

4.14 Merge and de-duplicate by row - duplicate row headers - keep the data that firstly appear
When merging multiple Excel files by row, we may use only the row headers or one/several key columns as the criteria for judging whether data are duplicated. As shown in the following example where Name is used as the criterion for judging duplication:
Before merging:
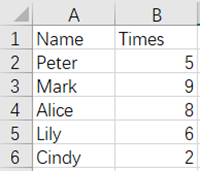
and
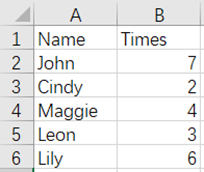
From the above figures, Cindy and Lily are the duplicate data in the Name field, and the merged result is as follows:
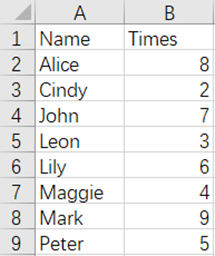
Script:
| A | |
|---|---|
| 1 | =file(“Customer1.xlsx”).xlsimport@t().sort(Name,Times) |
| 2 | =file(“Customer2.xlsx”).xlsimport@t().sort(Name,Times) |
| 3 | =[A1,A2].merge@u(Name) |
| 4 | =file(“CustomerTimes.xlsx”).xlsexport@t(A3) |
A1: The original data need to be sorted because of merge
A3: merge@u means the union, using Name as criteria for judging duplication
esProc Desktop and Excel Processing
4.13 Merge and de-duplicate by row - duplicate whole row of data
4.15 Merge and de-duplicate by row - duplicate row headers - keep non-null data
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_Desktop/
SPL Learning Material 👉 https://c.scudata.com
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProcDesktop
Linkedin Group 👉 https://www.linkedin.com/groups/14419406/

