

How to Parse and Compute XML in Java?
There are three approaches. One is to store XML strings in a database and compute XML in SQL. Its advantage is making the most use of SQL’s computing ability, and there are two disadvantages. SQL, based on two-dimensional structured records, is not good at computing multilevel XML, and has extremely complicated data loading process that results in poor performance. The second is to parse XML using one of the Java libraries, such as XOM, Xerces-J, JDOM and Dom4J and compute XML using XPath syntax. The merit is straightforward and efficient, and demerit is that XPath only supports conditional queries and aggregate operations and all the other computations need to be hardcoded.
The third and best approach is to use esProc SPL, an open-source Java library, to parse and compute XML directly. SPL has data object intended for processing data of multilevel structure, enabling much simpler multilevel XML handling, and functions and syntax possessing great computational capabilities, remarkably facilitating the implementation of complex computational logic.
SPL provides convenient JDBC driver that is easy to use even for beginners. Here’s one example. We have a two-level XML file where each <row> field stores employee records and each <Orders> field of employee records stores orders records, and we are trying to parse it into the SPL table sequence object. Below is the code:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str="=xml(file(\"D:/data.xml\").read(),\"xml/row\")";
ResultSet result = statement.executeQuery(str);
…
The multilevel structure is intrinsic to an SPL table sequence, making SPL the one suitable for computing multilevel XML by effectively reducing code complexity. To perform a conditional query on all employees’ all orders to find orders records where amounts fall within a specified range and client names contain a specified string, for instance, we have the following SPL code:
=xml(file("D:/data.xml").read(),"xml/row").conj(Orders).select((Amount>1000 && Amount<=2000) && like@c(Client,"\*business\*"))
The SPL code can be separated from Java code and stored independently, making it unnecessary to recompile it whenever it is changed and substantially decoupling it from the Java code. So, we can save the above code for achieving conditional query as a SPL script file:
A |
|
1 |
=xml(file("d:/data.xml").read(),"xml/row") |
2 |
=A1.conj(Orders) |
3 |
=A2.select(Amount>100 && Amount<=3000 && like@c(Client,"*bro*")) |
As we call a stored procedure, we just need to reference it by file name when invoking it in Java:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str="call condition()";
ResultSet result = statement.executeQuery(str);
…
SPL has a wealth of built-in library functions to provide equal computing abilities as SQL. Here are some examples:
A |
||
2 |
…. |
|
3 |
=A2.conj(Orders).groups(Client;sum(Amount)) |
Grouping & aggregation |
4 |
=A2.groups(State,Gender;avg(Salary),count(1)) |
Grouping & aggregation by multiple fields |
5 |
=A2.sort(Salary) |
Sorting |
6 |
=A2.id(State) |
Distinct |
7 |
=A2.new(Name,Gender,Dept,Orders.OrderID,Orders.Client,Orders.Client,Orders.SellerId,Orders.Amount,Orders.OrderDate) |
Join |
With its rich functions and agile syntax, SPL can implement algorithms with complex logic with rather simple code that are hard to achieve using SQL or stored procedure. To calculate the largest number of days when a stock rises in a row, for instance, SPL only needs two lines of code:
A |
|
1 |
=xml(file("d:/share.xml").read(),"xml/row") |
2 |
=a=0,A1.max(a=if(price>price[-1],a+1,0)) |
SPL supports retrieving XML from HTTP or WebService through a simple and easy to understand interface. To retrieve stock Webservice description file, query a specified stock’s closing prices according to the descriptions, and calculate the largest number of days when a stock rises continuously, for instance:
A |
|
1 |
=ws_client("http://.../shareWebService.asmx?wsdl") |
2 |
=ws_call(A1,"shareWebService":"shareWebServiceSoap":"AAPL") |
3 |
=a=0,A1.max(a=if(price>price[-1],a+1,0)) |
SPL has a special IDE boasting a complete set of debugging functionalities and letting users to observe the result of each step, for implementing algorithms with complex logics:
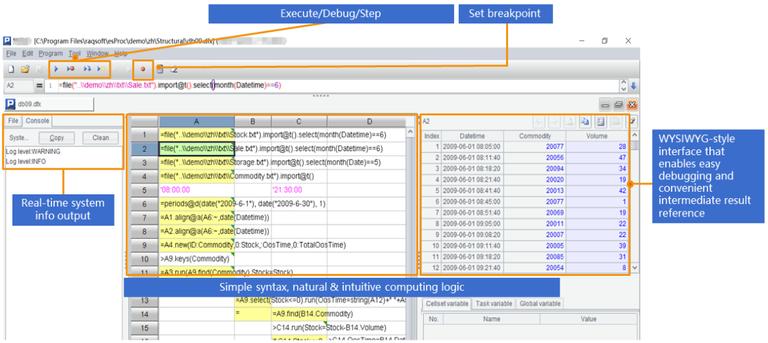
With its exceptional computational capabilities, SPL can often simplify the process for computing multilevel XML. For instance, we have book1.xml that stores information of a number of books where each book has more than one author. Below is part of its data:
<?xml version="1.0"?>
<library>
<book category="COOKING">
<title>Everyday Italian</title>
<author name="Giada De Laurentiis" country="it" />
<year>2005</year>
<info>Hello Italian!</info>
</book>
<book category="CHILDREN">
<title>Harry Potter</title>
<author name="J K. Rowling" country="uk"/>
<year>2005</year>
<info>Hello Potter!</info>
</book>
<book category="WEB">
<title>XQuery Kick Start</title>
<author name="James McGovern" country="us" />
<author name="Per Bothner" country="us"/>
<year>2005</year>
<info>Hello XQuery</info>
</book>
<book category="WEB">
<title>Learning XML</title>
<author name="Erik T. Ray" country="us"/>
<year>2003</year>
<info>Hello XML!</info>
</book>
</library>
We are trying to rearrange the XML file as a two-dimensional table where the Author field will be displayed in the specified format. Below is the desired result:
title |
Category |
year |
Author |
info |
Everyday Italian |
COOKING |
2005 |
Giada De Laurentiis[it] |
Hello Italian! |
Harry Potter |
CHILDREN |
2005 |
J K. Rowling[uk] |
Hello Potter! |
XQuery Kick Start |
WEB |
2005 |
James McGovern[us],Per Bothner[us] |
Hello XQuery |
Both the source XML and the result two-dimensional table are complicated, and the processing will be rather difficult. Yet it becomes simple with SPL:
A |
|
1 |
=file("D:\\xml\\book1.xml") |
2 |
=xml@s(A1.read(),"library/book").library |
3 |
=A2.new(category,book.field("year").ifn():year,book.field("title").ifn():title,book.field("lang").ifn():lang,book.field("info").ifn():info,book.field("name").select(~).concat@c():name,book.field("country").select(~).concat(","):country) |
4 |
=A3.new(title,category,year,(lang,name.array().(~+"[")++country.array().(~+"]")).concat@c():author,info) |
5 |
=A4.select(year==2005) |
In short, SPL can directly parse and compute XML coming from both files and WebService without loading data into the database, and can remarkably simplify the computing process and the expression of complex logic.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

