

SPL: Access Kafka
Kafka is a distributed flow information platform, of which there are two kinds of clients, producers and consumers respectively. The former submit data, while the latter read data. There is also no fixed format for the event message delivered in Kafka. Instead, the consumers and producers are free to agree on some individual formats. As for the big strings in formats of JSON, XML, etc., for instance, SPL is able to parse and perform subsequent complex operations on them.
Create/close Kafka connection
Similar to the JDBC connection of relational database, SPL also connects Kafka with paired "create/close".
kafka_open(propertiesFile; topic1, topic2, ...), propertiesFile is the connection parameter, topic refers to the Kafka topic, which can be multiple in number. And data can be accessed from multiple topics at the same time.
Here is an example of propertiesFile, and the Kafka official document can be referred for more parameters.

kafka_close(kafkaConn), kafkaConn is the Kafka connection to be closed.
Code sample: A1 creates the connection, and A3 closes the connection after some other data assessing and calculating operations in the middle steps.
A |
|
1 |
=kafka_open("/kafka/my.properties", "topic1") |
2 |
…… |
3 |
=kafka_close(A1) |
Producers sending message
kafka_send(kafkaConn, [key], value), kafkaConn is the Kafka connection, key is the message key, which can be absent, and value is the message content.
Code sample:
A |
|
1 |
=kafka_open("/kafka/my.properties", "topic1") |
2 |
{"fruit":"apple","weight":"35kg"} |
3 |
{"fruit":"pear","weight":"48kg"} |
4 |
=kafka_send(A1, "A100", A2) |
5 |
=kafka_send(A1, "A101", A3) |
6 |
=kafka_close(A1) |
A2 and A3 are two events in JSON format to be submitted; A4 and A5 use the kafka_send() function to submit them to Kafka platform.
Consumers reading message
kafka_poll(kafkaConn), kafkaConn is the Kafka connection that reads all unread data by default:
A |
|
1 |
=kafka_open("/kafka/my.properties", "topic1") |
2 |
=kafka_poll(A1) |
3 |
=A2.derive(json(value):v).new(key, v.fruit, v.weight) |
4 |
=kafka_close(A1) |
The value read in A2 is a JSON string.
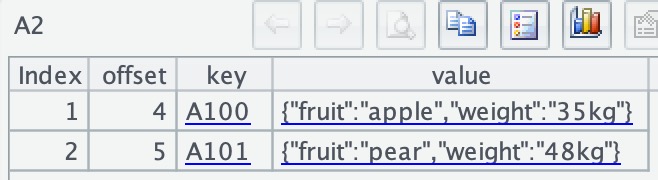
A3 use the json()function to parse JSON strings and the derive() and new() functions to organize the data so as to form a regular data table:
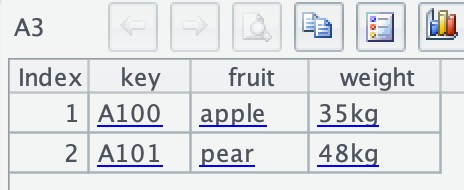
The @c option can be added to load the data in batches from the cursor if the data volume is too big.
A |
|
1 |
=kafka_open("/kafka/my.properties", "topic1") |
2 |
=kafka_poll@c(A1) |
3 |
=A3.fetch(1) |
4 |
=A3.fetch(10) |
5 |
=kafka_close(A1) |
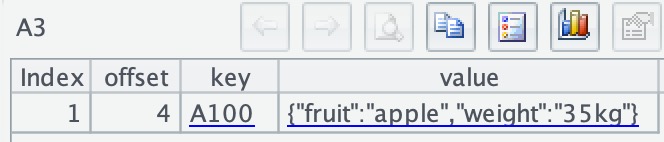
After executing, there is no data in A2 since it is just a cursor object. A3 retrieves the first row of data:
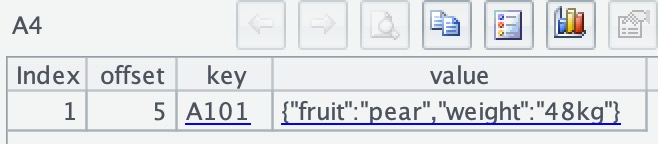
A4 retrieves the next ten rows of data (there are only two rows of data actually, so only the last one is retrieved this time):
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version