

General Operations on Cursors in SPL
After we retrieve data from the data source as a cursor in SPL, we can perform all SQL-style operations on the cursor, such as filtering, aggregation, inter-column calculations, sorting, grouping & aggregation, getting top-N & intra-group top-N, distinct, post-grouping distinct, and join to name a few. According to when the execution begins, there are delayed calculation and immediate calculation. In this essay, we take the large file as data source to explain how to achieve those operations on a SPL cursor.
1. Filtering
A filtering operation selects records that meet the specified condition (s) from a data table.
Example: Get scores of students in class 10 from the following student scores table Students_scores.txt. The first row of the file contains column names, and detailed data begins from the second row, as shown below:
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.select(CLASS==10) |
3 |
=A2.fetch() |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Select records of class 10, which is a delayed calculation.
A3 Fetch desired records from A2’s cursor (Assume the selected records can fit into the memory, otherwise we must specify the number of rows to be fetched at a time), and, until now, the filtering action attached to the cursor begins to be executed.
2. Aggregation
An aggregate operation summarizes data in a table.
Example: Calculate the average Chinese score, the highest math score, and the total English score on all students.
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.total(avg(Chinese),max(Math),sum(English)) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Calculate the average Chinese score, the highest math score, and the total English score, which are immediate calculations.
There are no aggregate functions, such as sum, avg and count, directly performed on a cursor since you can only traverse a cursor once and cannot execute aggregate functions one by one. The total function is used to achieve multiple aggregates on a cursor within one traversal.
3. Inter-column calculations
The inter-column calculation performs a specific operation involving values of multiple columns.
Example 1: Calculate each student’s total score based on the student scores table.
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.derive(English+Chinese+Math:total_score) |
3 |
=A2.fetch(100) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Add a column named total_score to A1, whose values are sums of values in English, Chinese, and Math columns. The derive action is a delayed calculation.
A3 Fetch the first 100 records from A2’s cursor, and, until now, the derive action attached to the cursor begins to be executed.
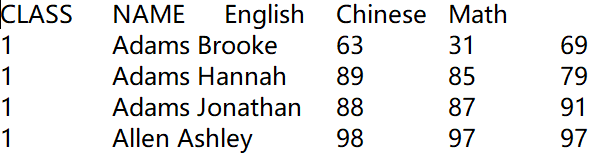
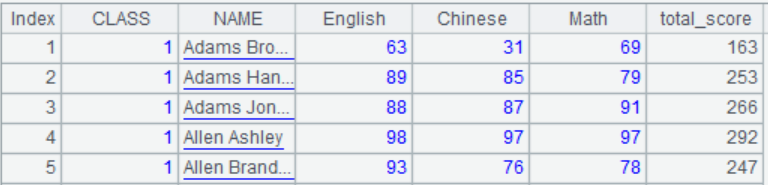
Below is A3’s result:
Example 2: Get the evaluation result for each student’s Chinese score based on the student scores table.
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.derive(if(Chinese>=90:"Excellent",Chinese>=80:"Good",Chinese>=60:"Pass","Fail"):Chinese_evaluation) |
3 |
=A2.fetch(100) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Add a column named Chinese_evaluation to A1, whose values are Excellent, Good, Pass and Fail when the Chinese score is above 90, above 80, above 60 and below 60 respectively. The derive action is a delayed calculation.
A3 Fetch the first 100 records from A2’s cursor, and, until now, the derive action attached to the cursor begins to be executed.
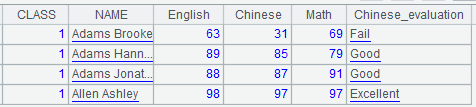
Below is A3’s result, where the computed column Chinese_evaluation is newly-added:
4. Sorting
A sorting operation sorts data in a table in ascending or descending order.
Example: Arrange records in student scores table by class number in ascending order and then by math score in descending order in each class.
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.sortx(CLASS,-Math) |
3 |
=A2.fetch(100) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Sort table by class number in ascending order and then by math score in descending order in each class, and return a cursor. This is an immediate calculation.
A3 Fetch the first 100 rows from A2’s cursor.
5. Grouping & aggregation
A grouping & aggregate operation groups data and then perform a specific aggregate operation on each group.
Example: Query the lowest English score, the highest Chinese score, and the total math score in each class.
1. If grouping result set can fit into the memory
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.groups(CLASS;min(English),max(Chinese),sum(Math)) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Group A1 by class and get the lowest English score, the highest Chinese score, and the total math score in each class. These are immediate calculations.
2. If grouping result set cannot fit into the memory
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.groupx(CLASS;min(English),max(Chinese),sum(Math)) |
3 |
=A2.fetch(100) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Group A1 by class and get the lowest English score, the highest Chinese score, and the total math score in each class, and return a cursor. Those are immediate calculations.
A3 Fetch the first 100 groups from A2’s cursor.
6. Getting top-N
A top-N operation gets the first N records or values meeting a specified condition from a data table.
Example: Get score records of the three students whose English scores rank in top 3.
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.total(top(-3;English)) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Sort A1 by English score in descending order and get records of three students whose English scores rank in top 3. As there isn’t a top function in cursor functions, the same operation need to be performed within the cursor total function and this is an immediate calculation.
7. Intra-group top-N
Group data in a table and then get top-N records or values from each group
Example: Get score records of the three students whose English scores rank in the lowest 3 from each class.
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.groups(CLASS;top(3,English)) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Group A1 by class, sort each class by English score in ascending order, and get the three lowest English scores from each class. The groups function is used when the grouping result set is relatively small to do an immediate calculation. The groupx function is used when the grouping result set cannot fit into the memory to do an immediate calculation, and returns a cursor.
Here the top function uses the comma to separate parameters and return a sequence of top-N values of the sorting expression. When the function uses the semicolon to separate parameters, it returns a sequence of records containing the top-N values the specific field.
8. Distinct & Count distinct
A distinct operation removes duplicates from a data table.
Example: Get all class numbers.
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.groups(CLASS) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Get all unique class numbers from A1, which is an immediate calculation. When the grouping result set is large, use groupx function to perform an immediate calculation and return a cursor.
A count distinct operation eliminates the repetitive appearance of the specific data from a table and perform count.
Example: Calculate the total class numbers.
A |
|
1 |
=file(“E:/txt/Students_scores.txt”).cursor@t() |
2 |
=A1.total(icount(CLASS)) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Count the unique class numbers. This is an immediate calculation.
9. Intra-group count distinct
The operation groups data in a table and count the unique appearances of the specific data in each group.
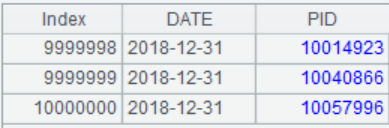
Example: Count dates having sales records for each product based on the following sales table sales.txt.
A |
|
1 |
=file(“E:/txt/sales.txt”).cursor@t() |
2 |
=A1.groups(PID;icount(DATE):days) |
A1 Retrieve data from the specified file as a cursor; @t option reads the first row as column headers.
A2 Group A1 by product number PID, and count unique dates in each group and name the new column days. These are immediate calculations. When the grouping result set is large, use groupx function to perform an immediate calculation and return a cursor.
10. Foreign key association
For two data tables, certain fields in table A associate with table B’s primary key, then table B is called table A’s foreign key table and this association is called foreign key association. The foreign key table should be able to be completely loaded into the memory.
Example: The order information and the product information are stored in two Excel files respectively. We are trying to calculate the sales amount in each order. Data structures of the two files are as follows:
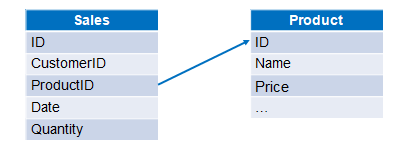
There are two methods to handle the single foreign key association.
Method 1:
A |
|
1 |
=file(“e:/orders/sales.xlsx”).cursor@t() |
2 |
=T(“e:/orders/product.xlsx”).keys(ID) |
3 |
=A1.switch(ProductID,A2:ID) |
4 |
=A3.derive(Quantity*ProductID.Price:amount) |
5 |
=A4.fetch(100) |
A1 Retrieve orders data as a cursor; @t option reads the first row as column headers.
A2 Read product data and set ID as the primary key.
A3 The switch function associates A1’s ProductID with A2’s ID (ID can be omitted if it is the primary key) and the original ProductID values are converted into the corresponding product records. This is a delayed calculation. Below shows part of the data retrieved from A3’s result.
A4 A3 adds a new column named amount, whose values are results of sales quantity Quantity multiplied by product price Price. The expression ProductID.Price means value of Price field in the record pointed by ProductID field. The derive action is a delayed calculation.
A5 Fetch the first 100 rows from A4’s cursor, and until now, the operations attached to the cursor begin to be executed.
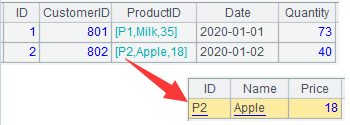
Method 2:
A |
|
1 |
=file(“e:/orders/sales.xlsx”).cursor@t() |
2 |
=T(“e:/orders/product.xlsx”).keys(ID) |
3 |
=A1.join(ProductID,A2:ID,Name,Price) |
4 |
=A3.derive(Quantity*Price:amount) |
5 |
=A4.fetch(100) |
A1 Retrieve orders data as a cursor; @t option reads the first row as column headers.
A2 Read product data and set ID as the primary key.
A3 The join function associates A1’s ProductID with A2’s ID (ID can be omitted if it is the primary key) and introduces Name and Price fields from A2. This is a delayed calculation. Below shows part of the data retrieved from A3’s result.
A4 A3 adds a new column named amount, whose values are results of sales quantity Quantity multiplied by product price Price.
A5 Fetch the first 100 rows from A4’s cursor, and until now, the operation attached to the cursor begins to be executed.

The switch function cannot be used for multi-foreign-key association. Instead, the join function should be used to do that. Suppose the Prices are different for different types of packaging, and we add a Packing field to both the product table and the orders table. Now the product table has a composite primary key of ID field and Packing field. Below are parts of the two tables:

Now we are trying to calculate the amount in each order:
A |
|
1 |
=file(“e:/orders/sales.xlsx”).cursor@t() |
2 |
=T(“e:/orders/product.xlsx”).keys(ID,Packing) |
3 |
=A1.join(ProductID:Packing,A2,Name,Price) |
4 |
=A3.derive(Quantity*Price:amount) |
5 |
=A4.fetch(100) |
A1 Retrieve orders data as a cursor; @t option reads the first row as column headers.
A2 Read product data and set ID, Packing as the primary key.
A3 The join function associates A1’s ProductID and Packing fields with A2’s primary key and introduces Name and Price fields from A2. This is a delayed calculation. Below shows part of the data retrieved from A3’s result.
A4 A3 adds a new column named amount, whose values are results of sales quantity Quantity multiplied by product price Price.
A5 Fetch the first 100 rows from A4’s cursor, and until now, the operation attached to the cursor begins to be executed.
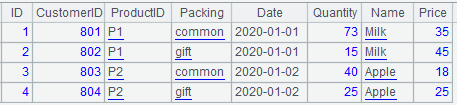
11. Primary key association
For table A and table B associated through their primary keys, they are called homo-dimension tables. The homo-dimension tables have a one-to-one relationship and, logically, can be treated as a single table. Homo-dimension tables are associated via primary keys and their records have a unique correspondence.
There are employee information table (employee.xlsx) and salary table (salary.xlsx). Both use Eid as the primary key. Below are parts of the tables:
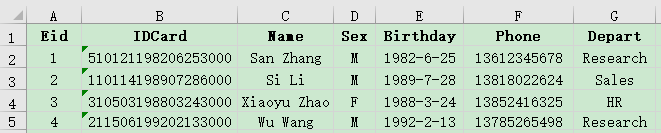
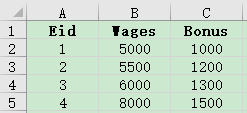
We are trying to get the basic employee information and the corresponding salary information:
A |
|
1 |
=file("e:/work/employee.xlsx").cursor@t().sortx(Eid) |
2 |
=file("e:/work/salary.xlsx").cursor@t().sortx(Eid) |
3 |
=joinx(A1:emp,Eid;A2:salary,Eid) |
4 |
=A3.new(emp.Eid,emp.IDCard,emp.Name,emp.Sex,emp.Phone,emp.Depart,salary.Wages,salary.Bonus) |
5 |
=A4.fetch(100) |
A1 Retrieve employee data as a cursor, where @t option reads the first row as column headers, and sort it by Eid. When the original data is already ordered by EID, jus skip the sortx sorting operation.
A2 Retrieve salary data as a cursor, where @t option reads the first row as column headers, and sort it by Eid. When the original data is already ordered by EID, jus skip the sortx sorting operation.
A3 Join A1 and A2 through Eid, during which A1 is named emp and A2 is named salary. The join action is a delayed calculation. When joinx function is called, the involved cursors must be ordered by the joining field.
A4 Select Eid, IDCard, Name, Sex, Phone and Depart from A3’s emp and Wages and Bonus from A3’s salary to create a new table sequence. This is a delayed calculation.
A5 Fetch the first 100 rows from A4’s cursor, and until now, the operations attached to the cursor begin to be executed.
The primary key association may happen between the main table and the subtable. For table A and table B when the former’s primary table associates with part of the latter’s primary key, then table A is called the main table and table B is the subtable. The main table and the subtable has a one-to-many relationship.
Here is employee family table (family.xlsx) where the primary key is made up of Eid field and Fid field. We are trying to get information of employees who has at least one family member who is above 70.
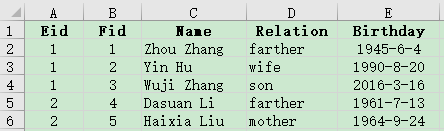
A |
|
1 |
=file("e:/work/employee.xlsx").cursor@t().sortx(Eid) |
2 |
=file("e:/work/family.xlsx").cursor@t().select(age(Birthday)>=70).sortx(Eid) |
3 |
=joinx(A1:employee,Eid;A2:family,Eid) |
4 |
=A3.conj(employee) |
5 |
=A4.fetch(100) |
A1 Retrieve employee data as a cursor, where @t option reads the first row as column headers, and sort it by Eid. When the original data is already ordered by EID, jus skip the sortx sorting operation.
A2 Retrieve family data as a cursor, where @t option reads the first row as column headers, select records where ages are above 70, and sort them by Eid. When the original data is already ordered by EID, just skip the sorting operation.
A3 Perform a filtering join on A1 and A2 through Eid by deleting non-matching records and during which A1 is named employee and A2 is named family. The join is a delayed calculation. When joinx function is called, the involved cursors must be ordered by the joining field.
A4 Get employee column from A3 to concatenate its records as a cursor. This is also a delayed calculation.
A5 Fetch the first 100 rows from A4’s cursor, and until now, the operations attached to the cursor begin to be executed.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_SPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL


Example data file URL: https://img.raqsoft.com.cn/file/2024/07/bc4176c5a69d40fb8e768fed4ac8ab4e_SPL.zip