

One-side partitioning algorithm of SPL
When two large tables are associated, performance problems often occur. One of the more common situations is to use the non-primary key field of one large table to associate the primary key of the other. For example, the order table orders and the customer table customer are both large, and the memory cannot hold them. Using the customer No. cid field of order table (hereinafter referred to as fact table) to associate the primary key of customer table (hereinafter referred to as dimension table), the size relationship between these two tables and the memory can be intuitively shown in Figure 1:
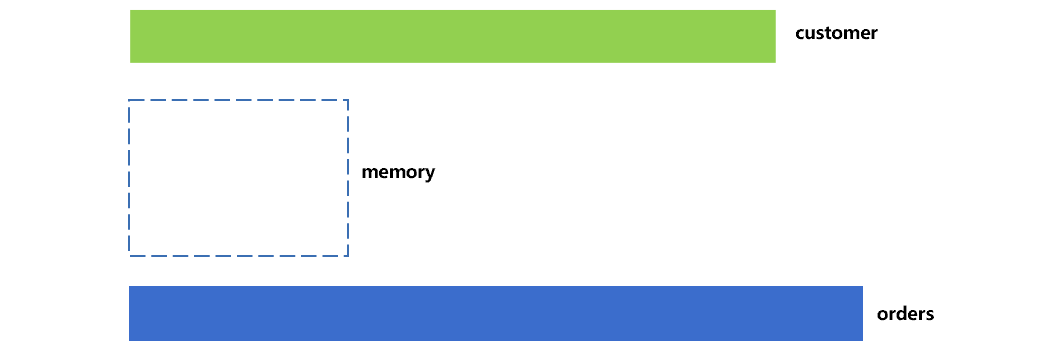
Figure 1
In practice, these two data tables are much larger than the memory. This figure is a schematic only and narrows the gap.
If one of the two tables is relatively small, we can load it entirely into memory and then associate it with the data of another large table in batches. However, the two tables are both large, and we can't do it this way.
If the two large tables are pre-sorted by the associated fields and then perform the ordered merge and join, the calculation can be done. However, other fields of the fact table may also associate with other large tables, for example, the order table associates the product table through the product No., and associates the business table through the business No., and so on. In this case, it is impossible to let a fact table ordered by multiple fields at the same time. Therefore, this method also does not work.
To solve this problem, the database generally adopts the hashing & partitioning method which works in a way that first calculate the hash value of associated fields in two tables respectively, and then put the data whose hash value is within a certain range in a partition, forming the buffer data on external storage, and ensuring that each partition is small enough to load into memory, and finally execute the in-memory join algorithm for each pair of partitions (of two tables) one by one. Since this method will split and buffer both large tables, it can be called two-side partitioning algorithm. When the hash function is in bad luck, a second round of hashing may be required since a certain partition is too large.
For such a scenario where it is difficult to speed up, SPL provides the one-side partitioning algorithm, which can make the calculation as fast as possible. To implement this algorithm, the dimension table needs to be stored orderly by the primary key in advance. When doing the join calculation, SPL first segments the dimension table. The number of segments is calculated according to the size of dimension table and the capacity of memory to ensure each segment can be loaded into memory. Take the customer table as an example, roughly as shown in Figure 2:

Figure 2
Suppose that we divide the customer table into four segments. Since the customer table is stored orderly by the primary key, finding the cid value of the first record in every segment, i.e., cid0 to cid3, can determine the cid value range for the data of the four segments. The function of pre-storing the dimension table in order by the primary key is reflected in: when the dimension table is divided into n segments, as long as n records are found, the value range of the primary key of each segment can be determined quickly.
Next, split the order table according to the 4 cid value ranges to generate 4 temporary buffer files orders1 to orders4. The schematic diagram is as follows:
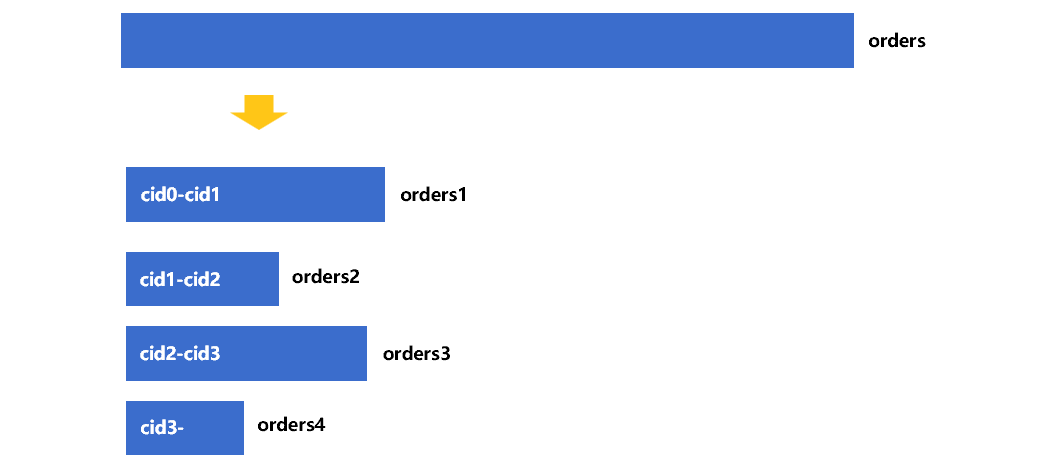
Figure 3
As marked in figure 3, the cid value in the buffer file orders1 of the fact table is between cid0 and cid1, and that of the other three buffer files are also determined. At this point, we can ensure that the customer No. corresponding to the record in orders1 to orders4 is in part1 to part4 of the customer table, respectively. Therefore, we can join the dimension table segments in memory with the corresponding buffer file cursor of the fact table. See Figure 4 for the general process:

Figure 4
SPL will first load part1 of the customer table into memory, then join it with the cursor of orders1, and finally, output the result as a cursor. After that, SPL will join the remaining three pairs of fact table buffer files and dimension table segments in turn. In this way, the result cursor can be obtained.
It seems that the overall process of SPL’s one-side partitioning is similar to that of two-side partitioning. The difference is that the segmenting of dimension table executed by SPL is equivalent to logically performing the partitioning, and each segment is one partition, and it does not need to partition the dimension table to generate the buffer file anymore, and instead it only needs to partition the fact table, therefore we call it one side partitioning. Moreover, this algorithm can divide the dimension table into equal segments, and the second round of hashing and partitioning due to the bad luck with hash function will never occur. A certain partition of fact table may be too large such as orders1, in this case, we can execute the method of loading the dimension table into memory in segments, and then joining the segments with the buffer file cursor of fact table in batches as shown in Figure 4, as a result, there is also no need to do secondary partitioning. Since the amount of buffered data of one-side partitioning is much less than that of two-side partitioning, the performance will also be better.
SPL encapsulates the one-side partitioning algorithm:
A |
|
1 |
=file("customer.btx") |
2 |
=file("orders.btx").cursor@b(cid,amount) |
3 |
=A2.joinx@u(cid,A1:cid,area,discount) |
4 |
=A3.groups(area;amount*discount) |
By using joinx@u function in this code, SPL will think that the fact table is also large and needs to be partitioned. Since the dimension table needs to be accessed in segments, it should appear as a data file rather than a cursor.
The cursor returned by joinx@u is no longer ordered by the primary key of fact table. From the algorithm indicated in Figure 4, we know that SPL will fetch the data one by one according to the segments of dimension table, and return them after joining, and the overall order should be the same as the primary keys of dimension table. However, the data in each segment are fetched by the order of the partitions of fact table, and each segment is not necessarily ordered by the primary key of dimension table, hence it looks unordered on the whole.
Usually, the fact table is ordered by the primary key, and sometimes this order needs to be used for the next round of calculation, hence the association results should also be kept in order. If we remove the @u option, the results will be ordered by the primary key of the fact table. At this time, SPL will generate a sequence number for each record in the original fact table, and write the data after they are sorted by this sequence number during partitioning and buffering, and then write the data once again into a buffer file after the joining between every pair of fact table buffer file and the dimension table segment is done, and finally merge and sort all the buffered data generated in the latter round by the original sequence number. In this way, it is equivalent to doing one more big sorting than joinx@u; although the performance will be slower, the ordered characteristic of the fact table can be used to improve the performance in the subsequent calculations.
The actual test proves the performance advantage of one-side partitioning. For the association between a large fact table and a large dimension table, the comparison test results between SPL and Oracle database are as follows, under the condition of the same data amount and computing environment (time unit: second):
Number of records of the fact table |
1 billion |
1.2 billion |
1.4 billion |
1.5 billion |
1.6 billion |
Oracle |
730 |
802 |
860 |
894 |
>10 hours |
SPL |
486 |
562 |
643 |
681 |
730 |
By calculation, one billion rows of data exceeded the memory capacity of a machine under normal circumstances, but Oracle may have adopted some kind of compression technology, it could even hold up to 1.5 billion rows of data. However, when the data reached 1.6 billion rows, the memory could not hold anyway, and a phenomenon of occupying a large amount of swap area began to occur, thereby causing the running speed to be extremely slow. We didn’t find any result after waiting for 11 hours, so the test had to be stopped. On the contrary, the one-side partitioning technology of SPL is not limited by the amount of data, and is originally designed for external storage. Moreover, this technology can complete the calculation with just one partitioning, and the calculation time basically increases linearly with the increase of the amount of data.
For detailed test data, environment, etc., refer to:
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version