field "content" of the page. When saving, it will be obtained from the field "content".
D. Data saving program example
Implement setArgv()and process() in the com.web.StandPipeline class.
Reference code:
package com.web;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import org.apache.commons.codec.digest.DigestUtils;
import us.codecraft.webmagic.utils.FilePersistentBase;
public class StockPipeline extends FilePersistentBase implements StandPipeline {
private Logger logger = LoggerFactory.getLogger(getClass());
private String m_argv;
private String m_path;
public static String PATH_SEPERATOR = "/";
static {
String property = System.getProperties().getProperty("file.separator");
if (property != null) {
PATH_SEPERATOR = property;
}
}
public StockPipeline() {
m_path = "/data/webcrawl";
}
// Get storage path and storage filename prefix
public void setArgv(String argv) {
m_argv = argv;
if (m_argv.indexOf("save_path=")>=0){
String[] ss = m_argv.split(",");
m_path = ss[0].replace("save_path=", "");
m_argv = ss[1];
}
}
public void process(ResultItems resultItems, Task task) {
String saveFile = null;
Object o = null;
String path = this.m_path + PATH_SEPERATOR + task.getUUID() + PATH_SEPERATOR;
try {
do{
String url = resultItems.getRequest().getUrl();
o = resultItems.get("content");
if (o == null){
break;
}
int start = url.lastIndexOf("/");
int end = url.lastIndexOf("?");
if (end<0){
end=url.length();
}
String link = url.substring(start+1, end);
if (m_argv!=null && !m_argv.isEmpty()){
link = m_argv+"_"+link;
}
if (link.indexOf(".")>=0){
link = link.replace(".", "_");
}
//Add md5hex to prevent duplicate names
String hex = DigestUtils.md5Hex(resultItems.getRequest().getUrl());
saveFile = path + link+"_"+ hex +".json";
}while(false);
if (saveFile!=null){
PrintWriter printWriter = new PrintWriter(new FileWriter(getFile(saveFile)));
printWriter.write(o.toString());
printWriter.close();
}
} catch (IOException e) {
logger.warn("write file error", e);
}
}
}
E. Use of user defined program
After compiling the above interface files and java files, package them into webstock.jar file, put it under the path of esProc\extlib\webcrawlCli and restart esProc. Data storage program is configured in web_info; data extraction program is configured in page_url. The following is the DFX script to load two user defined programs.
SPL code mytest.dfx:
| A | B | |
| 1 | [{web_info:{domain:"www.banban.cn", save_path:"d:/tmp/data/webmagic", thread_size:2,user_agent:"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0",class_name:'com.web.StockPipeline',class_argv:'stock'}},{init_url:["https://www.banban.cn/gupiao/list_cybs.html", "https://www.banban.cn/gupiao/list_sh.html"]},{help_url:["gupiao/list_(sh|sz|cyb)\.html", "/shujv/zhangting/"]},{target_url:{filter:"gupiao/list_(sh|sz|cyb)\.html", reg_url:'gupiao/[sz|sh]?( \d{6})/',new_url:"http://www.aigaogao.com/tools/history.html?s=%s"}},{page_url:{filter:"history.html\?s=\d{6}", extractby:"//div[@id='ctl16_contentdiv']/", class:'com.web.StockHistoryData'}}] | |
| 2 | =web_crawl(A1) |
Generating result:
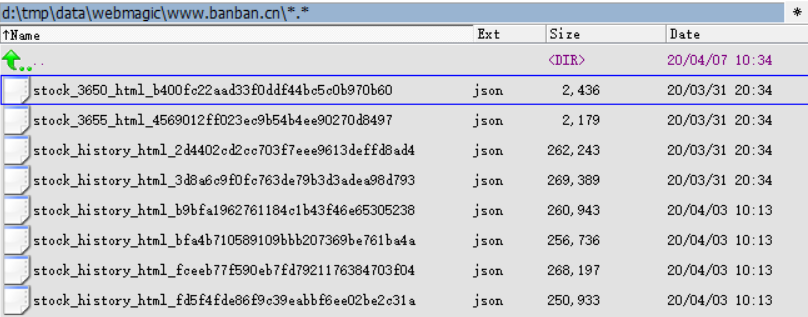
Similar to content extraction or data storage, refer to the implementation of the above program, users can customize Java programs.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

