

SPL Program Cursor
In big data computing scenarios, many complicated algorithms produce concrete intermediate results that result in performance-reducing hard disk reads/writes.
Here’s an example. The account trading table trades has three fields – id (account id), dt (trading date) and amount (trading amount), and we are trying to find records having transactions for n days in a row and sum amounts by the weekday when the transaction happens.
Let’s call the first half of the computation compute1 and the second half compute2. For compute1, we sort records by account and trading date and store the sorted data before we start to get records containing n-day continuous transactions. Generally, the trading records of one account are not too many and can be wholly loaded in memory. Then we just read and retrieve the ordered records in sequence, with one account (the post-grouping subset) each time, to complete compute1 in memory.
This is not very simple. We need a few more lines to filter each retrieved grouped subset to get the eligible records. Records are ready in the memory. How should we move forward to implement the grouping and aggregation?
One near-at-hand method is to store the intermediate result concretely by exporting result data to an external temp table. Then we perform grouping and aggregation on this temp table. The following figure shows the process of writing intermediate result set to the temp table:
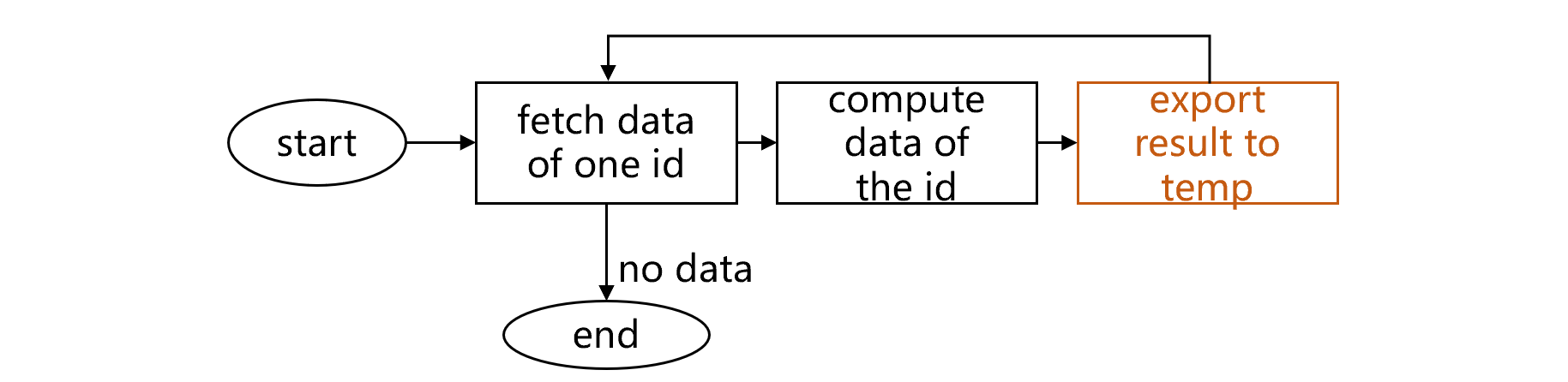
fig1 Export intermediate result to a temp table
According to the illustrated workflow, a batch of records under the same account is retrieved from the account trading table, and eligible records are selected and exported to the temp table. The loop repeats until all records are retrieved, all eligible records are exported, and compute1 is wrapped up.
We create a regular cursor on the temp table and perform grouping & aggregation to finish compute2. The workflow is shown below:
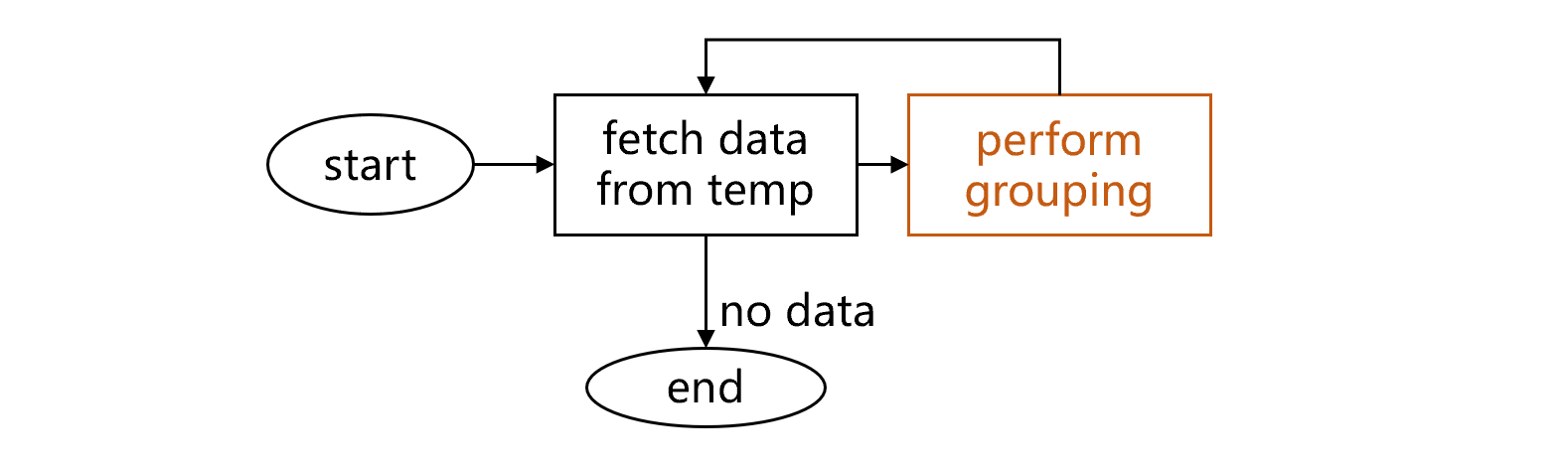
fig2 Grouping & aggregation on temp cursor
The SPL code describing workflows shown in fig1 and fig2:
A |
B |
|
1 |
=file("trades.ctx").open().cursor(id,dt,amount) |
|
2 |
for A1;id |
=A2.align@a(31,day(dt)).group@o(~==[]) |
3 |
=B2.select(~.len()>=n).conj().conj() |
|
4 |
=file("temp.btx").export@ab(B3,dt,amount) |
|
5 |
=file("temp.btx").cursor@b().groups(day@w(dt);sum(amount)) |
|
A1~B4 Accomplish compute1 represented by fig1;
A2 Loops to get each grouped subset;
B2 Aligns members of the grouped subset with the 31 days by trading date, and splits the set into continuous null subsets and continuous non-null subsets through the order-based grouping operation;
B3 Finds subsets whose lengths are greater than n, which are records that have or have not transactions for n days, and concatenates them to get the desired result (n days when no transactions happen are equivalent to empty sets that won’t affect the result set). Note that two conj() functions are used because the result of align@a is a sequence of sequences;
B4 Exports dt and amount fields of B3’s result set to the temp table;
A5 Accomplishes compute2 by creating a cursor on the temp table and performing grouping & sum on it.
The process is long because of intermediate data export to the external temporary table that involves one read and write. Actually, the data can be grouped and summarized directly to accomplish compute2, without being written to the external storage, if there is some way to do that like the following shows:
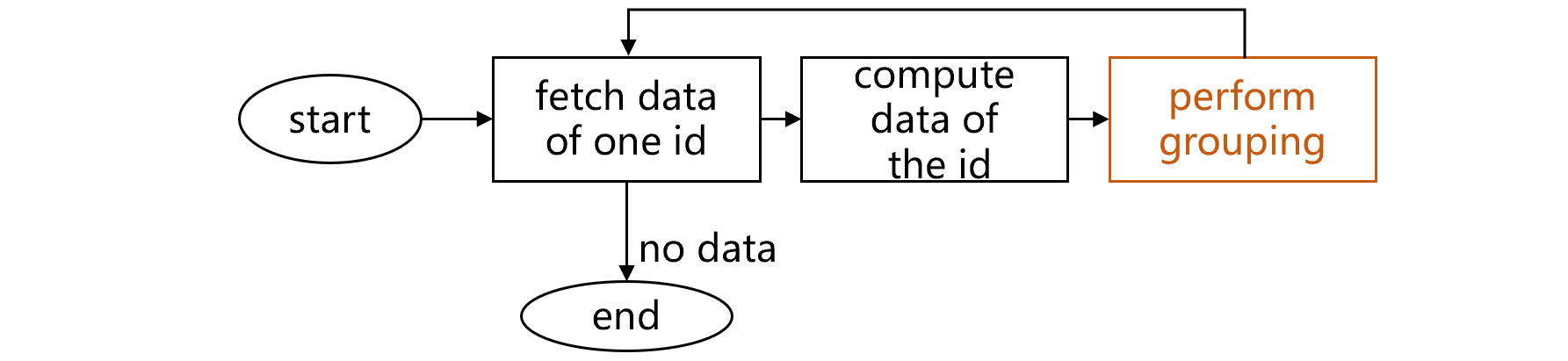
fig3 Direct grouping on intermediate data
According to the above plan, the intermediate data won’t be exported to the hard disk but will be grouped directly instead. Yet there is a complication. The grouping function operates solely on table sequence or cursor. To implement this new part of computation, we have to resort to hardcoding for each batch of records. This is complicated. It is even harder to code the direct grouping & aggregation if compute2 involves a more complicated operation than grouping.
SPL offers program cursor to achieve the above plan. The SPL mechanism simulates a cursor using the data generated by each loop.
To use the program cursor, we need to first define a subprogram func1, as shown below:
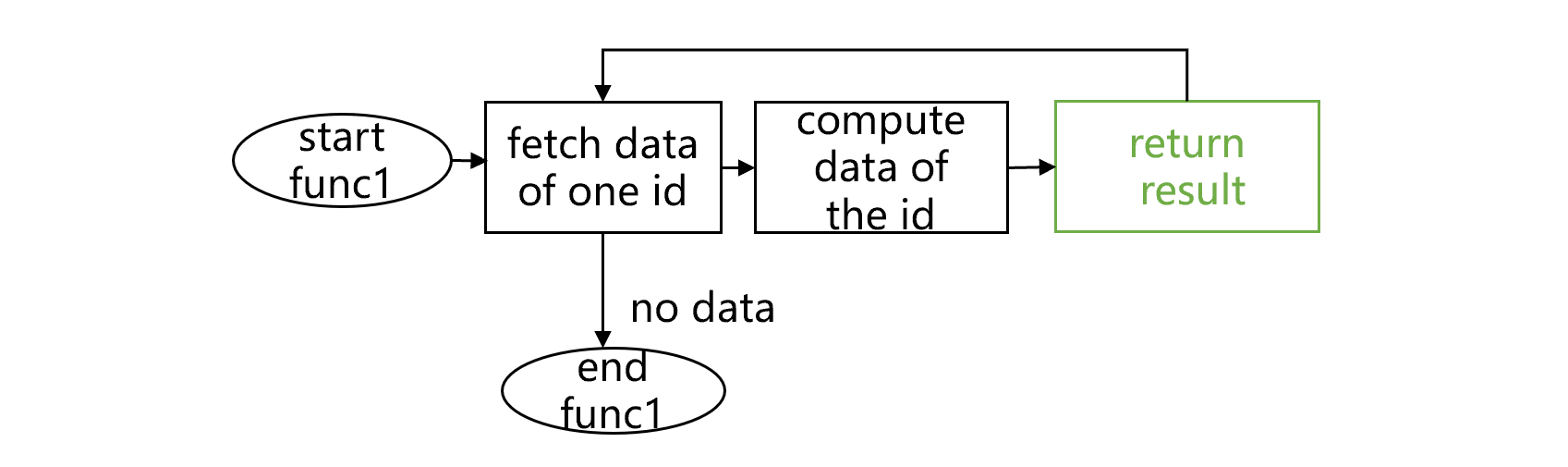
fig4 Subprogram func1
As the diagram shows, func1 returns result within a loop. Traditionally, an invoked subprogram is closed after it returns the result of computing the first subset.
But SPL program cursor mechanism has a different way of invoking a subprogram like func1. The invocation process is like this:
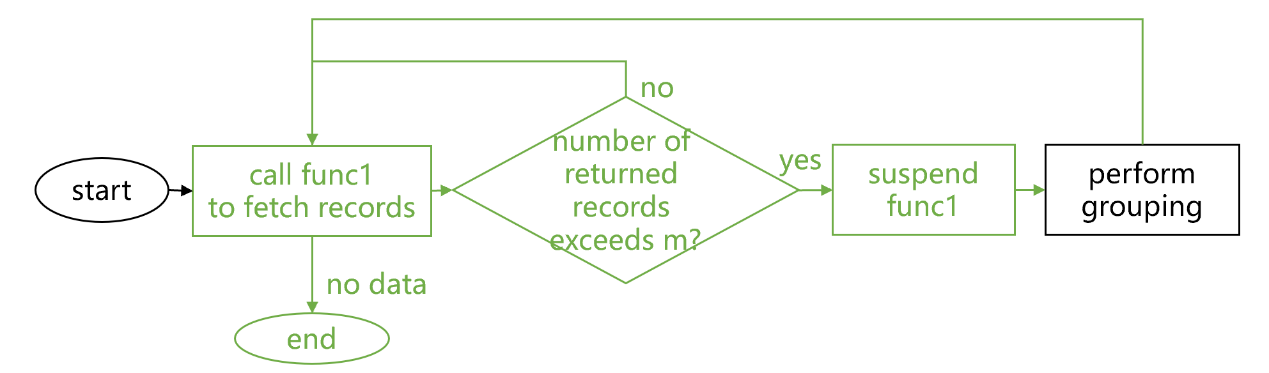
fig5 Implementation of program cursor
In fig5, the program cursor acts as an external program to invoke func1 and collect its returned results to form a cursor. When the grouping & aggregation operation in compute2 requests to fetch m records from the cursor, the program cursor mechanism begins to execute func1 and collect the returned results. Unlike regular subprogram invocation, func1 won’t be closed after it returns result (the step highlighted in green in fig4). If the number of records in the returned result set is less than m, loop of the subprogram continues; if the number reaches m, loop is suspended and result of the current fetching is returned.
func1 continues to operate and will be executed the next time a fetching request is sent, until loop is over. Then the program cursor mechanism will return and close the cursor.
During the process data generated by each loop is collected to be concatenated into a cursor rather than being written and stored to the hard disk. The mechanism enables high performance for computations with complex procedures. The assembled cursor is called program cursor.
SPL encapsulates the program cursor mechanism in cursor@c function. Below is the SPL code implementing workflows of fig4 and fig5:
A |
B |
C |
|
1 |
func |
=file("trades.ctx").open().cursor(id,dt,amount) |
|
2 |
for A1;id |
=A2.align@a(31,day(dt)).group@o(~==[]) |
|
3 |
return B2.select(~.len()>=n).conj().conj() |
||
4 |
=cursor@c(A1).groups(day@w(dt);sum(amount)) |
||
A1~C3 Implements fig4 by defining func A1, which is func1;
A4 Implements fig5 by invoking func A1 using cursor@c function to complete the program cursor’s mission.
The program cursor can be used to implement HASH-based sorting algorithm for large scale data sets. To sort the orders table by amount, for instance:
A |
B |
C |
|
1 |
func |
=file("orders.btx").cursor@b() |
=100.(file(~)) |
2 |
=B1.groupn(int(amount/100)+1;C1) |
>B1.skip() |
|
3 |
for C1 |
return B3.import@b().sort(amount) |
|
4 |
return cursor@c(A1) |
||
B2 divides orders records into 100 groups by amount (We assume that amounts are evenly distributed within the range of 0-10000; the division method can be tuned as needed as long as we ensure that the division expression and values of to-be-sorted field are monotonic non-decreasing or non-increasing and that each value of division expression match a relatively small number of records that can be loaded in memory), and returns the result of sorting each group in sequence, while cursor@c function collects the returned results to assemble a cursor.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version