

SPL Programming - 8.2 [Data table] Table sequence and record sequence
With the basic concept of structured data, let’s learn how to process this data, that is, the second half of the book mentioned in the preface.
Among the programming languages used to process structured data, SQL is the most widely used at present. The full name of SQL is structured query language, which means the language specially used for structured data query. It is the common language of relational database.
Except for SQL related materials, most programming books do not talk about structured data. After talking about the content equivalent to the first half of this book, they begin to turn to more advanced object-oriented content. For non professionals, this book can be said to have ended. However, learning to this level, except for doing some math problems of primary and secondary schools (just like the examples mentioned above) to practice our brains, it will not be of any substantive help to our daily work. Only after learning the knowledge and skills of structured data can we really use programming to improve work efficiency, which is also an important goal of this book.
However, this book is not going to talk about SQL. There are a lot of materials in this area. If readers are interested, you can learn it yourself. SQL usually can only be used in the database, and the skill requirements for installing and adminstrating a database are a bit high, which is not suitable for the readers of this book.
We continue to use SPL. Compared with SQL, SPL has much richer structured data processing capabilities. In most cases, the code is more concise than SQL, and the environment does not rely on the database, which is more suitable for non professionals.
In fact, the full name of SPL is structured process language, which is also invented to process structured data. Structured data is very common. Most data processing tasks in daily work are related to structured data, and it is necessary to invent a more efficient program language.
Actually, SQL is allowed to be used for file data in esProc. The basic SQL function is realized as a special statement of SPL. You can also learn SQL with esProc without installing the database.
Back to the subject, let’s first look at how to create a data table.
| A | |
|---|---|
| 1 | =create(name,sex,weight,height) |
The create()function creates an empty data table. The data table must have a data structure, that is, field names, and fill them in the parameters of the create() function in turn. The newly created data table has no records. When viewing the data, we will see that there is only a header on the right.

Let’s write the code more completely and add some data.
| A | B | C | D | |
|---|---|---|---|---|
| 1 | Zhang San | Male | 80 | 1.75 |
| 2 | Li Si | Male | 60 | 1.68 |
| 3 | Wang Hua | Female | 51 | 1.64 |
| 4 | Zhao Ting | Female | 49 | 1.6 |
| 5 | =create(name,sex,weight,height) | =A5.record([A1:D4]) | ||
Create a data table in A5, and then use the record()function to fill in the data in C5. We talked about the writing method of [A1:D4] earlier. The record()function is used to fill the members of the sequence(parameters) into the data table as field values. The sequence members will be filled in according to the field order in the data structure. After filling in a record, if there are remaining sequence members, a new record will be created for the data table to continue to fill in the remaining sequence members.
Now view the data (the record function still returns the data table. To view A5 or C5 is the same).
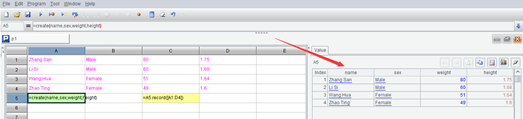
This looks very similar to the sequence values, only that a sequence is displayed as one column, and the data table is displayed as multiple columns, and each column has a name (field name). esProc will also automatically display an index column on the left to faciliate counting. It seems to be a more complex sequence?
We can indeed understand the data table in SPL as a sequence with records as members (it is still a little different, and we’ll talk about it later). In fact, the formal name of the data table in SPL is table sequence, because SPL places great emphasis on the order of records in the table. For people who are used to Excel, it is natural for records (that is, rows) to have order; But for database programmers, the records in the data table are orderless. SPL emphasizes order to distinguish it from SQL.
A data table is called a table sequence, but records are still records and fields are also fields.
Since a table sequence is a sequence composed of records, can records be obtained by referencing members in the sequence?
Yes, we can continue to write the code:
| A | B | C | D | |
|---|---|---|---|---|
| … | … | … | … | … |
| 5 | =create(name,sex,weight,height) | =A5.record([A1:D4]) | ||
| 6 | =A5(1) | =A5(3) | =A5.m(-1) | =A5.len() |
Look at the value of A6 after execution:

It is still displayed as a table with header, but there is only one row of data, and there is no index column on the left.
This is a record. It has a data structure (that is, the data structure of the table sequence), i.e., fields. Each of its fields has a value, which is listed above.
A5 is really like a sequence. It can correctly execute code such as A5.m(-1), and A5.len() is OK.
Let’s study the record. Can we get the field value of the record to participate in the operation? Continue writing:
| A | B | C | D | |
|---|---|---|---|---|
| … | … | |||
| 6 | =A5(1) | =A5(3) | =A5.m(-1) | |
| 7 | =A6.weight/A6.height*A6.height | |||
| 8 | >output(if(B6.height>C6.height,B6.name,C6.name) + "is taller") | |||
Use the . operator followed by the field name to get the field value. The BMI of the first person Zhang San is calculated in A7, and the height of the third and fourth person is compared in A8, and the name of the taller person is displayed.
Can we change the field value? it’s OK too.
| A | B | C | D | |
|---|---|---|---|---|
| … | … | |||
| 6 | =A5(1) | =A5(3) | =A5.m(-1) | |
| 7 | =A6.weight/A6.height*A6.height | |||
| 8 | >output(if(B6.height>C6.height,B6.name,C6.name) + "is taller") | |||
| 9 | =C6.height=1.8 | =A5(4).name=“NewZhaoTing” | ||
| 10 | >output(if(B6.height>C6.height,B6.name,C6.name) + "is taller") | |||
Field values can be referenced and modified by using the extracted record variable (C6) and the direct table sequence member (A5(4)).
For the field F of record r, r.F is equivalent to a variable with slightly complex name, which can be freely referenced in the expression or assigned.
We can see that in SPL, we can get a record from the table sequence to view and calculate separately. Don’t take this for granted. This is not allowed in SQL. A SQL record cannot be calculated independently outside the data table.
Review the object concept we talked about earlier. Complex data types are not stored directly in variables, but only one address. A record has multiple fields, which seems a little complex. Is it the same?
| A | B | C | D | |
|---|---|---|---|---|
| … | … | |||
| 6 | =A5(1) | =A6 | =A5(1) | |
| 7 | >A6.name=“Test” | =B6.name | =C6.name | |
Just do some experiments. The record is also an object. Not only the address of the record is stored in the record variable, but also in the table sequence without copying the record value. Modifying the field value of a record will affect all subsequent codes that reference this record field.
As for the table sequence, it is obviously an object.
Moreover, a record has more special features:
| A | B | C | D | |
|---|---|---|---|---|
| 1 | Zhang San | Male | 80 | 1.75 |
| 2 | Li Si | Male | 60 | 1.68 |
| 3 | Wang Hua | Female | 51 | 1.64 |
| 4 | Li Si | Male | 60 | 1.68 |
| 5 | =create(name,sex,weight,height) | =A5.record([A1:D4]) | ||
| 6 | =A5(1)>A5(2) | =A5(2)==A5(4) | =A5(2)>A5(4) | |
We deliberately fill the data in row 4 and row 2 exactly the same, and then observe the calculation results of the three logical expressions in row 6.
The results of A6 and C6 are unpredictable, and multiple executions may get different results. B6 is always false.
What’s going on?
The fields of a record are not always the same kind of things like the members of a sequence. It is usually meaningless to use the field order to compare two records. For example, the name field precedes sex here, but there is no reason that name should take precedence over sex in comparison. However, it is not necessary to return an error, so SPL specifies that the internal address value is used for record comparison, so A6 and C6 will get unpredictable results. As for two records of the same table sequence, even if the contents are exactly the same, they will be allocated memory space respectively, and their address values are also different, so the two different records will never be equal.
Then, what can we do if we just want to compare whether the field values of two records are equal, or we just want to compare the records according to the field order?
SPL provides special functions for such comparison:
| A | B | C | D | |
|---|---|---|---|---|
| 1 | Zhang San | Male | 80 | 1.75 |
| 2 | Li Si | Male | 60 | 1.68 |
| 3 | Wang Hua | Female | 51 | 1.64 |
| 4 | Li Si | Male | 60 | 1.68 |
| 5 | =create(name,sex,weight,height) | =A5.record([A1:D4]) | ||
| 6 | =cmp(A5(1),A5(2)) | =cmp(A5(2),A5(4)) | ||
We’ll get a definite result now. The difference is that the cmp() function does not return true or false, but an integer. If it is equal, it returns 0; If the former is smaller, it returns -1; If the former is larger, it returns +1. There are three cases in a comparison.
Why doesn’t SPL directly stipulate the comparison of records as the calculation result of cmp() function?
Comparing the records according to the rules of cmp()function is not a common operation. It doesn’t matter if it’s a little troublesome. Comparing whether the address stored in a record variable is the same (to determine whether it is physically the same record) is a relatively common operation, which is often performed implicitly (such as the grouping operation to be discussed later). If the record comparison is stipulated as the result of cmp() operation, the action of comparing addresses will be much more troublesome or inefficient. Therefore, the SPL convention of the current rule is the result of weighing the computational efficiency and code complexity.
A table sequence is like a sequence composed of records. Can we use the insert()and delete() functions to add and delete members like a sequence?
delete()is OK, but insert() is different. This is the key difference between a sequence and a table sequence.
As we said, a data table has only one set of data structure. When adding a record to the table sequence, it must be a record with the same data structure. If it is allowed to grab a record and insert it into the table sequence, we need to check it in detail to avoid this situation. Moreover, this may cause a record to belong to two different table sequences. When one table sequence adjusts the data structure for some reason, it may lead to the inconsistency of the data structure in the other table sequence. This is too troublesome and seriously affects the efficiency of the program.
Therefore, SPL stipulates that a record must be generated from a table sequence and cannot be inserted into other table sequences. In this way, the records of a table sequence are all under the control of the table sequence. There will be no record that comes to another table sequence, and there will be no record that comes from others. Therefore, we will find that SPL provides a function to create a table sequence, but there is no function to create a separate record. After a record is created, it can participate in other operations outside the table sequence, but it must be attached to a table sequence when it is created. A single record created is essentially a record in a table sequence with only one record. This table sequence can continue to insert new records.
This can also explain the above: different records will never be equal.
The insert() function of the table sequence is made as follows:
| A | B | C | D | |
|---|---|---|---|---|
| … | … | … | … | … |
| 5 | =create(name,sex,weight,height) | =A5.record([A1:D4]) | ||
| 6 | >A5.insert(0,“Mary”,“Female”,55,1.7) | |||
| 7 | >A5.insert(2,“John”,“Male”,75,1.8) | |||
The first position parameter of insert() has the same meaning as that of sequence insert. A record can be inserted in the middle or appended at the end. Then write each field value of the record to be inserted in the remaining parameters. SPL will create a new record in the appropriate position of the table sequence and fill in the field value.
The purpose of assembling members into a sequence, that is, a set, is to facilitate operation and processing together, for example, we can use the loop function mentioned above. If the records of the table sequence must exist in the table sequence, can the records of different table sequences be put together for operation? Moreover, even if it is the same table sequence, not all the members may participate in the operation at one time, and a sequence has a method to get a subsequence. Is this still valid for the table sequence?
These operations are allowed in SPL. Records are only attached to the table sequence when they are created to ensure the consistency of their data structure. Once created, they can be referenced and combined freely like ordinary data.
It is very common for a sequence composed of a batch of records from different table sequences, or a sequence composed of partial records of a table sequence. This sequence has a special name in SPL called record sequence.
Of course, a record sequence is also an object.
For the loop functions of table sequence and record sequence, we will talk about them later. Now we will manually create several record sequences:
| A | B | C | D | |
|---|---|---|---|---|
| … | … | … | … | … |
| 5 | =create(name,sex,weight,height) | =A5.record([A1:D4]) | ||
| 6 | =A5.to(2,) | =[A6(1),A5(4),A5.m(-1)] | =A5.step(2,2) | |
| 7 | =A6.len() | =B6(2)==B6(3) | =C6(1)==A6(1) | |
At present, we have only one table sequence at hand, and can only create record sequences composed of the records of this table sequence. Note B6 that the member of a record sequence can be referenced from another record sequence, not necessarily directly from the table sequence. Moreover, its members can be repeated, and B7 will calculate true; The members of the table sequences cannot be equal to each other because they are newly created every time; while different record sequences can of course be composed of the same record, and C7 also calculates true.
A record sequence can be understood as an ordinary sequence, because it may have same members, and the set operations are also meaningful:
| A | B | C | D | |
|---|---|---|---|---|
| … | … | … | … | … |
| 5 | =create(name,sex,weight,height) | =A5.record([A1:D4]) | ||
| 6 | =A5.to(2,) | =[A6(1),A5(4),A5.m(-1)] | =A5.step(2,2) | |
| 7 | =A6&B6 | =A6^C6 | =A5\C6 | |
The result of these set operations is still a record sequence, and the table sequence itself can be regarded as a record sequence composed of all its records, and can also participate in these set operations, but the calculation result will no longer be a table sequence, but just a record sequence.
Now let’s do the problem of merging Excel again, since we haven’t learned to change the data structure, we reduce one requirement: only merge the data without adding the file name to the end.
| A | B | |
|---|---|---|
| 1 | =directory@p(“data/*.xlsx”) | |
| 2 | for A1 | =file(A2).xlsimport@t() |
| 3 | =@|B2 | |
| 4 | =file(“all.xlsx”).xlsexport@t(B3) | |
We have understood A1. This time, B2 uses the xlsimport()function without @w, which will read the file into a table sequence, @t indicates that the first row of the file is the field names of the table sequence. B3 in the loop body concatenates the table sequences read each time, which will form a sequence composed of records from multiple table sequences, that is, a record sequence composed of records from multiple table sequences. After the concatenation, just write it in A4 with xlsexport() function, @t also means to write the field names to the first row as the title.
This code is much simpler than the previous string processing, and there is no need to deal with the disassembly and assembly of the title. In fact, using loop function can be simpler:
| A | |
|---|---|
| 1 | =directory@p(“data/*.xlsx”).(file(~).xlsimport@t()).conj() |
| 2 | >file(“all.xlsx”).xlsexport@t(A1) |
Multiple record sequences can also form a two-layer sequence, and then concatenate into one using conj() function.
This code requires that the merged Excel files have the same data structure (i.e. the same columns). In fact, a record sequence does not require that all member records have the same data structure. There will be no problem as long as there is no error when referencing fields. However, this situation is very rare, and we won’t give an example.
SPL Programming - Preface
SPL Programming - 8.1 [Data table] Structured data
SPL Programming - 8.3 [Data table] Generation of table sequence
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL

