

Fill in the Cell Value by the Position in the Category
Exampe1
There is a data table in data.xlsx. Some index numbers are stored in the Header1 field, but the index numbers may have duplicate values. As shown in the red box in the figure below, there are two 101s. The original table is as follows:
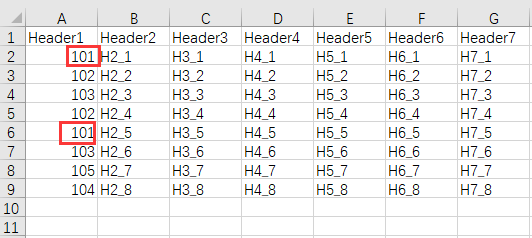
The data of another file target.xlsx is shown as follows:
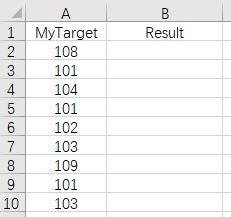
The task is to fill data in the Result column, and its value is calculated as: use the values of the MyTarget column to query the Hearder1 in data.xlsx, if there is no target value, fill in with “no”; if there exists the target value, fill in with its ordinal number; if the number of the target value exceeds, fill in with “no more”. The result is shown below:
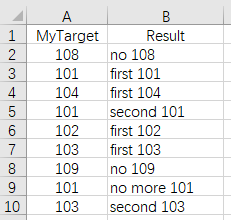
Write SPL script:
A |
|
1 |
=T("e:/work/data.xlsx") |
2 |
=T("e:/work/target.xlsx") |
3 |
[first,second,third,fourth,……] |
4 |
=A2.group(MyTarget) |
5 |
=A4.run(a=A1.select(Header1==A4.MyTarget).count(),~.run(Result=if(a==0:"no",#>a:"no more",A3(#))/" "/MyTarget)) |
6 |
=T("e:/work/result.xlsx",A2) |
A1 Read the data of data.xlsx
A2 Read the data of target.xlsx
A3 Define the sequence of English words in numerical order
A4 Group A2 by MyTarget
A5 Loop through each group in A4, and calculate the number of records in A1 where Header1 is equal to the MyTarget of this group and assign it to variable a. Loop through each record in this group, and set the value of the Result column as: (If a is 0, return “no”; if the sequence number # of the current record in the group >a, return “no more”, otherwise return the word corresponding to the sequence number # in A3) + space + MyTarget.
A6 Store the table sequence in A2 to result.xlsx
Example2
The unsorted course data of data.xlsx is as follows:
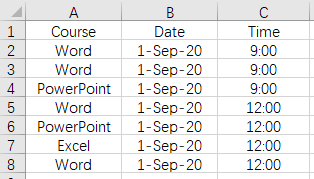
The task is to add a new code column Batch ID so that the records with the same Course\Date\Time values have the same Batch ID. The code is composed of the first three letters of Course + sequence number. After the data is divided into large groups by Course, each large group of data is divided into smaller groups by Date and Time. The sequence number in the code is the sequence number of each small group in the large group.
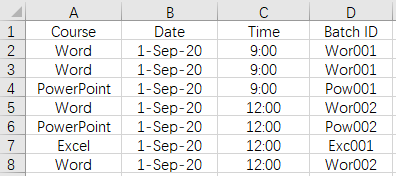
Write SPL script:
A |
|
1 |
=T("e:/work/data.xlsx") |
2 |
=A1.group(Course).(~.group(Date,Time)) |
3 |
=A2.conj(~.news(~;Course,Date,Time,left(Course,3)/string(A2.~.#,"000"):'Batch ID')) |
4 |
=T("e:/work/result.xlsx",A3) |
A1 Read the data of data.xlsx
A2 Grouped the data by Course, and each group is further grouped by Date and Time for the second layer
A3 Calculate each small group in the large group first, generate a new column of Batch ID according to the rules, then merge the small groups, and finally merge the large groups. A2.~.# indicates the number of each small group in the large group
A4 Store the table sequence in A3 to result.xlsx
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_Desktop/
SPL Learning Material 👉 https://c.scudata.com
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProcDesktop
Linkedin Group 👉 https://www.linkedin.com/groups/14419406/

