

SPL: Reading and Writing Structured Text Files
Structured text files, such as TXT and CSV files, are stored in common row-wise format. In such a file, each row is a record and all rows have same columns. The file is similar to a database Table. There are some points you need to pay attention to when reading and writing structured files:
1.Header row: It contains field names and is always the first row. The header row can be absent and, in that case, records begin from the first row.
2.Separator: A separator is used to separate field values in each detail row and field names in the header row. Common separators include comma, Tab key (\t) and the vertical line, and so on.
3.Character set: Common character sets used for saving data in a file are UTF-8, ISO8859-1, GBK, etc.
4.Special characters: Field values may contain some special characters, such as quotation marks, parentheses and escape characters. Frequently used escape characters include \”, \t, \n, \r, and double quotes in Excel.
5.Large files: A large text file is one whose data cannot be wholly loaded into the memory.
It would be convenient to handle the above points if you use SPL to read and write structured text files.
1. Data reading
SPL uses file function to open a text file and read data from it as a Table sequence or a cursor for further computations. When the file can fit into the memory, just use import function to read it as a Table sequence. When the file is too large to fit into the memory, use cursor function to read it as a cursor.
Let’s take import function to look at how to read data from a text file in SPL. Same options and parameters are used for cursor function.
1.1 With the header row and Tab-separated
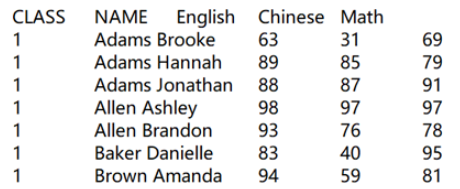
=file("scores.txt").import@t()
The parameter in file function can be the target file’s absolute path or relative path (which is relative to the mainPath configured in SPL configuration file). The import function works with @t option to read headers in and use the default separator Tab (\t).
1.2 Without the header row and comma-separated
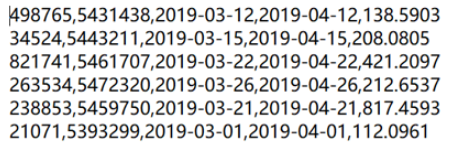
=file("d:/order/orders.txt").import@c()
@c option means that the targe file is of CSV format. The absence of @t option means that the header row isn’t needed. A file without the header row does not have column names and columns will be referenced using their ordinals, such as #1 and #2.
1.3 With the header row, vertical-line-separated and using utf-8 charset

=file("d:/txt/employee.txt":"utf-8").import@t(;,"|")
We can add a charset parameter to file function since garbled code may be shown if wrong charset is used. The OS default will be used if no charset is specified. In the import function, @t option enables reading headers in and parameter “|” represents the vertical line separator.
=file("d:/txt/employee.txt":"utf-8").import@t(EID,NAME,GENDER,DEPT;,"|")
The above statement adds column name parameters to read values from EID, NAME, GENDER and DEPT fields only.
1.4 With the header row and of JSON format
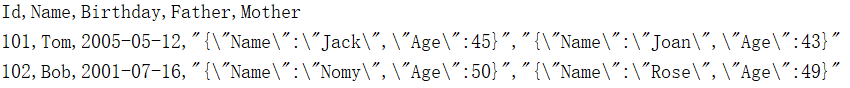
=file("d:/txt/employee.txt").import@tcq()
The @t option enables to import headers. @c option means comma-separated. @q option enables to remove quotes from both end of a data item, including headers, and to handle escaping while leaving quotes within an item alone.
Below is data in the imported Table sequence:

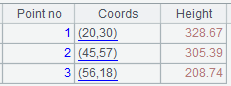
1.5 With the header row and containing parentheses in detail data

=file("d:/txt/measure.txt").import@tcp()
The @t option enables to import the header row. @c option means comma-separated. @p, which covers functionalities of @q option, handles parentheses and quotes match at parsing while ignoring the separator within parentheses, as well as handling escaping characters outside quotes.
Below is data in the imported Table sequence:
1.6 Specification of data type and date/time format

By default, values of Phone column will be read as long integers and those of Birthday column as strings. To avoid such errors, we need to specify data type for field values and date/time format.
=file("d:/txt/empinfo.txt").import@t(ID,Name,Phone:string,Birthday:date:"dd/MM/yyyy")
After the field parameters to be read in the above statement, we specify data type for Phone field as string, and that for Birthday field as date and of dd/MM/yyyy format.
1.7 With single quotes, line continuation and escape character

Phone values are single quoted to be converted into strings. The slash \ at the end of the second row enables line continuation, and the escape character \r\n in the last row means that the current Comments value covers two rows.
=file("d:/txt/room.txt").import@tclqa()
@t option enables to import the header row. @c option means comma-separated. @l option (letter l) means a line goes on in the next row and lines should be completely parsed when there is an escape character at the end of the current row. @q option removes quotes from both end of a data item and handles escaping. @a option treats single quotes as quotes when @q option is also present; when @a option is absent, only double quotes are treated in this way.
Below is data in the imported Table sequence:

Right-click the third column in the third row to view the long text as follows:

1.8 Using Excel escaping rule

=file("d:/txt/race.txt").import@tcqo()
The @t option enables to import the header row. @c option means comma-separated. @q option removes quotes from both end of a data item and handles escaping. According to the Excel escaping rule, @o option escapes two quotes as a single pair of quotes and does not escape other characters.
Below is data in the imported Table sequence:
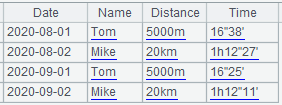
For a CSV file exported from Excel, Tab keys and carriage returns will be written directly to the text file without being escaped and text values will be enclosed within double quotes. If we add Comments column to the above file, it will be imported as follows:

The Comments value in the second row contains a carriage return and four Tab keys. They are displayed as follows when imported:
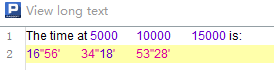
1.9 Error data handling
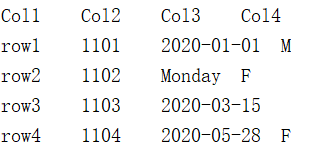
In this file, data type of value in the third column in the second row is wrong and the third row does not have a fourth column.
=file("d:/txt/data.txt").import@tdn()
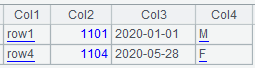
The @t option enables to import the header row. @d option enables deleting a row if it contains data of wrong type or has a different format, or if the parentheses or quotes do not match when @p option or @q option is present. @n option considers it an error if the number of columns in the current row is fewer than that in the first row, and removes it.
Below is data in the imported table sequence, where the original row 2 and row 3 are deleted:
If you want the program to terminate execution of the script and throw exception when @d or @n option detects any errors, just use @v option, as shown below:
=file("d:/txt/data.txt").import@tdnv()
And error is thrown:

Learn more about import() function and cursor functions.
2. Data writing
We open a target text file using file function and write data of a sequence, table sequence or record sequence, which is the result of data processing or computation in SPL, to that file using the export function. For a huge volume of data in a cursor, we read data in batches circularly and append each batch to the target file.
Let’s look at how to write data to a text file in SPL. Suppose we are trying to write data in table sequence A1 to a specific text file.
2.1 With the header rows and tab-separated
=file("d:/txt/scores.txt").export@t(A1)
@t option reads column headers , and the default separator is tab (\t).
=file("d:/txt/scores.txt").export@t(A1,CLASS,Name,English)
The above statement specifies column name parameters to read values from CLASS, Name, and English fields only.
2.2 Without the header row and using user-defined separator
=file("d:/txt/scores.txt").export@c(A1)
The absence of @t option means that the header row won’t be imported and data writing starts from the detail data. @c option means comma-separated.
=file("d:/txt/scores.txt").export@c(A1;"|")
In the above statement, we specify the vertical line "|" as the separator. The specified separator will takes priority and @c option will be ignored.
2.3 Data appending
=file("d:/txt/scores.txt").export@ta(A1)
Here @a option enables appending data at the end of the target file. The appended data should be of same structure as the existing data, otherwise error will be reported. @t option will be ignored when there is data in the target file.
2.4 Using quotes
In order to indicate that the numeric values of a field are strings instead of numbers, we can quote the values when writing them to a file. When values of a file are complicated, such as multirow texts, containing separators or JSON strings, we can also quote them to show that they are field values.
=file("d:/txt/empinfo.txt").export@tcq(A1)
@q option enables quoting string field values and headers at data writing and adding an escape characters, as shown below:

2.5 Using Excel escaping rule
=file("d:/txt/empinfo.txt").export@tco(A1)
Like @q option, the use of @o option also quotes string field values and headers. But it treats two quotes as a single pair of quotes and does not escape other characters according to the Excel escaping rule, as shown below:

Learn more about export() function.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version