

SPL Attached Table
In a large-table association scenario, if two tables are associated through their primary keys or by relating the primary key in one table to part of the primary key in the other table, we can optimize performance using SPL attached table.
The storage mechanism combines tables to be associated and stores them together. Take customer table and contact table as an example, below shows their relationship:
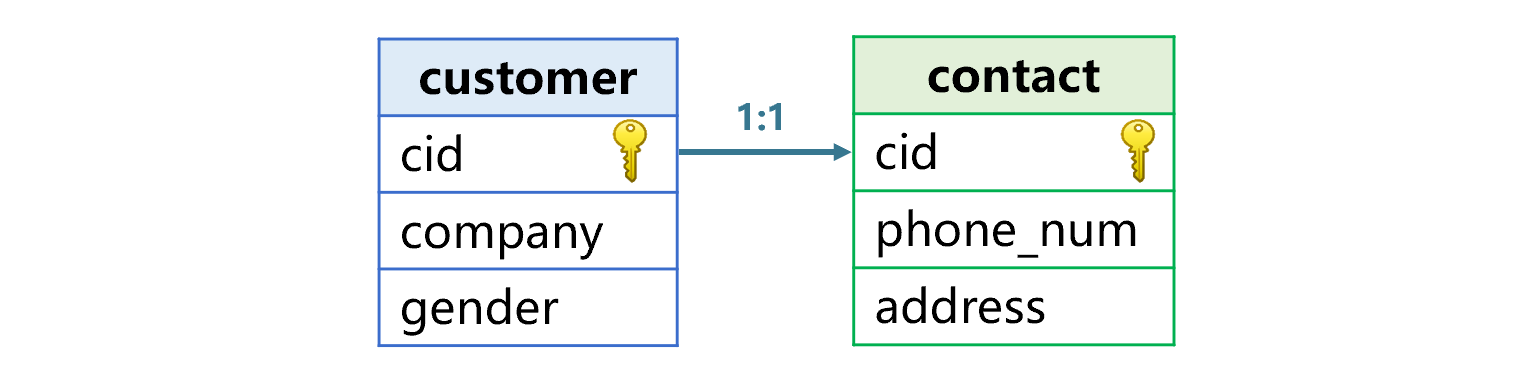
Figure 1 The relationship between customer table and contact table
The two tables are associated through their primary keys. For two tables related in this way, each one is the homo-dimension table of the other.
Below is the structure of the stored customer table and contact table using SPL attached table mechanism.
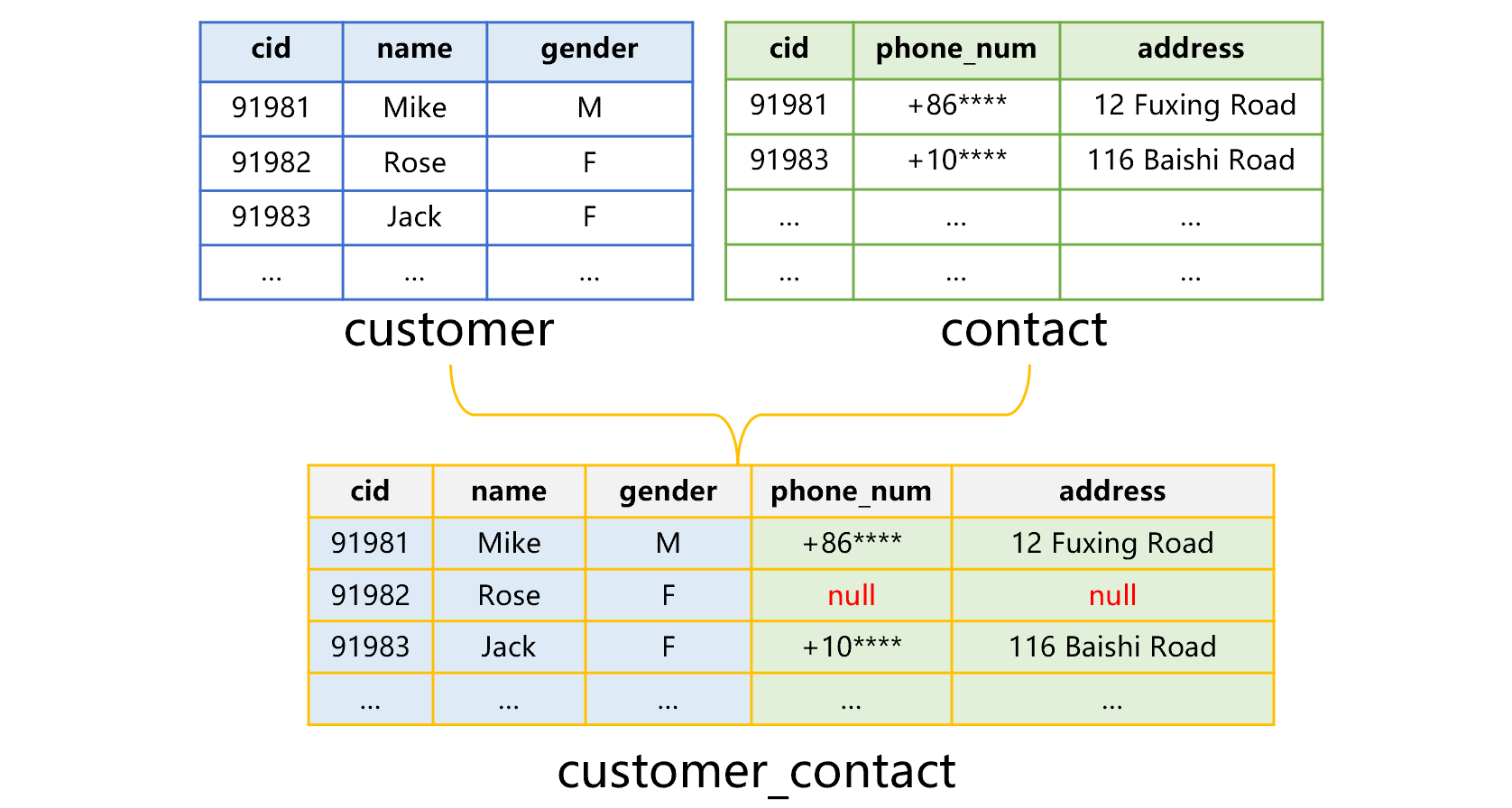
Figure 2 Structure of stored customer_contact table with attached table mechanism
The customer table stores major customer data and has the most complete values for the key cid. The contact table contains only some of cids because not all customers leave their contact information. To combine and store them together, we use the customer table as the basis, which we call base table, and the contact table as the attached table.
According to figure 2, we create the base table and store fields in the attached table as attached fields of base table records. The attached fields can be treated as fields of the base table though they are nulls in many records. The new customer_contact table is the combination of the base table and the attached table, which we call composite table. The base table and the attached table for forming the composite table are entity tables.
If there are three or more homo-dimension tables, we can store them as one base table plus multiple attached tables in the structure figure 2 shows, with only more attached fields.
The attached table storage mechanism has the following performance advantages:
1) Both the customer table (base table) and the contact table (attached table) use cid field as the primary key. The base table stores cid while the attached table, whose fields are attached to base table records, does not store it again, reducing volume of data to be stored. The column-wise storage format further decreases the data to be retrieved for the join operation.
2) A field of the attached table can be treated as an attached field of the base table records and directly referenced, like phon_num field and address field in the associated join-up table. No more matching is needed for association and thus reduces computational amount. If the base table is filtered, the attached table is filtered at the same time without being filtered separately, and vice versa.
3) Being treated as fields of the base table’s records and bound together with the base table, the attached table will be automatically and synchronously segmented when the base table is segmented. No more specific segmentation on the attached table is needed. This is convenient for achieving parallel processing that aims to speed up the computation.
Homo-dimension tables are associated through their primary keys. If their relationship is based on one table’s primary key related to part of the primary key of each of the other tables, the situation becomes complicated. The following figure shows relationship between orders table (orders), details table (details) and payment table (payment):
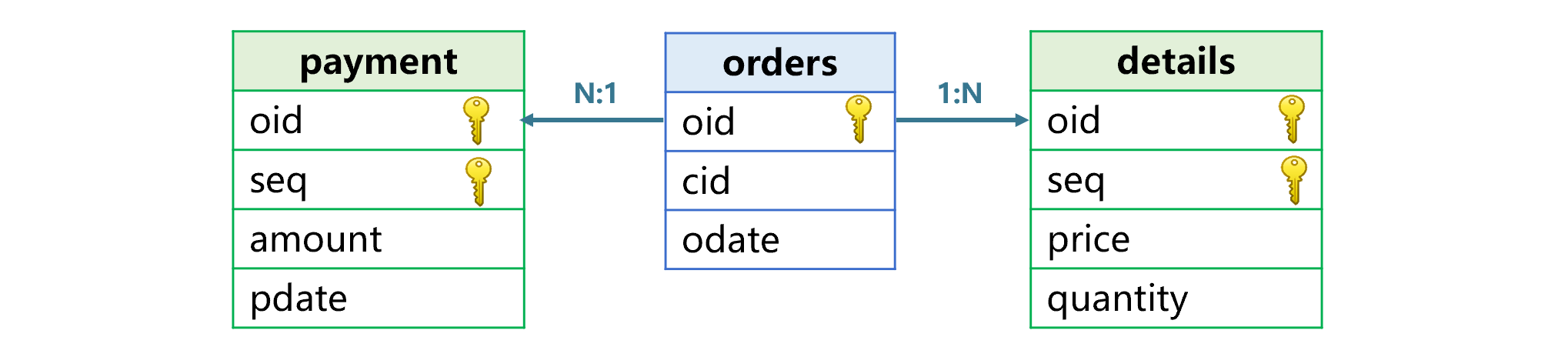 Figure 3 Relationship between orders, details and payment
Figure 3 Relationship between orders, details and payment
The three tables are associated according to orders ID oid, which is the primary key of orders table and a part of the primary key in each of the other tables. Tables having such a relationship are primary table and sub tables. Here orders is the primary table, and details and payment are sub tables.
We store data in the three tables using SPL attached table storage mechanism, as the following shows:
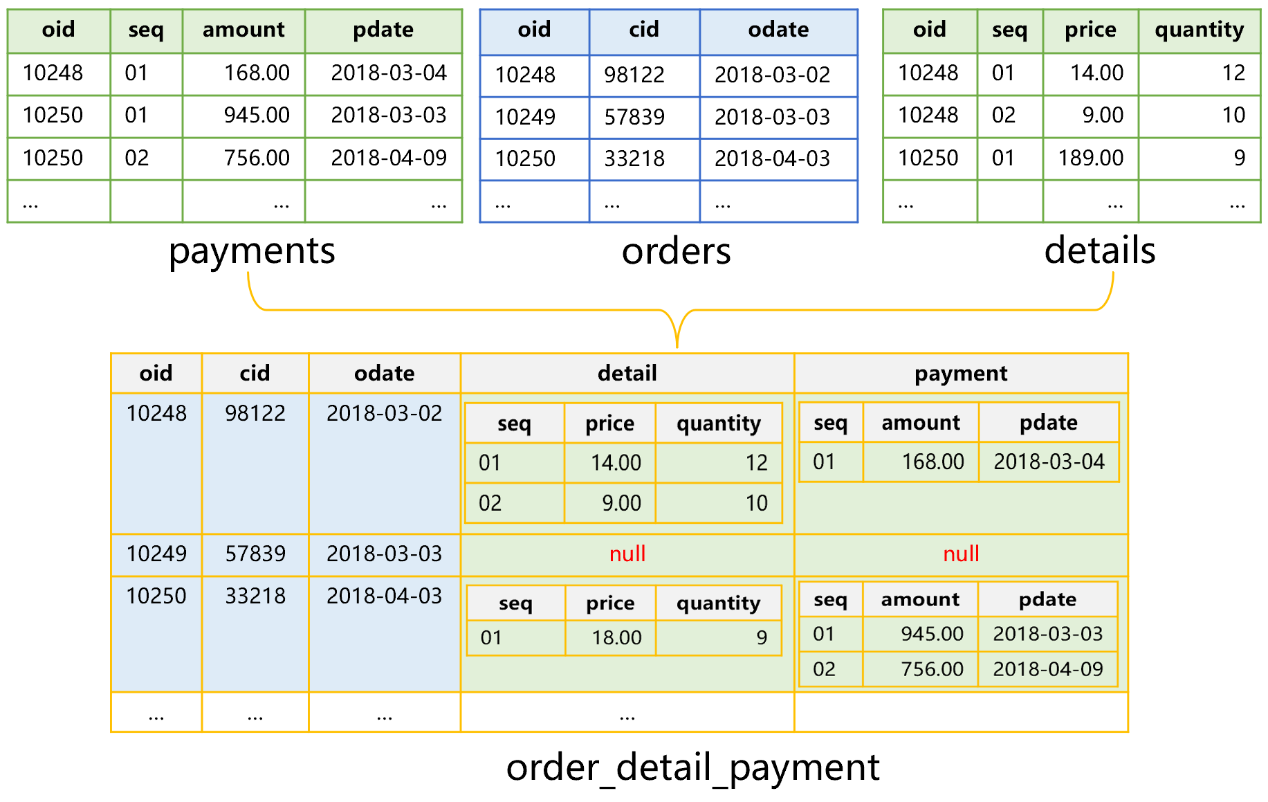
Figure 4 Store order_detail_payment table with attached table mechanism
In this case, we make the primary table the base table and the sub tables attached tables. According to figure 4, we create the base table first, and attach fields of each attached table to records of the base table. Since one orders record corresponds to multiple details/payment records, each attached field has values that are sets. Attached fields coming from the same attached table contain set type values of same lengths. The price field and quantity field in attached table details have same-length set type values. The attached fields could also be nulls.
Using attached table mechanism to store primary table and sub table(s) can bring about the same performance advantaged mentioned above. But as values of the attached fields are sets, the way of referencing an attached field by the base table is different.
Yet, storing homo-dimension tables and the primary and sub table(s) with attached table mechanism has its disadvantages. The complicated storage plan adds extra judges when the base table references an attached field.
The attached table storage mechanism increases performance noticeably particularly when the primary key-based relationship is complex, like the case where both the customer table and the contact table have a composite primary key or the case where the orders-details’s 1:N relationship has a much larger N. Both involve much more comparison operations if tables are joined in the conventional method.
If it is the simple one-to-one, primary-key-based relationship, the attached table mechanism gives little help to performance enhancement, and even has negative impact on performance. So, make sure you use the mechanism for the right scenarios.
In theory, the attached table in the primary-sub table relationship can have its own attached table(s). But it is rarely seen.
To implement the attached table storage mechanism on a composite table, we need to specify the attached fields when creating the composite table. Take the order_detail_payment table as example, the code is as follows:
A |
B |
|
1 |
=file("orders.ctx").open().cursor() |
|
2 |
=file("details.ctx").open().cursor() |
=file("payments.ctx").open().cursor() |
3 |
=file("order_detail.ctx").create(#oid,cid,odate) |
|
4 |
=A3.attach(detail,#seq,price,quantity) |
=A3.attach(payment,#seq,amount,pdate) |
5 |
=A3.append@i(A1) |
|
6 |
=A4.append@i(A2) |
=B4.append@i(B2) |
A3 creates an ordinary composite table. A4 adds an attached table to A3 while specifying name of the attached table, which is detail here, and attached fields.
Since the relation is primary table and sub tables, we need to set the primary key for the sub table detail, which is seq. As oid is the common primary key, it is unnecessary to write it explicitly.
B4 continues to add attached table payment to A3.
A5, A6 and B6 perform ordinary data appending. SPL will attach fields to the corresponding records of the base table according to the attached table’s primary key.
Make note that, besides primary keys, other fields in the base table and attached table(s) are not allowed to have fields of same name in order to prevent confusion.
After a composite table having an attached table is created, we can reference an attached field during the computation. The relevant SPL code is as follows:
A |
|
1 |
=file("order_detail.ctx").open() |
2 |
=A1.cursor(odate,detail.sum(quantity):quantity,payment.sum(amount):amount) |
3 |
=A2.groups(odate;sum(quantity),sum(amount)) |
Or we can recover records of a sub table:
A |
|
1 |
=file("order_detail.ctx").open() |
2 |
=A1.cursor(odate,detail{price,quantity}:amount) |
3 |
=A2.run(amount=amount.sum(price*quantity)) |
4 |
=A3.groups(odate;sum(amount)) |
Since there is more than one corresponding record in a sub table, the recovered records will become a field of the primary table cursor, whose value is a table sequence. But, generating a table sequence is complicated and will offset the performance increase brought about by reducing joining actions.
We can also reference a base table field in the attached table:
A |
|
1 |
=file("order_detail.ctx").open().attch(detail) |
2 |
=A1.cursor(odate,price,quantity) |
3 |
=A2.groups(odate;sum(price*quantity)) |
Just write the base table field directly. This performance is better than that of the above method that generates sequence type fields
All those operations support multi-cursors.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version