

Open-source SPL turns pre-association of query on bank mobile account into real-time association
Abstract
The backend for querying the current account details with Bank S’s mobile banking is Elastic Search, and the code table of business entities needs to be pre-associated redundantly with the detail wide table. When the business entity changes, the large table with hundreds of millions of data must be refreshed, which takes several hours. Click to learn: Open-source SPL turns pre-association of query on bank mobile account into real-time association
Current situation
The mobile banking system of bank S needs to provide its customers with current details query function, and the bank requires a response speed in seconds in the case of large data amount and high concurrency access. This bank first adopts a well-known commercial HADOOP platform as the query backend, and the platform supports the real-time association query of multiple tables, but its concurrency performance is too poor to meet the requirements. In this case, the bank has to replace this HADOOP server with Elastic Search (ES) cluster, and deploys 6 servers in total. After that, the response speed can be less than 1 second when querying three-year 300 million pieces of current details at a concurrency number close to 100. Although the performance meets the requirements after the ES is used, three serious problems exist:
1. ES does not support multi-table association, and the business entity code table needs to be pre-associated, adding redundantly the name of business entities into the wide table of current details. Where the merger, dissolution, addition or change occurs to the business entities, it has to refresh all 300 million pieces of data in the wide table, which will take several hours. At this time, a timely and accurate query cannot be provided and, such change is common for business entities, occurring almost every few months.
2. Restarting the ES cluster is very slow, and every time the program is upgraded, it needs to be restarted. During this period, the query service has to be suspended.
3. ES cluster has many nodes, resulting in heavy workload on administration and maintenance.

Figure 1 Large access amount from mobile accounts
Under the premise of ensuring performance, is there a way to real-time associate the current details with the business entity so as to avoid the code refresh problem and accompanying ES restart problem?
Solution
Step 1, analyze the characteristics of business data and calculations.
The memory capacity of the backend server for account query is 256G, and it is quite difficult to hold 300 million pieces of detail data of three years. Since the detail data will continue to grow over time, the scheme must be designed based on the premise that a single server cannot hold all detail data.
When querying the account with mobile banking, each customer can only query his own current details. Although the total amount of detail data is large, the amount of data of each customer is not large, only a few to thousands of pieces.
Also, the data amount of business entity code table is not large, only a few thousand pieces.
Step 2, determine the optimization scheme.
From the perspective of data amount, if the all-in-memory operation scheme is adopted, we must use a cluster with multiple servers, this way, however, will result in higher administration and procurement costs. In fact, even if the query occurs concurrently, the amount of data involved still accounts for a very small proportion of all data. Therefore, the utilization rate of all-in-memory operation is very low, and the investment is not cost-effective. In view of this situation, we still hope to design an optimization scheme based on external storage mechanism, so as to cope with long-term data growth at a low cost.
Let's view from the characteristics of data and calculations. If the current detail data are stored orderly by account numbers, and then establish an account number index, we can quickly find all data of the specified account number during query, as shown in the figure below:
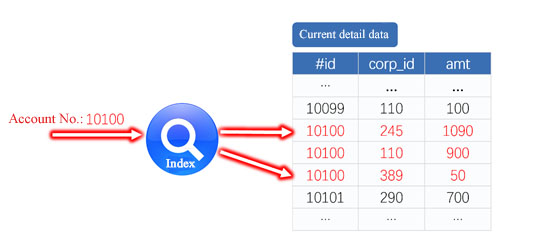
Figure 2 Index query for physically ordered storage
It can be seen from figure 2 that when querying the current details, it can significantly reduce the IO on the disk since the data is continuously read, thereby effectively increasing query speed. In this way, even with external storage mechanism, the query amount each time is very small, and the performance requirements can also be satisfied.
The business entity code table is stored independently and pre-loaded into memory, and there is no need to add it into the current detail table redundantly.
After quickly finding the data of current account, read them all into the memory, in this way, it will be very fast to associate them with the business entity code table preloaded into memory. Such all-in-memory operation association needs to use the pointer reference method to do HASH association, which has the best performance.
In this way, the business entity code table and the current detail table are associated in real time, which can avoid the problem of code refresh caused by pre-association.
Step 3, determine the technical selection. Since ES does not support multi-table association, and it cannot solve the refresh problem of business entity code, it is excluded from the selection range.
Relational databases (including relational database of HADOOP family) are generally based on the theory of unordered set, and cannot guarantee the data are orderly stored physically. Adding the index is only ordered logically, and cannot reduce physical hard disk fragment access as shown in the figure below:
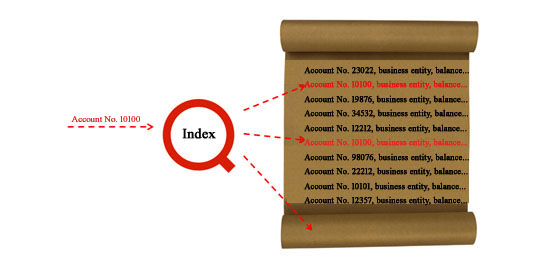
Figure 3 Problem with database index
Figure 3 shows that, in the table of the relational database, the same account number may exist everywhere, therefore, the index search has to read data from multiple locations on the hard disk. Each query is slower, and the overall performance will be poor in the case of multiple-concurrency. Since it is difficult for the conventional relational database to achieve the above optimization scheme, it is also excluded from the selection range.
If the high-level language such as Java or C++ was used, it could implement the above algorithms; however, these operations are very difficult to code in Java or C ++, moreover, it needs hundreds of lines of code to write just one HASH association, and it's not universal. Too large amount of coding will lead to too long project period, hidden trouble with code errors, and it is also difficult to debug and maintain.
The open-source esProc SPL provides support for all the above algorithms, including mechanisms such as the high-performance file, physically ordered storage, file index, and pointer reference association method in all-in-memory operation, which allows us to quickly implement this personalized calculation with less amount of code.
Step 4, implement the optimization scheme.
Firstly, we need to write esProc SPL code for data initialization and conversion, so as to orderly store the current detail data into the high-performance file by account number, and generate an account-number-based index file.
Secondly, write the SPL code for query, and the input parameter is account number. First, use the index file to search out all data of the inputted account number, and load them into memory; and then associate them with the business entity code table preloaded in memory, and the association should be made with the pointer reference method; finally, return the results to the front-end application.
The data in ES was originally extracted from the data warehouse by ETL tools on a daily basis. After optimization, ETL will extract the daily incremental data and merge them into esProc’s high-performance file in an orderly manner. Originally, the front-end application accessed ES through calling the JDBC driver, after optimization, it will call esProc’s JDBC driver instead, and the SPL code will be called in a way similar to calling the stored procedure of database.
Actual effect
The actual optimization effect is very obvious after a few days of coding and testing. After optimization, we still query 300 million current detail data of three years with the same concurrency number and with only one server, the response time is 0.5 seconds. The hardware configuration of esProc server is exactly the same as that of ES server, the concurrent access capability, however, is increased by 6 times.
Since the current detail table and the business entity code table are stored separately and calculated in a real-time association way, when the business entities change, it only needs to change the code table, and does not need to refresh the entire detail table. Moreover, the maintenance time for code table change is less than 1 second, which completely solves the problem of code refresh.
It only takes 1 or 2 seconds for esProc to restart, which also solves the problem of very slow restarting of ES.
The esProc is used to implement high-performance query, while the ES works for full-text retrieval and search, and therefore, they both play to their respective strengths.
In terms of development difficulty, SPL has made a lot of encapsulations, provided rich functions, and built-in the basic algorithms required by the above scheme. The SPL code corresponding to the algorithms mentioned above has only a few lines:
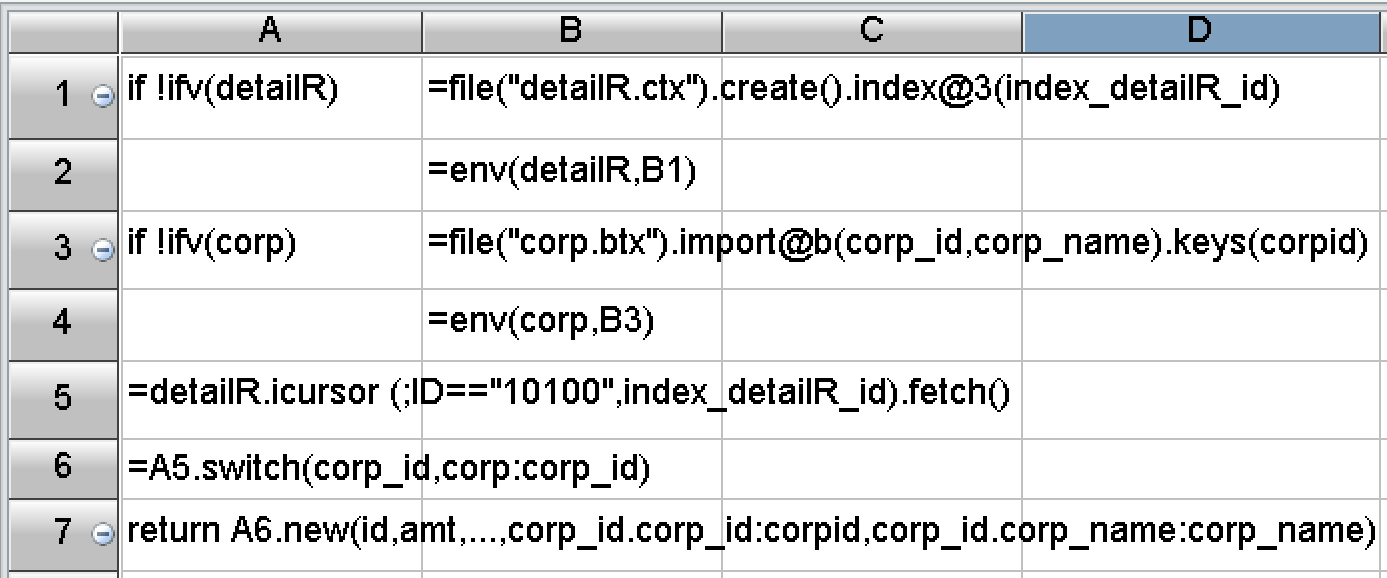
Figure 4 SPL code for account query
Postscript
To solve the performance optimization problem, the most important thing is to design a high-performance computing scheme to effectively reduce the computational complexity, thereby ultimately increasing the speed. Therefore, on the one hand, we should fully understand the characteristics of calculation and data, and on the other hand, we should have an intimate knowledge of common high-performance algorithms, only in this way can we design a reasonable optimization scheme according to local conditions. The basic high-performance algorithms used herein can be found at the course: , where you can find what you are interested in.
Unfortunately, the current mainstream big data systems in the industry are still based on relational databases. Whether it is the traditional MPP or HADOOP system, or some new technologies, they are all trying to make the programming interface closer to SQL. Being compatible with SQL does make it easier for users to get started. However, SQL, subject to theoretical limitations, cannot implement most high-performance algorithms, and can only face helplessly without any way to improve as hardware resources are wasted. Therefore, SQL should not be the future of big data computing.
After the optimization scheme is obtained, we also need to use a good programming language to efficiently implement the algorithms. Although the common high-level programming languages can implement most optimization algorithms, the code is too long and the development efficiency is too low, which will seriously affect the maintainability of the program. In this case, the open-source SPL is a good choice, because it has enough basic algorithms, and its code is very concise. In addition, SPL also provides a friendly visual debugging mechanism, which can effectively improve development efficiency and reduce maintenance cost.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version