

Python vs. SPL 3--Loop Function
The functions that calculate every member in the set and traverse the set to get a new result are generally called the loop function. The native loop functions of “list” in Python are too few, and the “for” statement should be used for those slightly complex loops, so instead of introducing them in this article, we’ll focus on comparing the loop functions in Pandas and SPL.
Basic aggregation operation
The common aggregation operations include sum, average, and so on.
Here we take the sum function for example:
To calculate the sum of the first 100 positive integers.
Python code:
import pandas as pd |
import pandas library |
SPL code:
A |
B |
|
1 |
=to(100) |
/generate the sequence |
2 |
=A1.sum() |
/get the sum |
Both Pandas and SPL offer such aggregation operations to get the result easily. The aggregation functions in Pandas are more diverse, such as the more complete statistical functions, while such kinds of functions in SPL have not been improved yet.
Processing before aggregation
Before aggregating, sometimes, we need to process every element in the set to calculate.
For example, to calculate the sum of the first 100 odd numbers.
Python code:
#s is the Series of [1,2,…,100] |
|
SPL code:
A |
B |
|
1 |
=to(100) |
/generate the sequence |
2 |
=A1.sum(~*2-1) |
/use ~ to indicate the current element |
To calculate the first 100 odd numbers, Python uses the convoluted apply function and lambda expression, the former is to execute a certain function in the loop; the later expression equals to a function and is executed on a certain element of Series. While tactfully, SPL uses the operator “~” to calculate the lambda expression, making the code quite easy and more understandable. As long as we know that “~” indicates the current element in the loop and A.sum(...) is equivalent to A.(...).sum(), the whole process is just to loop through and then get the sum.
Here is a more complicated example:
To calculate the natural base e:
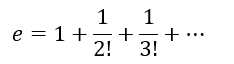
Python code:
#s is the Series of [1,2,…,20] |
|
SPL code:
A |
B |
|
1 |
=to(20) |
/generate the sequence |
2 |
=nf=1,1+A1.sum((nf*=~,1/nf) ) |
/use ~ to indicate the current element |
Python does the calculation simply by first getting the factorial, then looping through and summing to get the result. But if we think about it over again, the operation is a bit rough. The factorial action before n-1 is repeated every time the factorial is calculated, but the result before n-1 can be used to calculate the natural base actually. In brief, one traversal is enough to complete the operation, the lambda expression in Python, however, is not able to calculate in this way. On the contrary, SPL first defines a variable nf, and updates it while looping through in the loop function. So one traversal is able to get the result, which is much more efficient.
Adjacent reference
Apart from the elements in the set, the loop function sometimes also uses the information in adjacent positions of the set.
Here is a specific example:
The set of [123, 345, 321, 345, 546, 542, 874, 234, 543, 983, 434, 897] is the monthly sales of a company for one year. The calculation is to get the maximum monthly increase of the year.
Python code:
sales=[123,345,321,345,546,542,874,234,543,983,434,897] |
|
SPL code:
A |
B |
|
1 |
[123,345,321,345,546,542,874,234,543,983,434,897] |
/generate the sequence |
2 |
=A1.(if(#>1,~-~[-1],0)).max() |
/~[-1] indicates the element that is 1 position before the current element |
Python provides a “shift” method to calculate the element which is one position before, but it does not offer any method of using the position information when looping, which invariably leads to one more traversing on the set. Thus the efficiency is bound to be degraded. While SPL makes full use of the position relations through ~[-1], calculating the difference of adjacent elements by traversing once, which makes the code easy and smooth to write.
Sometimes several elements before and after the current element are used at the same time.
For example, for the same company in the previous example, we calculate the average of the sales for each month and the months before and after the current month.
Python code:
sales=[123,345,321,345,546,542,874,234,543,983,434,897] |
|
SPL code:
A |
B |
|
1 |
[123,345,321,345,546,542,874,234,543,983,434,897] |
/generate the sequence |
2 |
=A1.(avg(~[-1:1])) |
/~[-1:1]indicates all the elements from one position before to one position after the current element |
The Rolling in Python is another new function. But essentially, this problem is the same kind as the previous one, which is understandable if they use the same “shift” or “rolling” function. However, they are actually two completely different functions and not in the same system for using either, so there is no other effective way but to memorize them by rote. On the other hand, in SPL, ~[-1] indicates the element that is one position before the current element; ~[-1:1] indicates all the elements that are from one position before to one position after the current element, which is quite adaptable for other situations and improves the efficiency greatly.
Summary
Although Python has very few native loop functions, Pandas library makes up for the shortcoming and makes it much easier to use, for instance, some common statistical methods can be found in Pandas, giving it advantages over SPL in terms of statistics. However, those methods provided in Pandas are too many and messy, which are very unsystematic. Similar to the examples above, in the consistent structure of “loop function”, Pandas uses one method for one kind of problem, which is more like solving a problem for the sake of solving it. Those methods do not relate to each other at all, therefore, the programmers have no choice but to call the methods one after another when using them.
Oppositely, SPL does a better job as for the loop function structure. Using the one and only A.() loop function, we can perform the corresponding calculation on the elements in the loop, which is easy to adapt for other situations. One traversal is already enough for the problem, sparing the second traversal, which makes the efficiency much better compared to Python.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version