

SPL: Access InfluxDB
InfluxDB is a time series database, where data is stored in its bucket and multiple buckets form an organization. Every piece of data consists of measurement, multiple dimensions, multiple filed values, and a timestamp:
airSensors, sensor_id=TLM0201 temperature=73.97038159354763, humidity=35.23103248356096, co=0.48445310567793615 1647607324916
InfluxDB provides plenty of query operations for such time series data, but its computational ability is limited because the data structure is different from that in relational database. Therefore, when the data has to be retrieved for outside-database operations, the calculation engine language–SPL–offers functions to access the data by calling InfluxDB Jave API, making the calculation relatively simpler; it also provides the Influx2_rest()function to call InfluxDB Restful API. Most of the query parameters and result data in these APIs are in CSV and JSON format, which can be easily loaded in SPL with functions like json(), cvsStr.import(), etc. These functions can load the data as an SPL table sequence, and then it is easy to do the subsequent transpositions and calculations.
There are two versions of InfluxDB Java API, 1.x and 2.x respectively, and SPL provides different functions for both of them.
Java API for InfluxDB1.x
Create/close InfluxDB connection
Similar to the JDBC connection of relational database, SPL also connects InfluxDB with paired "create/close".
influx_open(url,database,retentionPolicy, username,password), the parameters are the address of server, name of database, retention policy, user name and password in turn.
influx_close(influxConn), influxConn is the InfluxDB connection to be closed.
Code sample: A1 creates the connection, and A3 closes the connection after some other data assessing and calculating operations in the middle steps.
A |
|
1 |
=influx_open("http://127.0.0.1:8086", "esprocDB", "autogen", "admin", "admin") |
2 |
…… |
3 |
=influx_close(A1) |
Write to InfluxDB
influx_insert(influxConn, rows), rows is an SPL sequence composed of multiple rows of to-be-written data. As shown below, A2 is the to-be-written data, and A3 performs the writing:
A |
|
2 |
splTable,location=santa_monica,direct=5 water_level=2.064 1566086400000000000 splTable,location=beijing,direct=3 water_level=1.6 1568086400000000000 splTable,location=beijing,direct=7 water_level=5.5 1606086400000000000 |
3 |
=influx_insert(A1, A2.split("\n")) |
Query InfluxDB data
influx_query(influxConn,InfluxQL), influxQL is the query language of Influx:
A |
|
4 |
=influx_query(A1, "SELECT * FROM splTable") |
5 |
=influx_query(A1, "SELECT location::tag,water_level FROM splTable") |
6 |
=influx_query(A1, "SELECT * FROM splTable where location ='beijing'AND time >'2020-01-01'") |
The query result of A4 is:
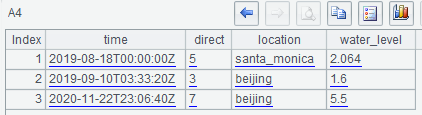
A5 selects only the location label filed and water_level value field:
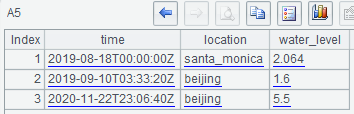
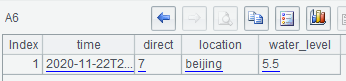
A6 sets the query condition for location and time when performing the query:
Java API for InfluxDB2.x
The functions that support InfluxDB2.x all start with influx2_.
Create/close InfluxDB connection
Similar to the JDBC connection of relational database, SPL also connects Cassandra with paired "create/close".
influx2_open(url), in the url, besides the server address and port, there can be organization, bucket, the token to authenticate identity, some timeout parameters, etc.
influx2_close(influxConn), influxConn is the InfluxDB to be closed.
Code sample: A1 creates the connection, and A3 closes the connection after some other data assessing and calculating operations in the middle steps.
A |
|
1 |
=influx2_open("http://localhost:8086?org=esprocOrg&bucket=test1&token=ZHL...fxWg==") |
2 |
…… |
3 |
=influx2_close(A1) |
Write to InfluxDB
influx2_write(influxConn, rows), rows is an SPL sequence composed of multiple rows of to-be-written data. As shown below, A2 is the to-be-written data, and A3 performs the writing:
A |
|
2 |
temperature,location=west value=51.0 temperature,location=north value=52.0 temperature,location=south value=53.0 |
3 |
=influx2_write(A1,A2.split("\n")) |
Query InfluxDB data
influx2_query(influxConn,FluxQL), FluxQL is the query language of Influx:
A |
|
4 |
=influx2_query(A1,"from(bucket:\"test1\") |> range(start: 0)") |
The return result can be multiple table sequences of different structures. For instance, A4 in the above code queries to get two table sequences:
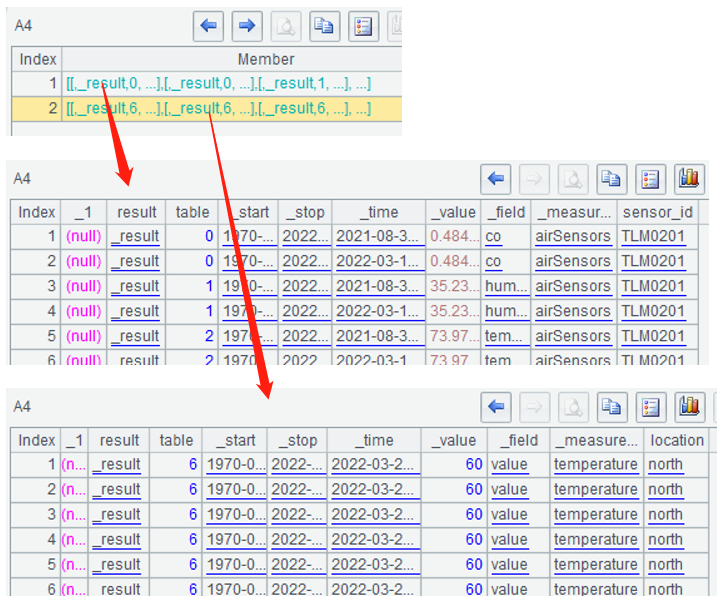
Delete InfluxDB data
influx2_delete(influxConn,beginTime,endTime,deleteStatement,bucket,organization), the parameters set the start and end time of the to-be-deleted data, the query statement, bucket and organization:
A |
|
5 |
=influx2_delete(A1,"2022-03-30 01:01:01","2022-03-31 01:01:01","","test1","esprocOrg") |
Restful method
influx2_rest(influxUrl, method, content; httpHeader1, httpHeader2, …), the first parameter is the url address; the second is HTTP method whose value may be GET/PUT/DELETE/PATCH; the third is the content submitted by HTTP quest, which can be omitted when the operation does not submit any content. After the semicolon, there are multiple HTTP headers which contain the information such as the token to authenticate the identity, specifying the content format and so on. For details like the HTTP request for each kind of Rest, which method to use, what content to submit, what HTTP header to set, etc., please refer to the official website “InfluxDB API”.
Code sample:
A |
|
1 |
>token="ZHLnRWh3GsIdALAx0……1nV5ufxWg==" |
2 |
=influx2_rest("http://localhost:8086/api/v2/buckets", "GET"; "Authorization: TOKEN"+token) |
3 |
=json(A2.Content) |
4 |
=A3.buckets.new(type,name,retentionRules.everySeconds,links.org) |
5 |
=A4.select(type=="user") |
6 |
|
7 |
airSensors,sensor_id=TLM0201 temperature=73.97038159354763,humidity=35.23103248356096,co=0.48445310567793615 1647607324916 airSensors,sensor_id=TLM0202 temperature=75.30007505999716,humidity=35.651929918691714,co=0.5141876544505826 1647607324916 |
8 |
=influx2_rest("http://localhost:8086/api/v2/write?org=esprocOrg&bucket=test1&precision=ms", "POST", A5; "Authorization: TOKEN"+token, "Content-Type: text/plain; charset=utf-8","Accept: application/json") |
9 |
|
10 |
from(bucket:"test1") |> range(start: -240h) |
11 |
=influx_rest("http://localhost:8086/api/v2/query?org=esprocOrg", "POST", A8; "Authorization: TOKEN"+token, "Content-type: application/vnd.flux","Accept: application/csv") |
12 |
=A9.Content.import@t(;",") |
There is the token to authenticate users in A1, which will be used for subsequent influx operations.
A2 queries all the buckets and lists all the HTTP response information. The returned multiple bucket information is in the Content field, which is a string in JSON format:

A3 uses the json() function to convert the JSON string into an SPL table sequence, and the layers of the table sequence are the same as the nested JSON string:
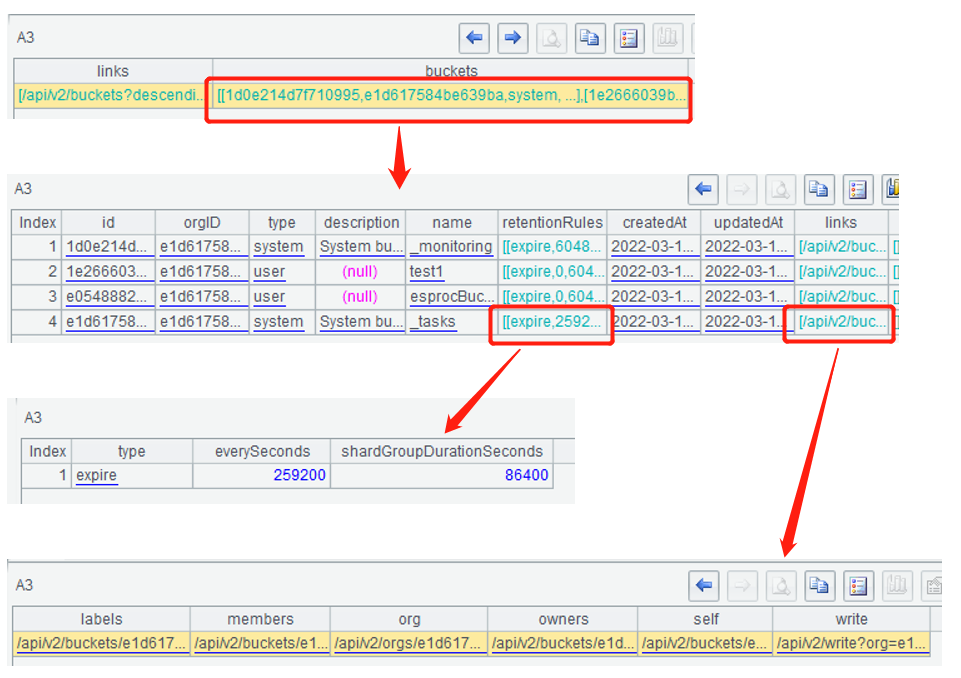
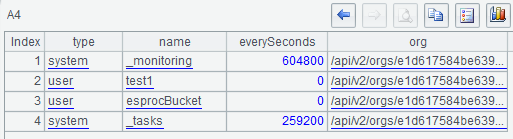
A4 selects some needed information from the nested table sequence of A3 to form a simple table sequence:
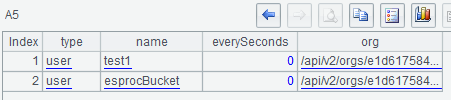
A5 uses the select() function to filter out the user-type bucket:
We can just load the data as an SPL table sequence, and then it is much easier to do subsequent operations such as filtering, grouping, sorting, calculating the union or intersection of sets, etc.
A7 is the to-be-written data, and A8 performs the write. A10 defines the InfluxDB query statement; A11 executes the query of A10, and the return result is a string in CSV format:

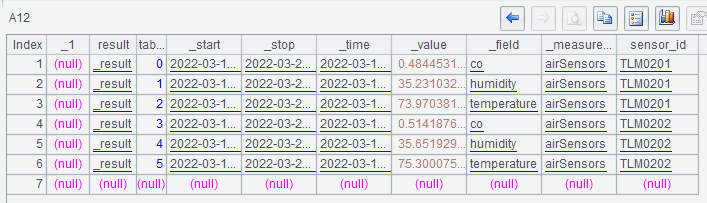
A12 uses the import() function to convert the CSV string into an SPL table sequence:
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version