

Open-source SPL Eliminates Tens of Thousands of Intermediate Tables from Databases
Intermediate tables are data tables in databases specifically used to store intermediate results generated from processing the original data – which is why they are so named. They are summary tables usually created for speeding up or facilitating the front-end queries and analysis. For some large organizations, years of accumulation results in tens of thousands of intermediate tables, which is an incredible number, in their databases, bringing great trouble to database operation and usage.
The large number of intermediate tables occupies too much database storage space, putting enormous pressure on storage capacity and increasing demand for capacity expansion. But database space is expensive and capacity expansion is exceedingly costly. Moreover, often there are restrictions on the expansion. It is not a good choice to cost you an arm and a leg with storing intermediate tables also because too many of them reduce database performance. Intermediate tables are not created out of thin air. Rather, they are generated from the original data through a series of computations that consume database computing resources. Sometimes, a lot of intermediate tables are produced during a computation. This consumes a large number of resources, and in serious cases, can slow down queries and transactions.
Why are there so many intermediate tables? Below are main reasons:
1. More than one step is needed to get the final result
The original data table needs to undergo complicated computations before being displayed in a report. It is hard to accomplish this with one SQL statement but with multiple, continuous SQL statements. One statement generates an intermediate result that will be used by the next statement.
2. Long wait time in real-time computations
For data-intensive and compute-intensive tasks, the wait time will be extremely long. So, report developers choose to run batch tasks at night and store results in intermediate tables. It is much faster to perform queries based on the intermediate tables.
3. Diverse data sources in a computation
Files, NoSQL and Web service almost do not have computing abilities. Data originated from them needs to be computed using the database’s computing ability. With a mixed computation between such data and data stored in the database particularly, the traditional approach is to load the external data into the database and store it as intermediate tables.
4. Intermediate tables are hard to get rid of
As databases uses flat structure to arrange tables, it is very likely that one intermediate table is shared by multiple queries after it is created. Deleting it for a finished query could affect other queries. Worse still, you cannot know exactly which applications are using this intermediate table. This makes deletion impossible, not because you do not want to get rid of it, but because you dare not do it. The consequence is that tens of thousands of intermediate tables are accumulated in the database over time.
But why we use databases to store intermediate data? According to the above causes of intermediate tables, the direct aim for storing intermediate data in the database as intermediate tables is to employ the database’s computational ability. The intermediate data will be further computed for subsequent use, and sometimes the computation is rather complicated. Now only databases (which are SQL-driven) have relatively convenient computing ability. Other storage formats like files have their own merits (high I/O performance, compressible and easy to be parallelly processed) though, they do not have computing abilities. If you try to perform computations based on files, you need to hardcode them in applications. That is far less convenient than using SQL. So, to make use of databases’ computing abilities is the essential reason of the existence of intermediate tables.
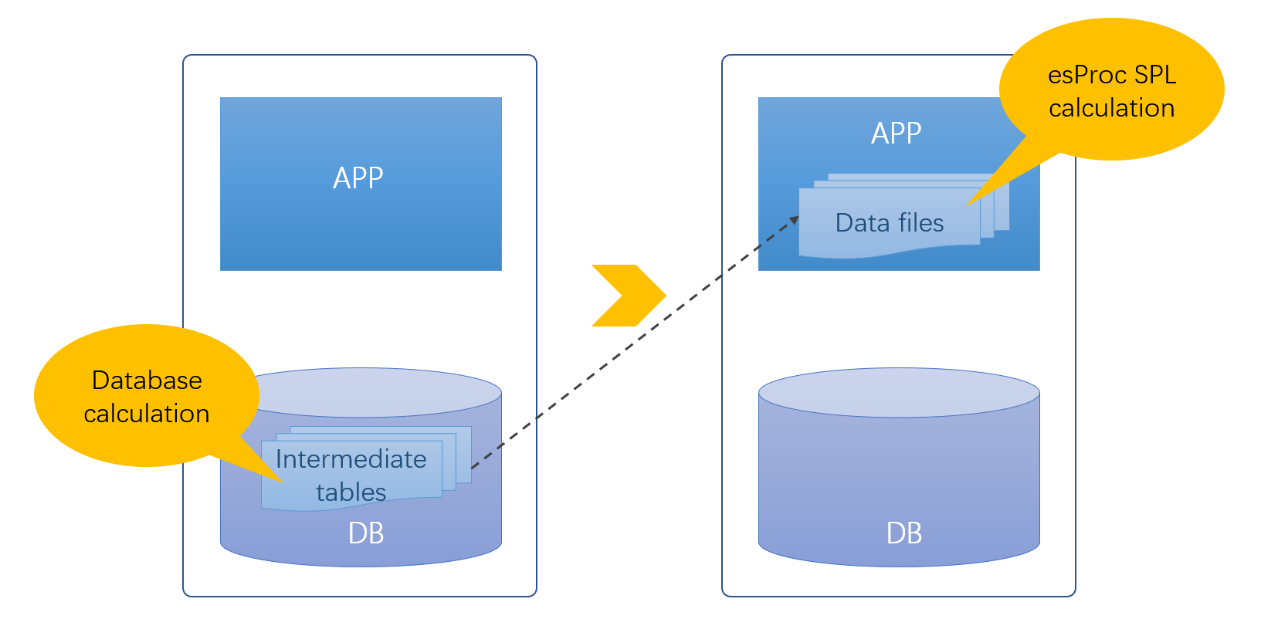
In some sense intermediate data is necessary. But consuming a huge amount of database resources in order to get only more computing ability is obviously not a good strategy. If we can enable files to have equal computing ability and store intermediate data in the outside-database file system, then problems related to intermediate tables will be solved and databases will be unburdened from or relieved of overload.
The open-source SPL can help to turn it into reality.
SPL is an open-source structured data computation engine. It can process data directly based on files, giving files the computing ability. It is database-independent, offers specialized structured data objects and a wealth of class libraries for handling them, possesses all-around computational capability, and supports procedural control that makes it convenient to implement complex computing logics. All these features qualify SPL to replace databases in handling intermediate data and subsequent data processing.
SPL file-based computations
SPL can perform computations directly based on files like CSV and Excel and multilevel data JSON and XML. It is convenient to read and handle them in SPL. We can store intermediate data in one of those file formats and handle it in SPL. Below are some basic computations:
A |
B |
|
1 |
=T("/data/scores.txt") |
|
2 |
=A1.select(CLASS==10) |
Filter |
3 |
=A1.groups(CLASS;min(English),max(Chinese),sum(Math)) |
Group & Aggregate |
4 |
=A1.sort(CLASS:-1) |
Sort |
5 |
=T("/data/students.txt").keys(SID) |
|
6 |
=A1.join(STUID,A5,SNAME) |
Join |
7 |
=A6.derive(English+ Chinese+ Math:TOTAL) |
Append a column |
On top of native syntax, SPL even offers supports of SQL92 standard, allowing programmers familiar with SQL to query files directly in SQL.
$select * from d:/Orders.csv where Client in ('TAS','KBRO','PNS')
Support of complicated WITH clause:
$select t.Client, t.s, ct.Name, ct.address from
(select Client ,sum(amount) s from d:/Orders.csv group by Client) t
left join ClientTable ct on t.Client=ct.Client
SPL has the edge on handling multilevel data like JSON and XML. To perform computations based on orders data of JSON format, for instance:
A |
||
1 |
=json(file("/data/EO.json").read()) |
|
2 |
=A1.conj(Orders) |
|
3 |
=A2.select(Amount>1000 && Amount<=3000 && like@c(Client,"*s*")) |
Conditional filtering |
4 |
=A2.groups(year(OrderDate);sum(Amount)) |
Grouping & aggregation |
5 |
=A1.new(Name,Gender,Dept,Orders.OrderID,Orders.Client,Orders.Client,Orders.SellerId,Orders.Amount,Orders.OrderDate) |
Join |
The SPL implementation is concise compared with that in other JSON libraries (like JSONPath).
SPL also allow users to query the JSON data directly in SQL:
$select * from {json(file("/data/EO.json").read())}
where Amount>=100 and Client like 'bro' or OrderDate is null
SPL is particularly suitable for handling complex computing logics with its agile syntax and procedural control ability. To count the longest continuous days when the price of a stock rises based on stock records of txt format, for instance, SPL has the following code:
A |
|
1 |
=T("/data/stock.txt") |
2 |
=A1.group@i(price<price[-1]).max(~.len())-1 |
One more instance. To list the latest login interval for each user according to user login records of CSV format:
A |
||
1 |
=T(“/data/ulogin.csv”) |
|
2 |
=A1.groups(uid;top(2,-logtime)) |
Get records of the last two logins |
3 |
=A2.new(uid,#2(1).logtime-#2(2).logtime:interval) |
Calculate the interval |
Such computing tasks are hard to code even in SQL in databases. Yet they become easy when handled in SPL.
The outside-database computing ability SPL supplies is an effective solution to problems triggered by too many intermediate tables in databases. Storing intermediate data in files releases database space resources, reduces demand for database expansion and makes database management more convenient. The outside-database computations do not take up database computing resources, and the unburdened database will be able to better serve other transactions.
High-performance file formats
Text files are commonly used data storage format. They are general-purpose and easy to read, but, at the same time, they have extremely bad performance. Traditionally, text-based computations are hard to have satisfactory performance.
Text characters cannot be computed directly. They need to be transformed to in-memory data types like integers, real numbers, dates and strings to be able to be processed. Yet text parsing is extremely complicated and takes exceptional long CPU time. Generally, hard disk reading takes up most of the time in accessing data on external storage, and text files’ performance bottle usually happens in the phase of data handling by CPU. Because of too complicated parsing, it is probably that the CPU time is greater than the hard disk reading time (especially with the high-performance SSD). So, text files are usually not used to process big data when high performance is demanded.
SPL provides two high-performance binary storage formats – bin file and composite table. A bin file uses the binary format, is compressed (to occupy less space and allow fast retrieval), stores data types (to enable faster retrieval without parsing), and supports the double increment segmentation technique to divide an append-able file, which facilitates parallel processing in an effort to further increase computing performance.
The composite table is a file storage format SPL uses to provide column-wise storage and indexing mechanism. It displays great advantage in handling scenarios where only a very small number of columns (fields) is involved. A composite table is equipped with the min-max index and supports double increment segmentation technique, letting computations to both enjoy the advantages of column-wise storage and be more easily parallelly processed to have better performance.
The two high-performance file formats are convenient to use, and have basically the same uses as text files. To read a bin file and compute it, for instance:
A |
B |
|
1 |
=T("/data/scores.btx") |
Import a bin file |
2 |
=A1.select(CLASS==10) |
Filter |
3 |
=A1.groups(CLASS;min(English),max(Chinese),sum(Math)) |
Group & summarize |
When the size of data to be processed is large, SPL can use cursor to perform batch retrieval and multi-CPU-based parallel processing:
=file("/data/scores.btx").cursor@bm()
When using files to store data and no matter which format the original data uses, they need to be at least converted to the binary format (like bin file) to get more advantages in both space usage and computing performance.
Ease of management
Moving intermediate data out of database to file system can not only reduce database workload but make the data extremely easy to manage. Files can be stored in operating system’s tree-structure directories. This makes them convenient to use and manage. It is neat and tidy to place intermediate tables used by different systems and modules in separate directories. This completely eliminates shared reference and thus the long-standing issue of tight coupling between systems and modules due to messy use of intermediate tables in the database. Now intermediate tables can be safely deleted without any harmful effects when corresponding modules are not used any more.
Support of diverse data source
In addition to the file sources, SPL can connect to and retrieve data from dozens of other data sources as well as perform mixed computations between different sources.

After intermediate data is stored in files, we face cross-data-source computations when trying to perform full-data queries between the file and the database holding the real-time data. It is convenient to implement these T+0 queries in SPL:
A |
||
1 |
=cold=file(“/data/orders.ctx”).open().cursor(area,customer,amount) |
/ Retrieve data before the current day, which is the cold data, from the file system (which uses SPL high-performance storage format) |
2 |
=hot=db.cursor(“select area,customer,amount from orders where odate>=?”,date(now())) |
/ Retrieve data of the current day, which is the hot data, from the production database |
3 |
=[cold,hot].conjx() |
|
4 |
=A3.groups(area,customer;sum(amout):amout) |
/ Perform mixed computation to achieve T+0 query |
Ease of integration
SPL provides standard JDBC driver and ODBC driver for invocation by an application. For a Java program, the SPL code can also be integrated into it as an embedded computing engine, enabling the latter to have the ability to handle intermediate data.
Sample of invoking SPL code through JDBC:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement st = connection.();
CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
…
SPL is interpreted execution and naturally supports hot-swap. Data computing logics written in SPL and their modification, operation and maintenance take effect in real-time without the need of restarting the application, making programs’ development, operation and maintenance convenient and efficient.
With SPL that offers outside-database computational capability, we can transfer intermediate tables to files, getting rid of the numerous of them from databases. This helps to relieve databases of overload and make it faster, more flexible and more scalable.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version