

Working Efficiency Improvement Series - Merge Excel
In daily work, we usually need to merge the data of multiple Excel files together for convenient calculation and analysis.
1 Merge by column - same name and number of columns
The most common operation is to merge several files with the same name, number and order of columns by the columns.
For example:
Before merge:
Fruits.xlsx Meats.xlsx
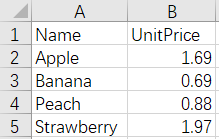
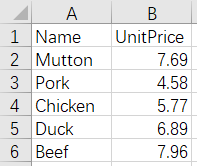
After merge:
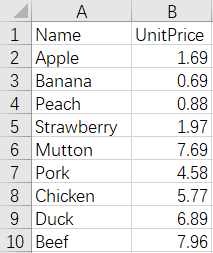
The script of the operation:
A |
|
1 |
=file("Fruits.xlsx").xlsimport@t() |
2 |
=file("Meats.xlsx").xlsimport@t() |
3 |
=A1|A2 |
4 |
=file("Foods.xlsx").xlsexport@t(A3) |
2 Merge by row - same name and number of rows
We usually need to merge the Excel files with the same number and name of rows by the rows. For example:
Before merge:
Fruits.xlsx FruitStock.xlsx
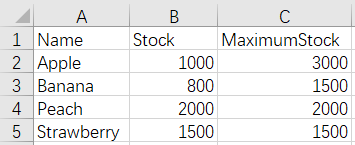
After merge:
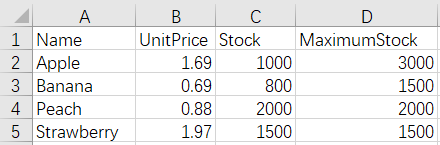
The script of the operation:
A |
|
1 |
=file("Fruits.xlsx").xlsimport@t() |
2 |
=file("FruitStock.xlsx").xlsimport@t() |
3 |
=A1.new(Name,UnitPrice,A2(#).Stock,A2(#).MaximumStock) |
4 |
=file("FruitsPriceStock.xlsx").xlsexport@t(A3) |
3 Merge by column - different name and number of columns - keep all columns
Before merge:
FruitsPriceStock.xlsx
MeatsPriceStock.xlsx
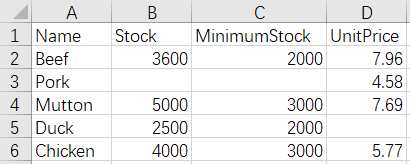
After merge:
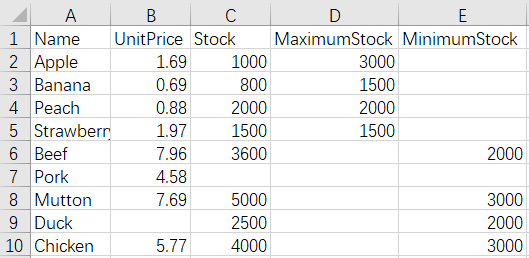
The script of the operation:
A |
B |
|
1 |
=file("FruitsPriceStock.xlsx").xlsimport@t() |
|
2 |
=file("MeatsPriceStock.xlsx").xlsimport@t() |
|
3 |
=create(${(A1.fname()&A2.fname()).concat@c()}) |
/all columns need to be kept, so use the union of column names |
4 |
=A3.insert@f(0:A1) |
|
5 |
=A3.insert@f(0:A2) |
|
6 |
=file("FoodsPriceStock.xlsx").xlsexport@t(A3) |
4 Merge by column - different name and number of columns - keep only duplicate columns
Before merge:
FruitsPriceStock.xlsx
MeatsPriceStock.xlsx
After merge:
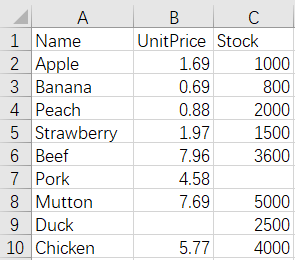
The script of the operation:
A |
B |
|
1 |
=file("FruitsPriceStock.xlsx").xlsimport@t() |
|
2 |
=file("MeatsPriceStock.xlsx").xlsimport@t() |
|
3 |
=create(${(A1.fname()^A2.fname()).concat@c()}) |
/only duplicate columns need to be kept, so use the intersection of column names |
4 |
=A3.insert@f(0:A1) |
|
5 |
=A3.insert@f(0:A2) |
|
6 |
=file("FoodsPriceStock.xlsx").xlsexport@t(A3) |
5 Merge by column - different name and number of columns - keep only columns of the first file
Before merge:
FruitsPriceStock.xlsx
MeatsPriceStock.xlsx
After merge:
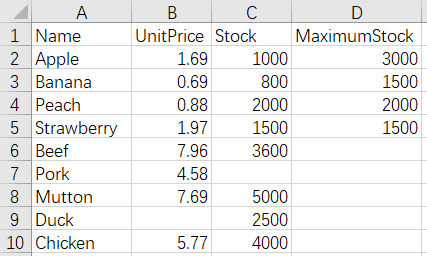
The script of the operation:
A |
B |
|
1 |
=file("FruitsPriceStock.xlsx").xlsimport@t() |
|
2 |
=file("MeatsPriceStock.xlsx").xlsimport@t() |
|
3 |
=A1.insert@f(0:A2) |
/@f option is used to insert the data of the same fields in A2 to A1 |
4 |
=file("FoodsPriceStock.xlsx").xlsexport@t(A3) |
6 Merge by row - different name and number of rows - keep all rows
Before merge:
Meats.xlsx MeatStock.xlsx
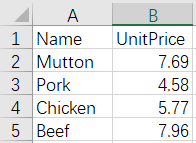
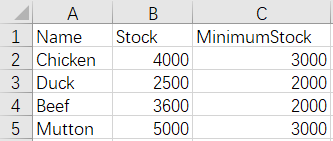
After merge:
The script of the operation:
A |
B |
|
1 |
=file("Meats.xlsx").xlsimport@t() |
|
2 |
=file("MeatStock.xlsx").xlsimport@t() |
|
3 |
=join@f(A1:Price,Name;A2:Stock,Name) |
/@f option is full join |
4 |
=A3.new([Price.Name,Stock.Name].ifn():Name,Stock.Stock,Stock.MinimumStock,Price.UnitPrice) |
/bold code means to select the non-null Name values |
5 |
=file("MeatsPriceStock.xlsx").xlsexport@t(A4) |
7 Merge by row - different name and number of rows - keep only duplicate rows
Before merge:
Meats.xlsx MeatStock.xlsx
After merge:
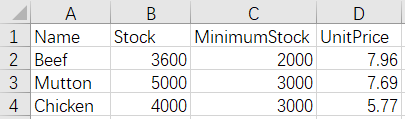
The script of the operation:
A |
B |
|
1 |
=file("Meats.xlsx").xlsimport@t() |
|
2 |
=file("MeatStock.xlsx").xlsimport@t() |
|
3 |
=join(A1:Price,Name;A2:Stock,Name) |
/inner join |
4 |
=A3.new(Stock.Name,Stock.Stock,Stock.MinimumStock,Price.UnitPrice) |
|
5 |
=file("MeatsPriceStock.xlsx").xlsexport@t(A4) |
8 Merge by row - different name, number and order of rows - keep only rows of the first file and align the rows
Before merge:
Meats.xlsx MeatStock.xlsx
After merge:
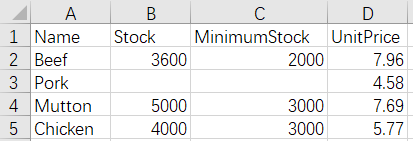
The script of the operation:
A |
B |
|
1 |
=file("Meats.xlsx").xlsimport@t() |
|
2 |
=file("MeatStock.xlsx").xlsimport@t() |
|
3 |
=join@1(A1:Price,Name;A2:Stock,Name) |
/@1 option is left join, notice: here is a number “1” rather than a letter “l” |
4 |
=A3.new([Price.Name,Stock.Name].ifn():Name,Stock.Stock,Stock.MinimumStock,Price.UnitPrice) |
/ifn() is used to select non-null Name values |
5 |
=file("MeatsPriceStock.xlsx").xlsexport@t(A4) |
9 Merge by column - convert file names to column values - unfixed number of files
Before merge:
Apple.xlsx Bread.xlsx Pork.xlsx
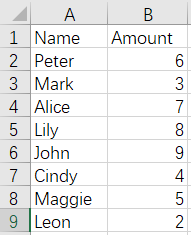
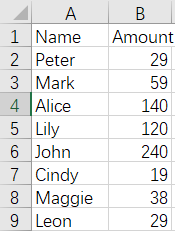
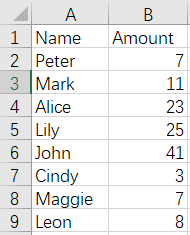
After merge:
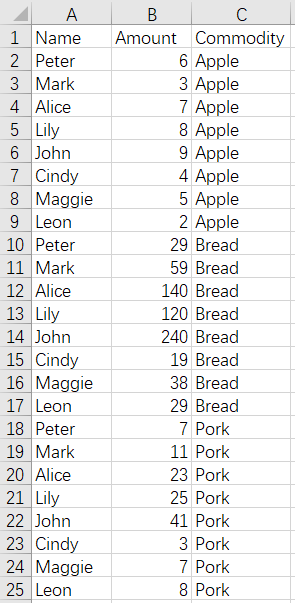
The SPL script of the operation:
A |
B |
|
1 |
=directory@p("tmp/*.xlsx") |
/list all files in the directory, which can be used to process unfixed number of files |
2 |
=A1.conj((fn=filename@n(~),T(~).derive(fn:Commodity))) |
|
3 |
=file("Amount.xlsx").xlsexport@t(A2) |
10 Merge by row - convert file names to column names
Before merge:
Apple.xlsx Bread.xlsx Pork.xlsx
After merge:
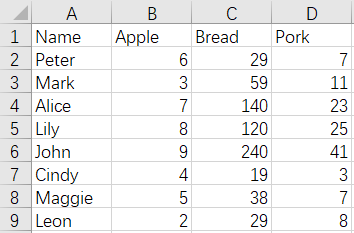
The SPL script of the operation:
A |
B |
|
1 |
=directory@p("tmp/*.xlsx") |
/list all file names in the directory |
2 |
=A1.(filename@n(~)) |
/obtain file names without extensions |
3 |
=A1.(T(~)) |
/read files as a table sequence |
4 |
=A3(1).new(Name,Amount:${A2(1)},A3(2)(#).Amount:${A2(2)},A3(3)(#).Amount:${A2(3)}) |
/convert Amount fields of the original table sequence to corresponding file names while generating a new table sequence |
5 |
=file("Amount.xlsx").xlsexport@t(A4) |
11 Merge by row - one to many - copy data
Before merge:
Types.xlsx

Foods.xlsx
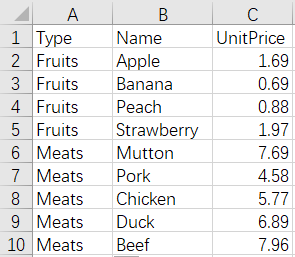
After merge:
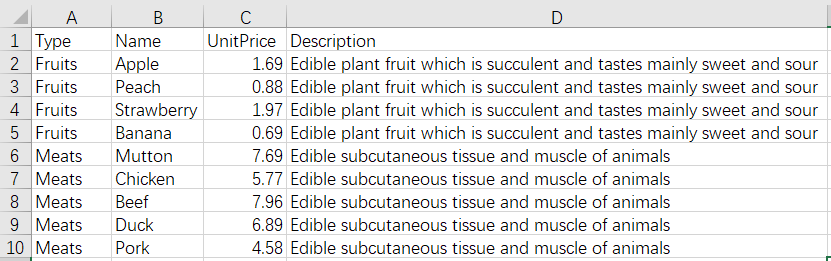
The SPL script of the operation:
A |
B |
|
1 |
=T("Types.xlsx") |
|
2 |
=T("Foods.xlsx") |
|
3 |
=join@f(A1:Type,Type;A2:Food,Type) |
/@f is full join |
4 |
=A3.new(Food.Type,Food.Name,Food.UnitPrice,Type.Description) |
|
5 |
=T("FoodsDescription.xlsx",A4) |
12 Merge by row - one to many - leave subsequent rows empty
Before merge:
Types.xlsx
Foods.xlsx
After merge:

The SPL script of the operation:
A |
B |
|
1 |
=T("Types.xlsx") |
|
2 |
=T("Foods.xlsx") |
|
3 |
=A1.align(A2:Type,Type) |
/align means A1 is aligned to A2 with alignment conditions as Type field of A2 and Type field of A1; only the first row is aligned if there are duplicate data in A2 |
4 |
=A2.new(Type,Name,UnitPrice,A3(#).Description) |
|
5 |
=T("FoodsDescription.xlsx",A4) |
13 Merge and de-duplicate by column - duplicate whole rows
If the data of the whole row are duplicated, only one of the same records will be kept during the merge. For example:
Before merge:
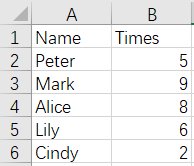 and
and 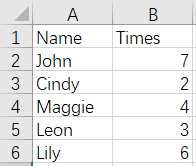
From the above figures, we can see that the data of Cindy and Lily are duplicated in the whole rows. The result of merge is as follows:
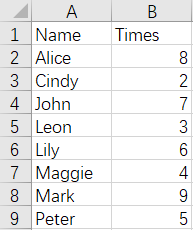
The script of the operation:
A |
B |
|
1 |
=file("Customer1.xlsx").xlsimport@t().sort(Name,Times) |
/the original data need to be sorted because of merge |
2 |
=file("Customer2.xlsx").xlsimport@t().sort(Name,Times) |
|
3 |
=[A1,A2].merge@u(Name,Times) |
/merge@u indicates union with Name and Times as criteria for duplication; so if the whole row is used as the criterion, then all the field names should be added |
4 |
=file("CustomerTimes.xlsx").xlsexport@t(A3) |
14 Merge and de-duplicate by column - duplicate row headers - keep the data that firstly appear
When merging multiple Excel files by column, we may use only the row headers or one/several key columns as criteria for determining whether data are duplicated. As shown in the following example where Name is used as a criterion for duplication:
Before merge:
and
From the above figures, Cindy and Lily are rows with duplicate Name fields, and the result of merge is:
The script of the operation:
A |
B |
|
1 |
=file("Customer1.xlsx").xlsimport@t().sort(Name,Times) |
/the original data need to be sorted because of merge |
2 |
=file("Customer2.xlsx").xlsimport@t().sort(Name,Times) |
|
3 |
=[A1,A2].merge@u(Name) |
/merge@u indicates union with Name as the criterion of duplication |
4 |
=file("CustomerTimes.xlsx").xlsexport@t(A3) |
15 Merge and de-duplicate by column - duplicate row headers - keep non-null data
Customer3.xlsx Customer4.xlsx
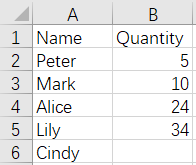
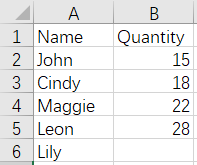
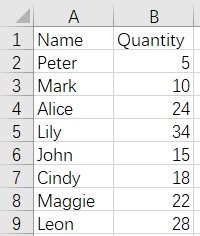
From the above figures, Cindy and Lily rows are duplicated, and the records with null Quantity value will be removed during the merge. The result is as follows:
The script of the operation:
A |
|
1 |
=file("Customer3.xlsx").xlsimport@t().select(Quantity!=null) |
2 |
=file("Customer4.xlsx").xlsimport@t().select(Quantity!=null) |
3 |
=A1|A2 |
4 |
=file("CustomerQuantity.xlsx").xlsexport@t(A3) |
16 Merge and de-duplicate by column - duplicate row headers - delete all duplicate data
CustomerTotal.xlsx Customer.xlsx
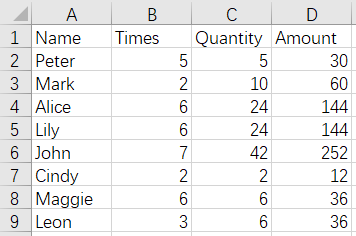
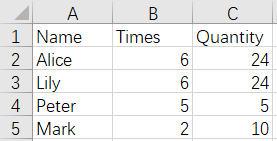
Since the same key columns will be considered as duplicate date, then as a key column, the duplicate records of Name field in Customer.xlsx need to be deleted from CustomerTotal.xlsx, and the result of de-duplication is:
The script of the operation:
A |
B |
|
1 |
=file("CustomerTotal.xlsx").xlsimport@t().sort(Name) |
/the original data need to be sorted because of merge |
2 |
=file("Customer.xlsx").xlsimport@t().sort(Name) |
|
3 |
=[A1,A2].merge@d(Name) |
/@d option means to delete the data that appear in subsequent table sequence from the first table sequence |
4 |
=file("CustomerTotalNew.xlsx").xlsexport@t(A3) |
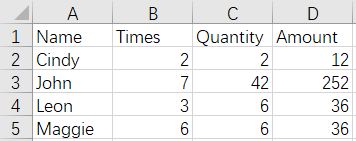
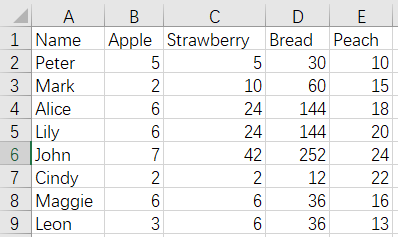
17 Merge and de-duplicate by row - duplicate column names - keep data in columns that appear later
Before merge:
CustomerFruits.xlsx
 and
and
CustomerMeats.xlsx
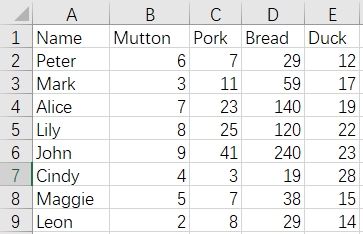
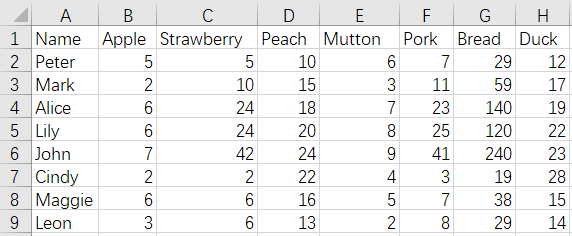
As shown, Bread columns are duplicated, and we expect to keep Bread fields of the seconds file and delete Bread fields of the first file after merging. The result is as follows:
The script of the operation:
A |
|
1 |
=file("CustomerFruits.xlsx").xlsimport@t() |
2 |
=file("CustomerMeats.xlsx").xlsimport@t() |
3 |
=A1.new(Name,Apple,Strawberry,Peach,A2(#).Mutton,A2(#).Pork,A2(#).Bread,A2(#).Duck) |
4 |
=file("CustomerFoods.xlsx").xlsexport@t(A3) |
18 Merge by row and column simultaneously - keep data that firstly appear
Before merge:
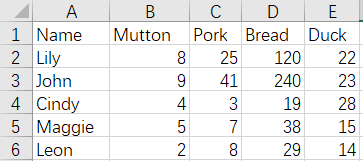
CustomerFruits1.xlsx
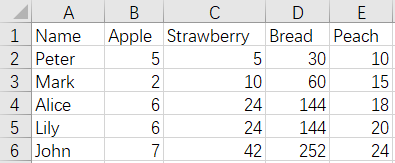
CustomerMeats1.xlsx
According to the order of CustomerFruits1.xlsx first and CustomerMeats1.xlsx later, the duplicate records that appear in CustomerFruits1.xlsx first are kept. And the result of merge is:
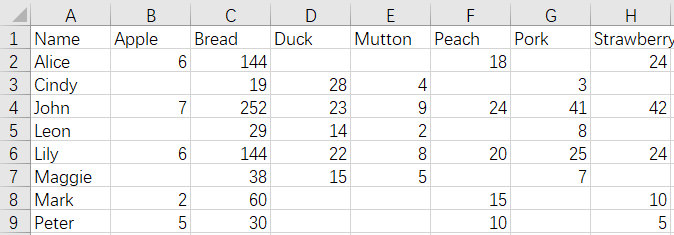
The script of the operation:
A |
B |
|
1 |
=file("CustomerFruits1.xlsx").xlsimport@t() |
|
2 |
=file("CustomerMeats1.xlsx").xlsimport@t() |
|
3 |
=A1.pivot@r(Name;col,val) |
/transpose the original data of pivot structure to a list |
4 |
=A2.pivot@r(Name;col,val) |
|
5 |
=(A3|A4).group@1(Name,col) |
/select the record that appears firstly after grouping |
6 |
=A5.pivot(Name;col,val) |
/transpose the data back to pivot structure |
7 |
=file("CustomerFoods1.xlsx").xlsexport@t(A6) |
19 Aggregate files - same rows and columns
In practical business, sometimes we need to aggregate data while merging multiple Excel, for example:
Apple.xlsx Bread.xlsx Pork.xlsx
The Amount fields need to be aggregated to create a total amount field which should be stored in the new file. And the result is:
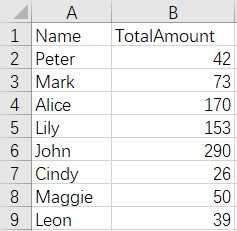
The script of the operation:
A |
|
1 |
=file("Apple.xlsx").xlsimport@t() |
2 |
=file("Bread.xlsx").xlsimport@t() |
3 |
=file("Pork.xlsx").xlsimport@t() |
4 |
=A1.new(Name,Amount+A2(#).Amount+A3(#).Amount:TotalAmount) |
5 |
=file("TotalAmount.xlsx").xlsexport@t(A4) |
20 Aggregate files - merge by row and column simultaneously - aggregate duplicate records
Before merge:
CustomerFruits1.xlsx
CustomerMeats1.xlsx
The final result of aggregating duplicate records and merging is:
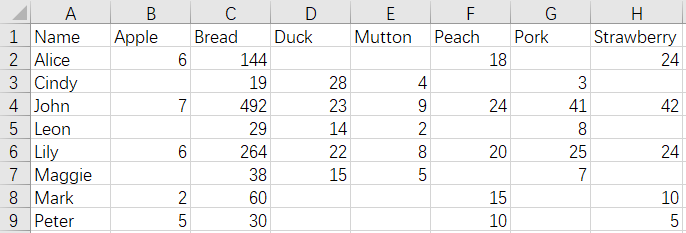
The SPL script of the operation:
A |
B |
|
1 |
=file("CustomerFruits1.xlsx").xlsimport@t() |
|
2 |
=file("CustomerMeats1.xlsx").xlsimport@t() |
|
3 |
=A1.pivot@r(Name;col,val) |
/transpose the original data of cross structure to a list |
4 |
=A2.pivot@r(Name;col,val) |
|
5 |
=(A3|A4).groups(Name,col;sum(val):val) |
/group and aggregate |
6 |
=A5.pivot(Name;col,val) |
/transpose back to cross structure |
7 |
=file("CustomerFoods2.xlsx").xlsexport@t(A6) |
21 Aggregate files - aggregate by cell positions - unfixed number of files
The head office has received the balance sheets from each branch, of which the table of a certain branch is shown below (there are 37 rows in total, but only 14 of them are shown in the table):
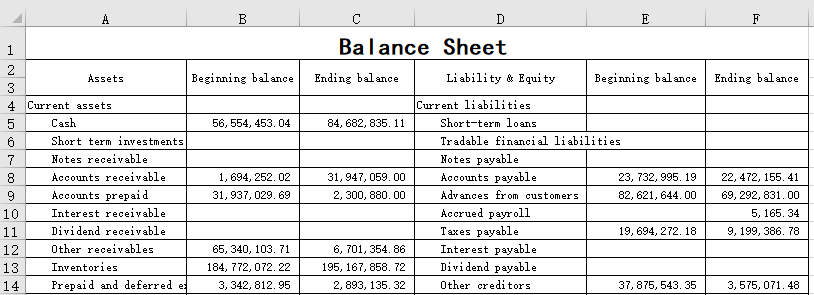
Now we need to aggregate the balance sheets of each branch to generate the balance sheet of head office.
The SPL script is:
A |
B |
C |
|
1 |
=directory@p("zc*.xlsx") |
/list all files with matched format of file name in the directory, which can be used to process unfixed number of files |
|
2 |
=A1.(file(~).xlsopen()) |
||
3 |
=to(4,37) |
[B,C,E,F] |
=A3.(B3.(~/A3.~)).conj() |
4 |
for C3 |
>v=null |
|
5 |
for A2 |
>v+=number(B5.xlscell(A4,1)) |
|
6 |
>A2(1).xlscell(A4,1;string(v)) |
||
7 |
=file("total.xlsx").xlswrite(A2(1)) |
||
A1 List all the to-be-aggregated balance sheets whose file names begin with zc in the folder, and @p option means to list the full path of the file.
A2 Open the files listed in A1 as Excel objects
A3 Specify the row number range of to-be-aggregated numeric cells is from 4 to 37.
B3 Specify the column numbers of to-be-aggregated numeric cells are B, C, E, and F.
C3 Spell out the names of all to-be-aggregated numeric cells using the row numbers in A3 and column numbers in B3.
A4 Loop through all to-be-aggregated numeric cells in C3.
B4 Define the aggregation variable v.
B5 Loop through balance sheets of all branches.
C5 Read the value of current aggregation cell from the balance sheet of current branch, convert it to a number and add it to v.
B6 Save the added v to the balance sheet of the first branch.
A7 Save the balance sheet of the first branch to the balance sheet of head office total.xlsx.
22 Aggregate files - append and aggregate
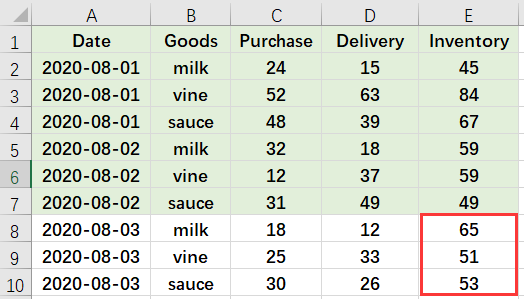
There is a daily purchase and delivery table of goods:
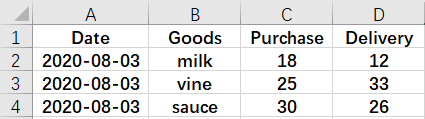
And the daily sales and inventory summary table of goods is as follows:
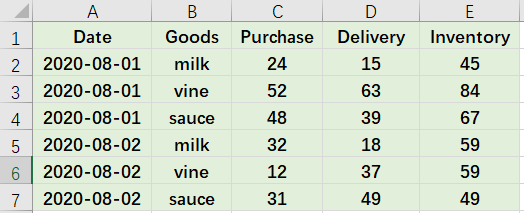
We want to append the daily purchase and delivery records to the summary table in order to calculate the latest inventory: inventory of the previous day + purchase - delivery. And the aggregation result is:
The SPL script of the operation is:
A |
|
1 |
=T("20200803.xlsx").derive(Inventory) |
2 |
=T("total.xlsx") |
3 |
=A1.run(Inventory=A2.select@z1(Goods==A1.Goods).Inventory+Purchase-Delivery) |
4 |
=file("total.xlsx").xlsexport@a(A3) |
A1 Read the data to be appended and aggregated of current day and add a new “Inventory” column.
A2 Read the data of summary table.
A3 Loop through every row in A1 so that the value of “Inventory” is the “Inventory” of the last goods in summary table plus the current “Purchase” and minus the current “Delivery”. @z1 option means to select the first record that satisfies the condition from back to front.
A4 Append and save the result of A3 to total.xlsx, and @a option means to append data.
23 Aggregate files - cumulate and aggregate
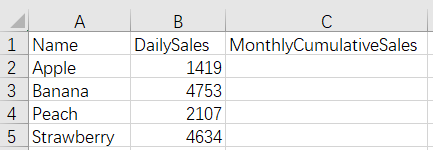
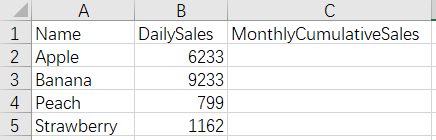
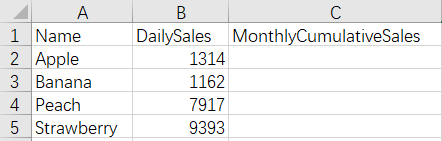
There are daily sales tables of some goods in current month with one file for one day, and we need to add cumulate values to the monthly cumulative sales fields of these files.
Before merge:
20220101.xlsx
20220102.xlsx
20220103.xlsx
And files of other dates are omitted.
After merge:
20220101.xlsx
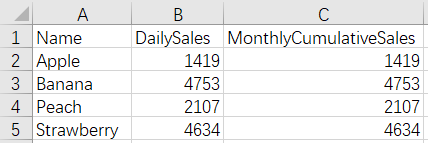
20220102.xlsx
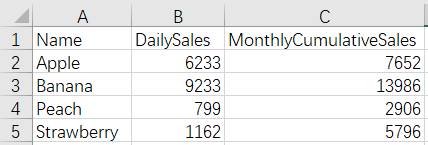
20220103.xlsx
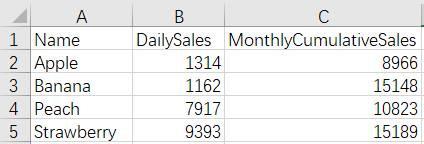
Files of other dates are omitted.
The SPL script of the operation is:
A |
B |
|
1 |
2022-01-01 |
2022-01-31 |
2 |
=periods(A1,B1).(string(~,"yyyyMMdd")+".xlsx") |
|
3 |
=A2.(T(~)) |
|
4 |
>A3(1).run(MonthlyCumulativeSales=DailySales) |
|
5 |
for A3.to(2,) |
=A5.run(MonthlyCumulativeSales=DailySales+A3(#A5).select@1(Name==A5.Name). 聽 MonthlyCumulativeSales) |
6 |
=A3.run(T(A2(#),~)) |
|
24 Aggregate files - insert aggregation sheet
A shopping mall complies a purchase summary table of key customers for 12 months of the year in the format shown below:
Jan.xlsx:
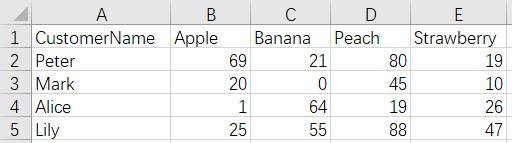
Feb.xlsx:
Files of other months are omitted.
We need to aggregate these Excel files in different sheets of one file with file names as the sheet names, and insert an aggregation sheet named “Total” on the home page.
The aggregated Excel is as follows:
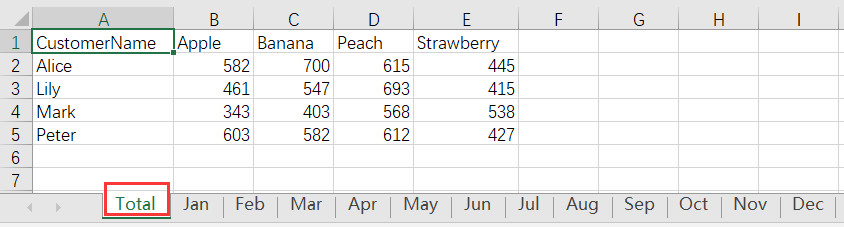
The SPL script of the operation:
A |
B |
B |
|
1 |
[Jan,Feb,Mar,Apr,May,Jun,Jul,Aug,Sep,Oct,Nov,Dec] |
||
2 |
=A1.(T(~+".xlsx")) |
||
3 |
=A2.conj().groups(CustomerName;sum(Apple):Apple, sum(Banana):Banana,sum(Peach):Peach,sum(Strawberry):Strawberry) |
/aggregate records |
|
4 |
=T("Total.xlsx",A3;"Total") |
/export T3 to the first sheet of Excel, and name it as “Total” |
|
5 |
for A2 |
=file("Total.xlsx").xlsexport@at(A5;A1(#A5)) |
/append the original data to the subsequent sheets of Excel and name them with file names, @a option means to append data |
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version