

The Open-source SPL Optimizes Report Application and Handles Endless Report Development Needs
Reporting tools are now mostly used for building reports within applications. A mature reporting tool provides a lot of visualization configurations, a wealth of chart types, and various other functionalities, including export and print, making report development convenient and simple. In real-world situations, however, there is a certain thorny problem at a deep level during the report development process that bothers even reporting tool veterans much.
Why do reporting tools have these problems?
It appears that report development is to present data as a table or chart (graph) in a specified layout, which is reporting tools good at. Yet, the original data is not always suitable for being presented directly. Often it needs some complicated processing, which is known as the data preparation phase.
Reporting tools – as the name shows – are intended for generating reports instead of handling data preparation. On the face of it, it is fair to shirk a job above and beyond duty. The fact is that a neglected problem will not automatically disappear and, in the end, it must be dealt with. Another fact is that, in the absence of a convenient tool, reporting tools still implement data preparations in the primitive way of hardcoding. Hundreds of thousands of lines of SQL, dozens even hundreds of KBs’ stored procedures and a great deal of Java code are jammed in the reporting tool behind the report.
A rudimentary tool results in inefficiency, seriously slowing down the overall report development process, which is the source of the developers’ headache. The problem hasn’t gained enough attention from reporting tool vendors and remained until now, with no signs of useful solutions on the horizon.
Data preparation is to report development as roots to trees. Without nurturing the root, it would be useless even if the most resources were invested in taking care of branches and leaves.
The open-source SPL will significantly improve the situation, extremely reducing data preparation difficulty.
SPL (Structured Process Language), the special open-source structured data computing engine, offers a wealth of class libraries, supports procedural computations, and excels at handling various complicated computing scenarios. The language has an open computing system that supports diverse data source mixed computations and hot swap and that provides the standard JDBC interface to be seamlessly integrated into the reporting tool.
Simplifying report development process
There are two phases of report development:
Report data source preparation constitutes the first phase, where the original data is prepared and converted into a data set that feeds data to the future report through the SQL statement, stored procedure or Java code. The second phase is to write expressions based on the prepared data for data presentation or visualization.
It has always been easy for a reporting tool to accomplish data presentation/visualization. The advancement of data visualization techniques in recent years enables presenting more and more reports in charts and graphs, which makes report presentation even simpler.
By contrast, the data preparation techniques have remained elementary. A rough estimate shows that, with reporting tools, data presentation/visualization can take up as low as 20% of the total workload and the rest 80%, or even higher, is given to data preparation. In view of this, it is the report data source preparation phase that needs to be optimized in order to increase the report development efficiency.
SQL (including stored procedures) and Java are the main tools for data preparation these days. Java is more inconvenient because it lacks structured data computation class libraries and isn’t the special set-oriented language. The SQL statement is also very complicated when dealing with complex computations due to its lack of stepwise coding mechanism. SQL, as it is can only work through databases, turns to Java when source data is not stored in RDBs. Besides, frameworks where the front-end and the back-end are separated and microservices architecture require that Java hardcoding be used on the application side. All these factors add reporting tools’ data preparation workload and reduce report development efficiency.
The open-source SPL can help facilitate the data preparation process or just replace SQL and Java. With its concise syntax and rich class libraries, SPL is able to achieve data preparation fast and decrease the report development workload.
SPL offers rich class libraries:
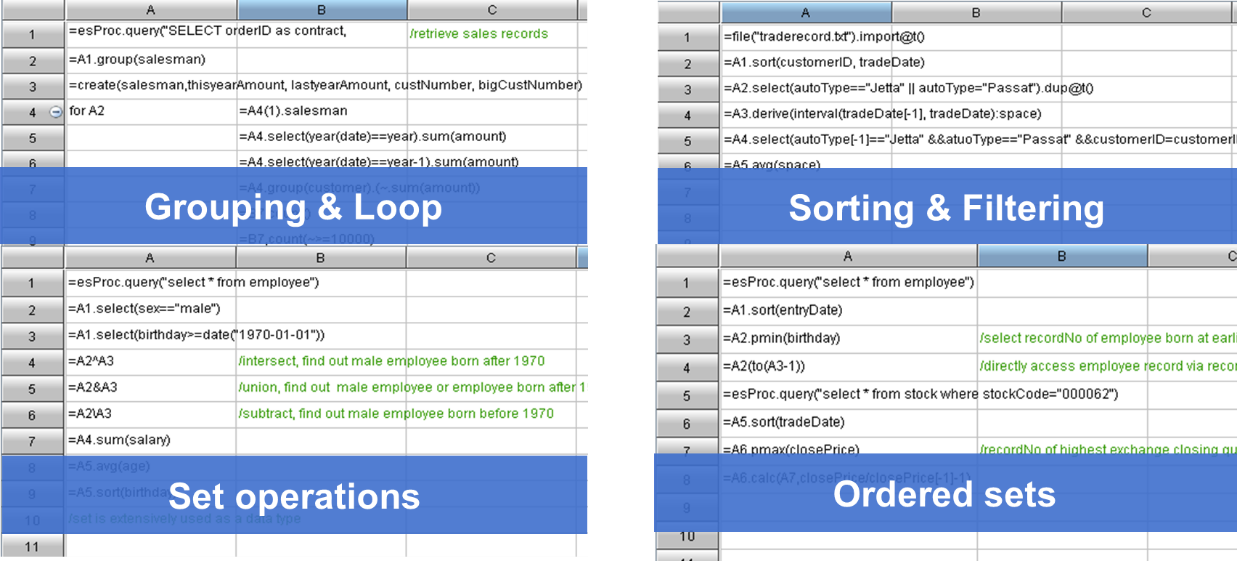
Unlike SQL, SPL employs stepwise coding to achieve an algorithm in the natural way of thinking step by step, generating much simpler statements (complicated SQL is hard to write and maintain).
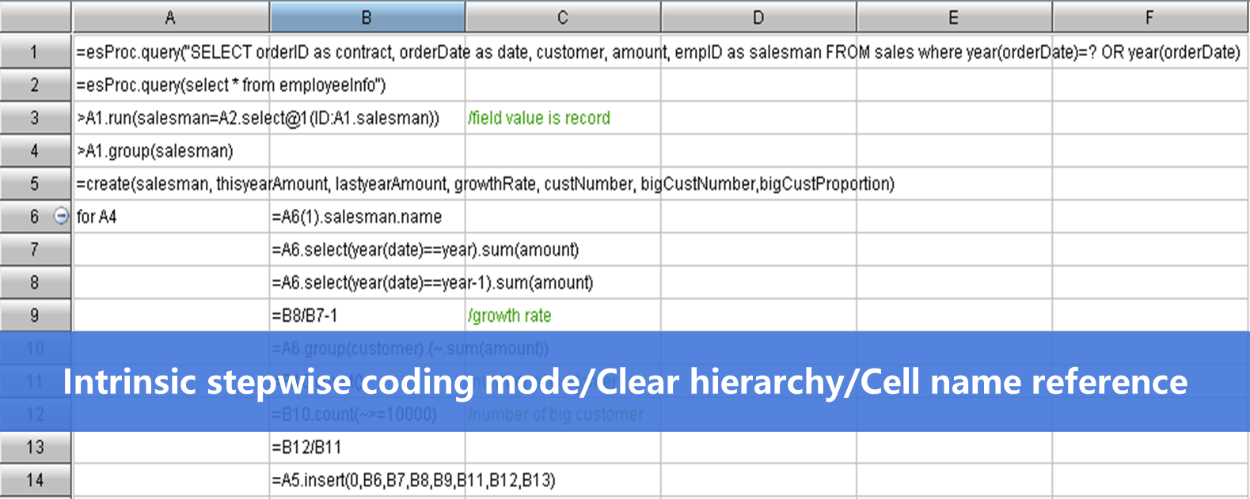
Now let’s make a comparison between SPL and SQL (Java computations are too complicated to be compared).
Query task: Find stocks whose prices rise for five days in a row and count their rising days according to the stock table (same prices are treated as rising).
SQL needs a triple-layered subquery to accomplish the task:
select code,max(risenum)-1 maxRiseDays from
( select code,count(1) risenum from
(
select code,changeSign,sum(changeSign) over(partition by code order by ddate) unRiseDays from
(
select
code,
ddate,
case when price>=lag(price) over(partition by code order by ddate)
then 0 else 1 end changeSign
from stock_record
)
)
group by code,unRiseDays
)
group by code
having max(risenum) > 5
While the SPL code for doing this is much simpler:
A |
||
1 |
=connect@l("orcl").query@x("select * from stock_record order by ddate") |
|
2 |
=A1.group(code) |
|
3 |
=A2.new(code,~.group@i(price |
Count the consecutively rising days for each eligible stock |
4 |
=A3.select(maxrisedays>=5) |
Get eligible records |
SPL has simple and easy-to-use development environment that offers a series of features, such as step and set breakpoint and WYSIWYG viewing pane.
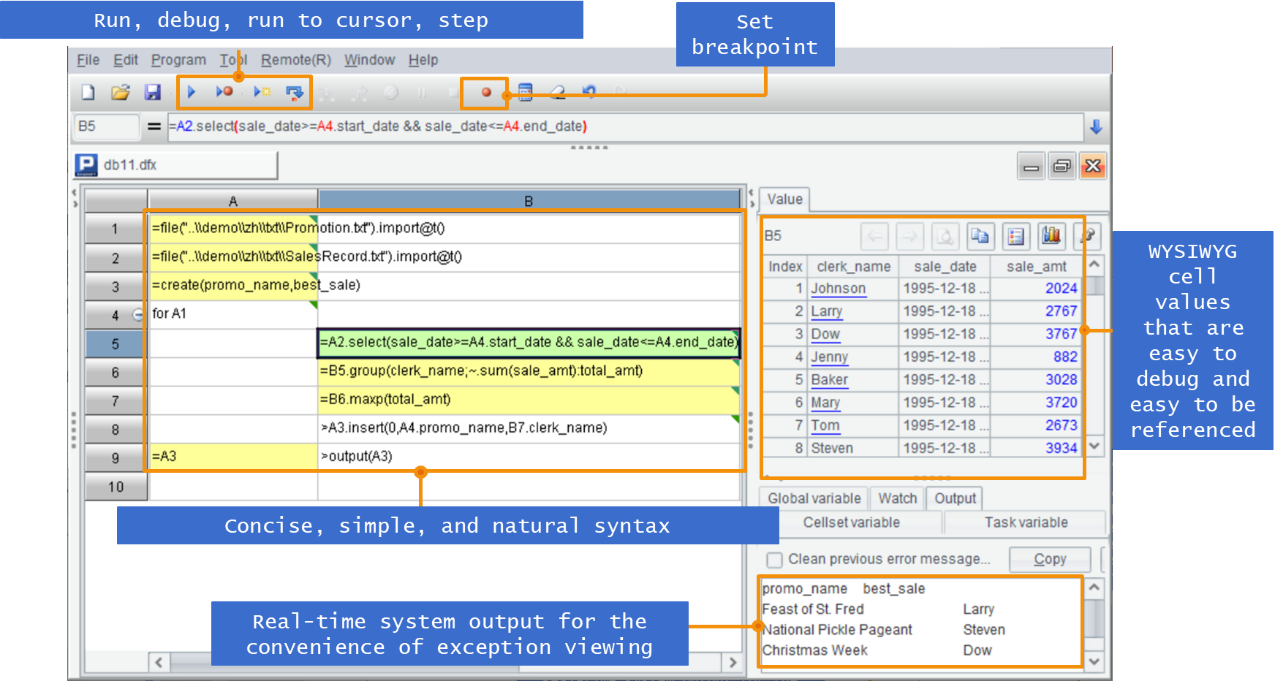
The result of each step can be viewed in real time, which is convenient and efficient compared with the hard to debug SQL and stored procedures.
The SPL code can integrate with or be embedded into the reporting tool. SPL offers the standard JDBC driver to be invoked by the reporting tool. So, the language is capable of replacing the hardcoding used for achieving data preparation, or working together with the old way.
Improving Java and stored procedures’ weaknesses in handling data preparation
It is common for reporting tools to use stored procedures and Java to achieve complex data preparation logic. This brings limited conveniences but large big troubles for report development.
Stored procedures are hard to write and debug. They are even harder to extend due to its non-migratability, causing highly tight coupling between the reporting tool and the database. Creating and modifying a stored procedure requires a high database privilege, which could bring about potential security risks. Maintaining stored procedures needs a special DBA, pushing the cost of report development higher. Moreover, it is probably that one stored procedure is shared by different modules or applications, resulting in tight coupling between them; any change to the stored procedure will affect all related applications.
SPL’s computational capabilities are independent of databases. If we compare SPL to the stored procedure, the former is like a kind of “outside database stored procedure”, which decouples the reporting tool from the database, and applications from each other, eliminating security problems and making the code much more migratable. SPL’s open diverse data source support enables to modify only the data source connection without changing the computing logic when the database is switched over to another type or is scaled, making it convenient to achieve smooth migration.
It is difficult to code the data preparation process in Java because the language does not have structured data computation class libraries. This means that professional programmers are indispensable, pushing up report development cost. Another problem with the Java way of implementing data preparation is the tight coupling between the query-intensive reporting module and other modules in the application, making it difficult to maintain the former separately. And, as a compiled language, Java lacks an effective hot-swap mechanism, which is a great inconvenience for the changeable report development tasks.
SPL boasts concise syntax that enables to generate shorter code for the same computation, and that is easy to learn for even the report developers, further reducing human resource cost. The SPL code can integrate with the reporting tool module, and operates and is maintained separately from other modules in the application, reducing coupling between them. The interpreted execution SPL supports hot swap to be able to well adapt to the changeable report development tasks.
Eliminating intermediate tables in databases
In order to simplify SQL computations, to increase query performance, or to handle diverse data sources, data is often need to be preprocessed. The intermediate results generated during preprocessing are stored in the database as intermediate tables, on which the data preparation for report development will be performed. This will generally reduce development difficulty to some extent and obtain higher query performance.
The intermediate tables, however, are a double-edged sword. They supply both conveniences and inconveniences. In most cases, intermediate tables cannot be deleted once they are created and accumulate to a staggering number, tens of thousands of them sometimes (It is hard to identify which programs they are serving and classify them because database tables are managed linearly, which makes deletion almost impossible).
These intermediate tables take up database space and leave little capacity for other purposes. Generating intermediate table consumes database computing resources, leading to database performance decrease. And too many intermediate tables increase demand for database scaling.
SPL has independent computational capabilities that can store intermediate tables in files outside the database (in open data file formats or SPL storage formats). It then processes data based on these files and outputs result sets to the reporting tool, achieving the data preparation process.
Placing the large number of intermediate tables in a file system will considerably relieve database workload, releasing precious database space and, since no intermediate tables needs to be produced, preserving database computing resources.
Apart from those advantages, “outside database intermediate tables” can be managed with the file system’s tree structure. Intermediate tables under different directories correspond to reports of different businesses. This is simple to manage and can further reduce coupling between report modules.
Achieving report hot swap
Hot swap refers to changing system components without exiting the system. For report development, it is the ability of maintaining reports (including addition, modification and deletion) without the need of restarting the report module and related applications – that is, real time modification and taking effect instantly.
Most reporting tools offer hot-swappable templates, but they have done little to improve situations for data preparation, which is a part of the report development process. Though database SQL can enable hot-swappable data preparations, the compiled language Java cannot. But as more applications, such as microservices, are using advanced frameworks, it is Java that becomes the popular tool for implementing data preparations.
One solution to achieving report hot swap is to use SPL, instead of Java, to perform data preparations within applications, such as microservices. The interpreted execution SPL supports hot swap naturally and offers a developed computational system and agile syntax, making data processing convenient.
Solving diverse data source problem
Nowadays there are a variety of report data sources, including RDB, NoSQL, CSV, Excel, HDFS, Restful/Webservice and Kafka. Diverse data sources bring two problems: How to connect to them and how to perform associations between them. Under microservices and frameworks where the front-end and the back-end are separated, almost all reporting tools choose not to develop reports using databases, only exacerbating the problems.
Conventionally there are three solutions to the diverse report data source issue:
One is to use reporting tools’ own abilities. Some reporting tools support connections to multiple types of data sources. Data is retrieved from each source and undergoes a series of computations, including associative operations, within the desired report template. But reporting tools have rather weak computing abilities and can only achieve a very limited number of diverse data source mixed computations.
Another is to ETL data from the diverse sources to a RDB so that the multi-source computation is converted into a single-source one, and then use SQL to accomplish it. The approach is both roundabout and non-real-time, leading to low database performance when data volume is large or the computation is complex. Besides, the way runs counter to the microservices framework principles.
The third is to use Java hardcoding. We’ve already talked about Java’s problems – hard to code and non-hot-swappable.
At present, the open-source SPL supports quickly connecting to dozens of data sources to perform data retrieval. In addition, SPL offers a great number of class libraries for implementing complex computations conveniently, including mixed computations between different types of sources and multi-source joins.

SPL’s capability of achieving multi-source computations in real time and then outputting the result directly to the reporting tool for presentation solves real time issue, makes up for reporting tools’ lack of computing abilities, deals with the Java non-hot-swap difficulty, and is the ideal solution to the diverse report data source problem.
Enhancing report performance
Report performance is one of the most important concerns. As the main OLAP application scenario, a report development task probably involves huge volumes of data. Both the large data size and complex computing logic often cause unsatisfactory performance. As reports are business-users-oriented, poor performance is sure to lead to bad user experience. On the surface, report performance issues appear to be caused by slow report queries, but actually, most can be traced to the data preparation phase. If the data can be efficiently prepared, the presentation or visualization process will become really fast.
Report data preparation processes the original data and generates a data set required by data presentation or visualization. Though the aggregate result set after summarization used by a report for presentation or visualization usually is relatively small, the size of original data is probably huge. What’s more, the data processing logic could be complex. Both will result in poor performance.
`There are more than one solution to the performance problem. SQL optimization is the common solution. And SPL is the better another one. SQL execution efficiency relies on database optimization ability, but the database optimization engine is prone to non-function when faced with complex SQL, leading to low efficiency. SPL provides a series of high-performance algorithms and, in those cases, we can implement the computing logic with SPL to increase execution efficiency.
If the slow query is caused by the heavily overloaded database, SQL optimization is useless. Sometimes even the SQL ability is unavailable (with non-RDB data sources). In these cases, SPL, with its database-independent computational capabilities, becomes an ideal choice. Here we should make note that, for computation-intensive scenarios, SPL optimization requires that data be first stored in a file system outside of the database in order to reduce I/O from RDB to SPL. Because the I/O duration is likely to be longer than computing time if data is retrieved from the database in real time. SPL storage format is a particularly efficient way of organizing data, enabling high performance when computations are performed based on it.
Besides data preparation, data transmission is another performance bottleneck. When the reporting tool accesses the database through JDBC to try to retrieve desired data but if the data volume is large or the database JDBC is slow to response (as different databases have JDBCs of different efficiencies), it will take very long to finish the data transmission and thus slow down the report development process.
For data-intensive report development tasks, we can enhance performance using SPL multithreaded data retrieval. The approach is to create multiple database connections (related databases should be available) in SPL and retrieve data needed for building the report through multithreaded processing. The desired data can come from one table or a multi-table join result set. In theory, this can reduce data transmission to 1/n of the original duration (n is the number of threads) and thus improve report performance.
At times, reporting tools perform computations slowly. For instance, the reporting tool implements a multi-data-set join through an expression in a cell of a report, such as ds2.select(ID==ds1.ID). The report engine performs the join to parse the expression based on a traversal from beginning to the end – it retrieves the first record from ds2 (data set 2) and traverses ds1 (data set 1) to search for the record with the same ID, and retrieves the second record from ds2 and search ds2 for the matching record with traversal, and so on…
The operation’s complexity is quadratic. Performance is little affected when original data size is small, but it will drop sharply when data size grows to even relatively large.
The solution is to move the implementation of multi-data-set join from the reporting tool side to the data preparation phase. When the data source consists of only one database, SQL is enough to perform the join. But when SQL cannot run efficiently or when there are more than one data source, we can use SPL to realize the join fast using its diverse data source support ability, and high-performance algorithms and storage scheme.
Handling endless reporting needs cheaply and efficiently
Any part of a report that does not keep pace with an enterprise or an organization’s information system update will be continuously updated and modified as long as the system is maintained. The enterprise or organization will have endless report development tasks generated during business operations. The inexorable reporting needs can only be satisfied, which calls for a cost-effective way.
In a nutshell, there are three steps for dealing with the never-ending reporting demand:
Step 1 Reporting tool for labor-saving data presentation
Let’s begin from the easiest part. By introducing a professional reporting tool, we can achieve automatic data presentation and visualization in various charts and graphs without the need of human labors. This has become the common practice as most enterprise users use reporting tools to build reports.
Step 2 Computing tool for labor-saving data preparation
Similar to step 1, automating data preparation is the supreme solution to the long-standing performance issue in this phase. The most part of the essay discusses data preparation performance issue. Conclusion is that the open-source SPL, with the concise syntax, diverse data source support ability and hot-swap feature, is the ideal tool for achieving data preparation automation. Now the two steps have automated all report development jobs and speed up the whole process.
Step 3 Independent report module for optimizing application architecture
After the comprehensive automation of report development process, it is time to adjust the application architecture to decouple report module from the business system. The report module will only share the data source (database or any other type of data storage medium) with the business system and the connection between them becomes loose. The automated data presentation phase and data preparation phase make it possible that report computations can be interpreted and executed by a middleware. This avoids the frequent restart of the business system each time when there is any update or change to the report, significantly reducing the complexity of operation and maintenance. One particular important thing in this step is to sort out data sources to list data needed by reporting module separately. This data will become the only source the later report development jobs access.
The three-step automation of reporting development process can increase efficiency and optimize application architecture. An independently operated and maintained report module is sounder and more effective in terms of both technical framework and human resource utilization, making a powerful tackle for handling the perpetual report development needs.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version