

How to Delete Rows with Duplicates in a Specific Column
Problem description & analysis
Below is the data of Excel file book1.xlsx:
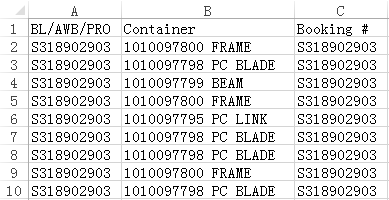
We are trying to perform distinct by column: find duplicate values in Container column and remove the rows where these values are located. Below is the expected result:

Solution & explanation
We write the following script (p1.dfx) in esProc:
A |
|
1 |
=clipboard().import@t() |
2 |
=A1.group(Container).select(~.len()==1).conj() |
3 |
=file("result.xlsx").xlsexport@t(A2) |
Explanation:
A1 Import data from the clipboard as a table sequence.
A2 Group the table sequence by Container column, get groups that contain only one record, and concatenate the eligible groups.
A3 Export A2’s result to result.xlsx.
After the code is executed, result.xlsx is what we expect.
https://stackoverflow.com/questions/64219953/remove-duplicates-based-on-specific-column-name
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_Desktop/
SPL Learning Material 👉 https://c.scudata.com
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProcDesktop
Linkedin Group 👉 https://www.linkedin.com/groups/14419406/

