

SPL Programming - 9.4 [Grouping] Expansion and transpose
After grouping and then summarizing, we usually get a smaller set than the original set, which is equivalent to aggregation. Then, is there an inverse operation of grouping, using a smaller data table to calculate a larger data table through some rules?
We call this kind of operation expansion or inverse grouping.
However, the summarized data generally has lost the detailed information, and the reverse calculation cannot be realized. Explicit expansion rules are required for expansion operations.
The table sequence contains loan information of some customers, including loan periods and amounts. Now we need to calculate the monthly repayment amount of these people according to the equal principal and interest method, and the interest rate is a constant.
| A | B | |
|---|---|---|
| 1 | =10.new(string(~):id,rand(20):number,rand(100):amount) | >rate=0.05/12 |
| 2 | =A1.news(number;id,month@y(elapse@m(now(),#)):ym,amount*(1-rate*power(1+rate,number)/power(1+rate,number)):payment) | |
The news() function in A2 will generate number records for each member of A1. The field name and calculation formula are described by the following parameters. The calculation formula of this installment loan is copied online. It’s not the point.
Think about the # in the parameters. The news() function is essentially a two-layer loop function. First, it loops through the members of A1, and then it loops through the first parameter number. The parameters after the semicolon are actually for the inner loop function, that is, # is for the number layer, i.e., the number of loans, not the member of A1.
The calculation amount of this code is a little large. Because the monthly repayment amount is actually the same in the equal principal and interest method, there is no need to calculate it so many times. Just calculate it once for each A1 member.
| A | B | |
|---|---|---|
| 1 | … | … |
| 2 | =A1.(amount*(1-rate*power(1+rate,number)/power(1+rate,number))) | |
| 3 | =A1.news(number;id,month@y(elapse@m(now(),#)):ym,A2(A1.#):payment) | |
Note that A1.# is used here to refer to the sequence number of the outer loop function.
Let’s implement the inverse operation of string merging in the previous section.
| A | |
|---|---|
| 1 | =100.new(string(~):name,if(rand()<0.5,“Male”,“Female”):sex) |
| 2 | =A1.group(sex;~.(name).concat@c():Names) |
| 3 | =A2.news(Names.split@c();~:name,sex) |
A3 will split the string concatenated in A2 and expand it into records with the same number of rows as A1.
Again, news() is essentially a two-layer loop function. The sex in the parameters is the field of the outer loop function. Because this field cannot be found in the inner layer, SPL will automatically find it in the outer layer, so we don’t have to write A2.sex. And ~ is the current member of the inner loop function, i.e., the name after splitting.
There is also a more common expansion operation: expand the columns (fields) of the data table into rows (records).
We need to use the student score table we used before:
| A | |
|---|---|
| 1 | [English,Maths,Science,Arts,PE] |
| 2 | =A1.(“rand(100):”+~).concat@c() |
| 3 | =100.new(string(~,“0000”):id, ${A2}) |
A3 will generate a data table with 6 fields. Except for the id field, the others are all one subject (score of one subject).
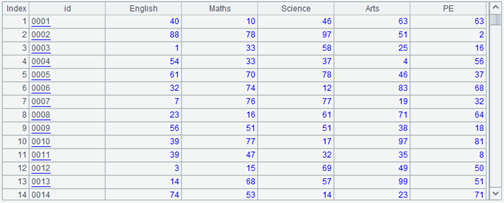
When we talked about the concept of structured data, we mentioned that since these subjects are of equal status, statistics on these subjects (scores) may occur. Therefore, the more common data structure will be three fields: id, subject, score. Now the field name of the data table will become the field value of the subject field of the new data table, and each record of the original table will become 5 records (there are 5 subjects) of the new table, which leads to expansion operation.
We can write it with news():
| A | |
|---|---|
| … | … |
| 4 | =A3.fname().to(2,) |
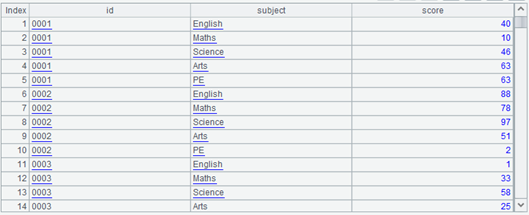
| 5 | =A3.news(A4;id,~:subject,A3.~.field(~):score) |
A4 lists all subject fields, and A5 performs the expansion operation. Note the two ~ in A3.~.field(~), the former is A3.~, i.e., the current record of A3, that is, the record being expanded, and the latter ~ is A4, i.e., a subject field.
Now A5 becomes such a data structure:
This kind of operation is very common, and SPL provides a special function to handle it:
| A | |
|---|---|
| … | … |
| 4 | =A3.fname().to(2,) |
| 5 | =A3.pivot@r(id;subject,score;${A4.concat@c()}) |
For this case where all fields except id need to be expanded, it can be further simplified as:
| A | |
|---|---|
| … | … |
| 4 | =A3.pivot@r(id;subject,score) |
Careful readers may find that the pivot() function uses an @r option, so what will be calculated without the @r option?
When there is no @r, it is its inverse operation, which is equivalent to grouping.
| A | |
|---|---|
| … | … |
| 4 | =A3.pivot@r(id;subject,score) |
| 5 | =A4.pivot(id;subject,score) |
We will find that A5 becomes A3 again, but the field order has changed, and the subject fields are arranged in alphabetical order, however there is no problem with the data. If we want to follow the original field order, we need to write the field list into the parameter:
| 5 | =A4.pivot(id;subject,score;${A1.concat@cq()}) |
concat() plus @q means to spell additional quotation marks, and it will be explained later.
pivot() function is also called transpose operation, and with @r it is called inverse transpose.
Transpose is a variant of grouping operation, which can also be realized by grouping:
| A | |
|---|---|
| … | … |
| 4 | =A3.pivot@r(id;subject,score) |
| 5 | =A4.id(subject) |
| 6 | =A4.group(id;${A5.(“~.select@1(subject==\”“+~+”\“).score:”+~).concat@c()}) |
It can be seen that A6 here also changes back to A3 (the subject fields are also sorted. If the original order is to be used, replace A5 with A1 in the A6 expression).
The macro in A6 expression is complex, but it can be understood through careful study, that is, take the score with the same subject name in the current grouping subset as the value of the subject field in the table sequence after grouping. Because the subject is a string in A4 and the grouping subset is composed of records in A4, quotation marks should also be added during comparison. The same principle is used in the previous code using pivot, so the @q option should be added in concat(). This syntax is really troublesome, so SPL provides the pivot() function to directly implement this grouping and summary.
In other words, transpose is just a grouping and summary operation; Accordingly, inverse transpose is the expansion operation.
It should be emphasized that this transpose is different from the transpose in Excel. The transpose in Excel is equivalent to the transpose of matrix, which is a simple row column exchange (row to column, column to row). The transpose here is actually a pivot in multidimensional analysis. It is an extended variant of grouping operation (inverse transpose is a variant of inverse grouping). Usually, a field is used as a grouping key, and this field is stable and will not be transferred into a column. Transpose is actually a common saying that refers to pivot in the context of this book.
However, the transpose of SPL is slightly different from the ordinary grouping. As can be seen from the expression of A6, it will not aggregate the grouping subset, but simply get the first item. In fact, this operation assumes that there is only one record (or none) in each grouping subset after filtering with the field name of the target table. If there are multiple records at this time (theoretically possible), the pivot()function has no place to describe how to aggregate these records. A better way is to do a round of group aggregation in advance, and then do the pivot() function.
| A | |
|---|---|
| 1 | [English,Maths,Science,Arts,PE] |
| 2 | =100.new(string(rand(10),“0000”):id, A1(rand(5)+1):subject,rand(100):score) |
| 3 | =A2.pivot(id;subject,score) |
| 4 | =A2.groups(id,subject;sum(score):score) |
| 5 | =A4.pivot(id;subject,score) |
| 6 | =A2.pivot@s(id;subject,sum(score)) |
The table sequence we generated in A2 has duplicate id and subject, so that the grouping subset will have multiple records after being filtered by the field name during pivot(). Direct pivot() may not get the desired result (A3); A round of group aggregation (A4) needs to be done first, and then pivot()(A5); If the aggregation method of all fields is the same, it can also be simplified as A6. The option @s indicates that one more step of aggregation is required, and the aggregate function is written in the parameter. If it is different (for example, some calculate sum and some calculate max), we can only do the aggregation of A4 first.
It is very convenient to use the pivot()function without the third segment parameter (after the second semicolon), but some desired fields in the result table sequence may not be generated due to the lack of data.
| A | |
|---|---|
| 1 | [English,Maths,Science,Arts,PE] |
| 2 | =100.new(string(~,“0000”):id, A1(rand(5)+1):subject,rand(100):score) |
| 3 | =A2.select(subject!=“Arts”) |
| 4 | =A3.pivot(id;subject,score) |
| 5 | =A3.pivot(id;subject,score;${A1.concat@cq()}) |
A3 filter out the Arts subject and then do pivot(). The result will be one less column, and there will be no Arts subject. To forcibly list all subjects according to A5, the corresponding values of the field with missing data in the result table sequence will be filled with null.
SPL Programming - Preface
SPL Programming - 9.3 [Grouping] Order-related grouping
SPL Programming - 10.1 [Association] Primary key
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

