

The Data Lake’s Impossible Triangle
A brief introduction to data lake
Let’s start with data warehouse. A data warehouse is a subject-oriented data management system that aggregates data from different business systems and is intended for data query and analysis. As data expands and the number of business systems increases, data warehousing becomes necessary. In order to meet the business requirements, the raw data needs to be cleansed, transformed and deeply prepared before being loaded into the warehouse. Answering the existing business questions is the data warehouse’s core task. Those questions must be already defined.
But what if a business question is not defined (which is potential data value)? According to the data warehouse’s rule, a business question is asked first and then a model is built for it. The chain of identifying, raising and answering questions thus becomes very long. On the other hand, the data warehouse, as it stores highly prepared data, has to obtain desired data by processing the raw data when the new question requires fine data granularity. This is extremely cost-ineffective. If there are many such new questions, a query process will be overburdened.
So, in the context of this background, the data lake was born. It is a technology (or strategy) intended to store and analyze massive amounts of raw data. It enables to load as much raw data as possible into the data lake while keeping the highest fidelity as possible in storing it, and, in theory, extracting any potential data value based on full data. Speaking of this, the data lake’s two roles are absolutely obvious. One is data storage because the data lake needs to keep all raw data. The other is data analysis, which, from the technical point of view, is data computing, or the value extraction process.
Let’s look at the data lake’s performance in the two aspects.
The data lake stores full raw data, including structure data, semi-structured data and unstructured data, in its original state. The capacity of storing massive and diverse data is thus the data lake’s essential feature, which is different from the data warehouse that often uses databases to store structured data. Besides, loading data into the lake as early as possible helps fully extract value from association of differently themed data and ensure data security and integrity.
The good news is that the massive raw data storage needs can be fully met thanks to the great advance of storage and cloud technologies. Enterprises can choose self-built storage cluster or the storage service provided by a cloud vendor to deal with their business demands.
But, the toughest nut to crack is data processing! The data lake stores various types of data and each needs to be processed differently. The central and the most complicated part is structured data processing. With both historical data and newly generated business data, data processing mainly focuses on structured data. On many occasions, computations of semi-structured data and unstructured data will eventually be transformed to structured data computations.
At present, SQL-based databases and related technologies, which are also the abilities data warehouses have, dominate structured data processing field. In other words, the data lake depends on data warehouses (databases) to compute structured data. That is nearly all data lake products do. Building the data lake to store all raw data and then the data warehouse to add data processing capability catering to business needs of enterprises. As a result, data in the lake needs to be loaded to the data warehouse again through ETL. An advanced approach automates the process to some degree. The approach identifies data in the lake that needs to be loaded to the warehouse and performs the loading while the system is idle. This is the main functionality of the currently hot concept of Lakehouse. But, no matter how data is loaded to the warehouse (including the extremely inefficient method that lets the warehouse access data lake through the external table), today’s data lake is made up of three components – massive data storage, data warehouse and a specialized engine (for, like, unstructured data processing).
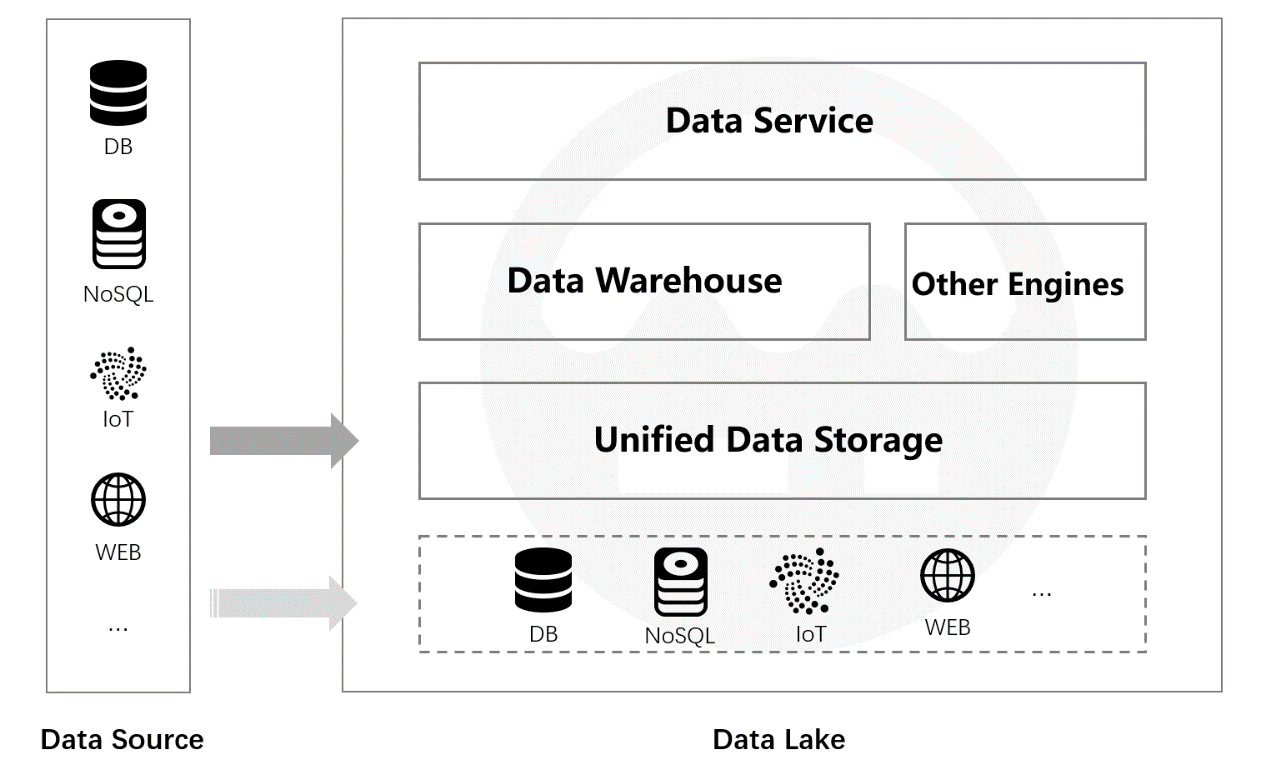
There are problems about this type of data lake framework.
The impossible triangle
Data lakes are expected to meet three key requirements – storing data in its original state (loading high fidelity data into the lake), sufficient computing capacity (extracting the maximum possible data value) and cost-effective development (which is obvious). The current technology stack, however, cannot achieve all the three demands at the same time.
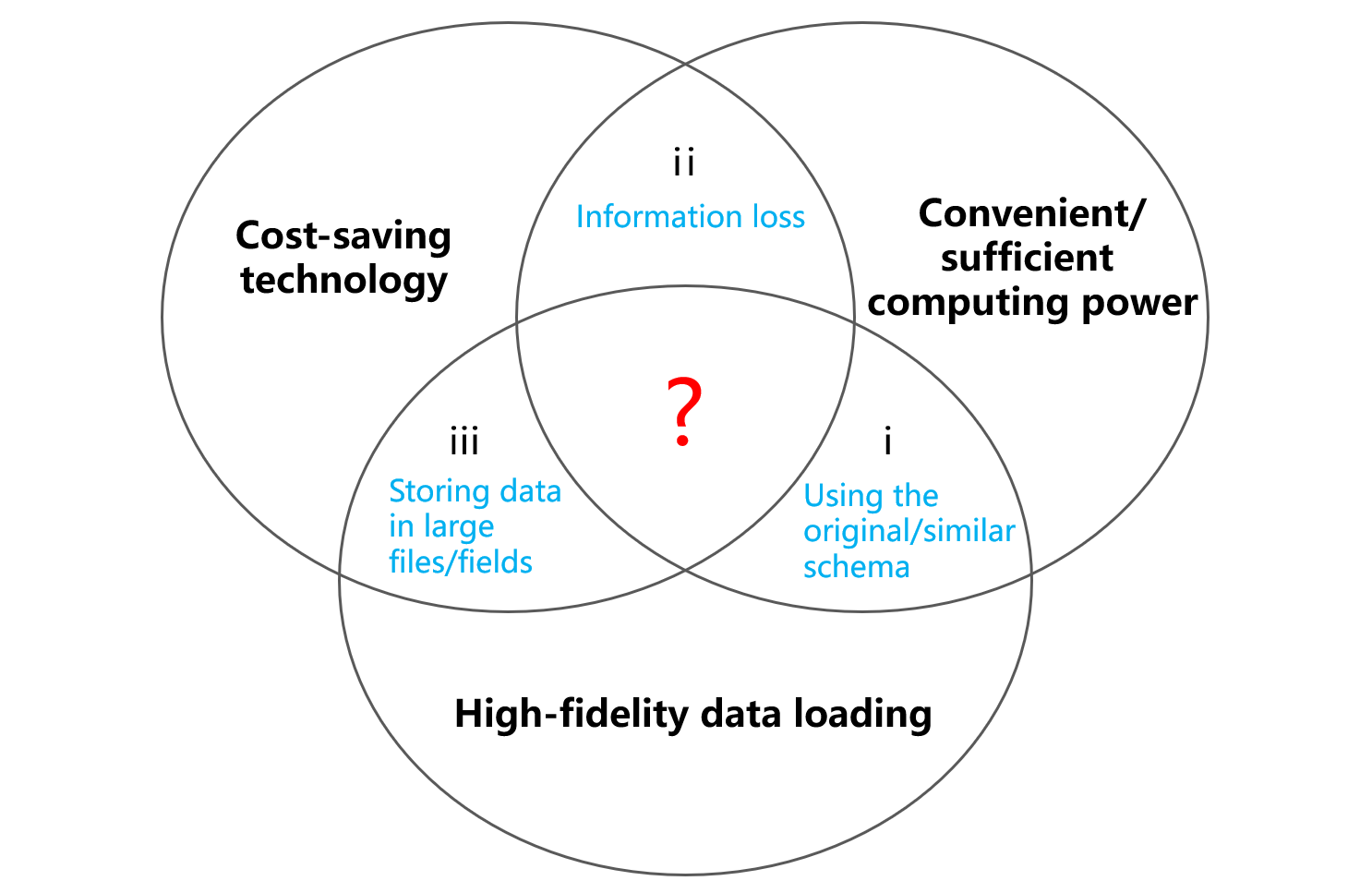
Storing data as it is was the initial purpose of building the data lake because keeping the original data unaltered helps to extract the maximum value from it. The simplest way to achieve the purpose is that the data lake uses a completely same storage medium to store data loaded from the source. There will be, for instance, a MySQL to hold data originally stored in MySQL, a MongoDB to receive data initially stored in MongoDB, and so on. This helps load data into the lake in as hi-fi format as possible and make use of the source’s computing ability. Though achieving computations across data sources is still hard, it is enough to handle computations only involving the current source’s data, meeting the basic requirement of sufficient computing power (as part i in the above figure shows).
But the disadvantage is noticeable – the development is too expensive. Users need to put same storage mediums in place and copy all data sources accumulated over years to them. The workload is ridiculously heavy. If a data source is stored with commercial software, purchasing the software further pushes up the development cost. A relief strategy is to use a storage medium of same type, like storing Oracle data in MySQL, but it brings a side effect while the costs still stay high – some computations that could have been handled could become impossible or hard to achieve.
Now, let’s lower the bar. We don’t demand that data be duplicated at loading but just store data in the database. By doing this, we obtain the database’s computing ability and meet the requirement of cheap development (as part ii in the above figure shows) at the same time. But this is infeasible since it heavily depends on one relational database into which all data needs to be loaded.
Information may be easily lost during the loading process, which will fall short of the first requirement of building the data lake (loading high-fidelity data into the lake). Storing MongoDB data in MySQL or Hive is hard, for instance. Many MongoDB data types and relationships between sets do not exist in MySQL, such as the set data type like nested data structure, array and hash, and the instances of many-to-many relationship. They cannot be simply duplicated in the course of data migration. But rather, certain data structure needs to be restructured before the migration. That requires a series of sophisticated data reorganization steps, which is not cost-effective but needs a lot of people and time to sort out the business target and design appropriate form of target data organization. Without doing this, information will be lost, and errors, in turn, appear during the subsequent analysis. Sometimes errors are too deeply hidden to be easily visible.
A general approach is to load data unalterably into large files (or as large fields in the database). This way the information loss is within an acceptable range and data basically remains intact. File storage has many advantages. It is more flexible, more open, and has higher I/O efficiency. Particularly, storing data in files (or in a file system) is cheaper.
Yet, the problem of file storage is that files/large fields do not have computing capacity, making it impossible to meet the requirement of convenient/sufficient computing power. It seems that the impossible triangle is too strong to break.
No approach can resolve the conflict between the demand for storing data in its initial state and the convenient use of it. Under the requirement for cost-saving lake building (loading data to the lake fast), high fidelity data loading and convenient/sufficient computing power are mutually exclusive. This goes against the data lake’s goal of openness.
The underlying cause of the conflict is the contradiction between the closed database and its strict constraints. The database requires that data be loaded into it for computations and data needs to meet certain database constraints before being able to be loaded. In order to conform to the rules, data needs to be cleansed and transformed. And information loss happens during the process. Abandoning databases and switching to other routes (like files) cannot satisfy the demand of sufficient computing power, except that you turn to hardcoding. But hardcoding is too complicated and not nearly as convenient as databases.
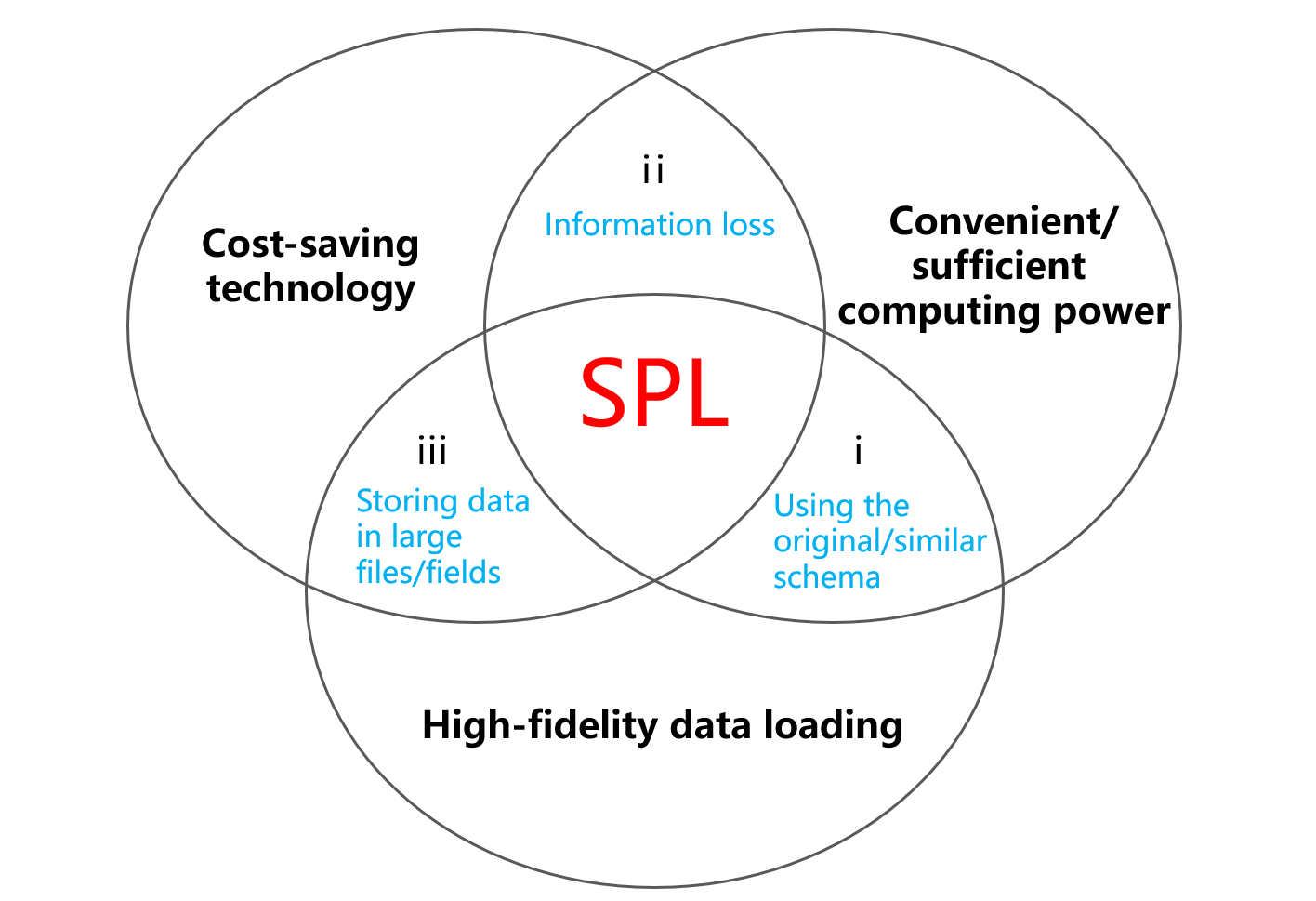
Actually, an open computing engine can become the breaker of the impossible triangle. Such an engine possessing sufficient and convenient computing power can compute the raw data, including data stored in diverse data sources, in real time.
SPL – the open data lake computing engine
The open-source SPL is a structured data computing engine that provides open computing power for data lakes. It has diverse-source mixed computing capability that enables to compute raw data stored in different sources directly and based on its original status. No matter which storage mediums the data lake uses – same types as data sources or files, SPL can compute data directly and perform the data transformation step by step, making the lake building easier.
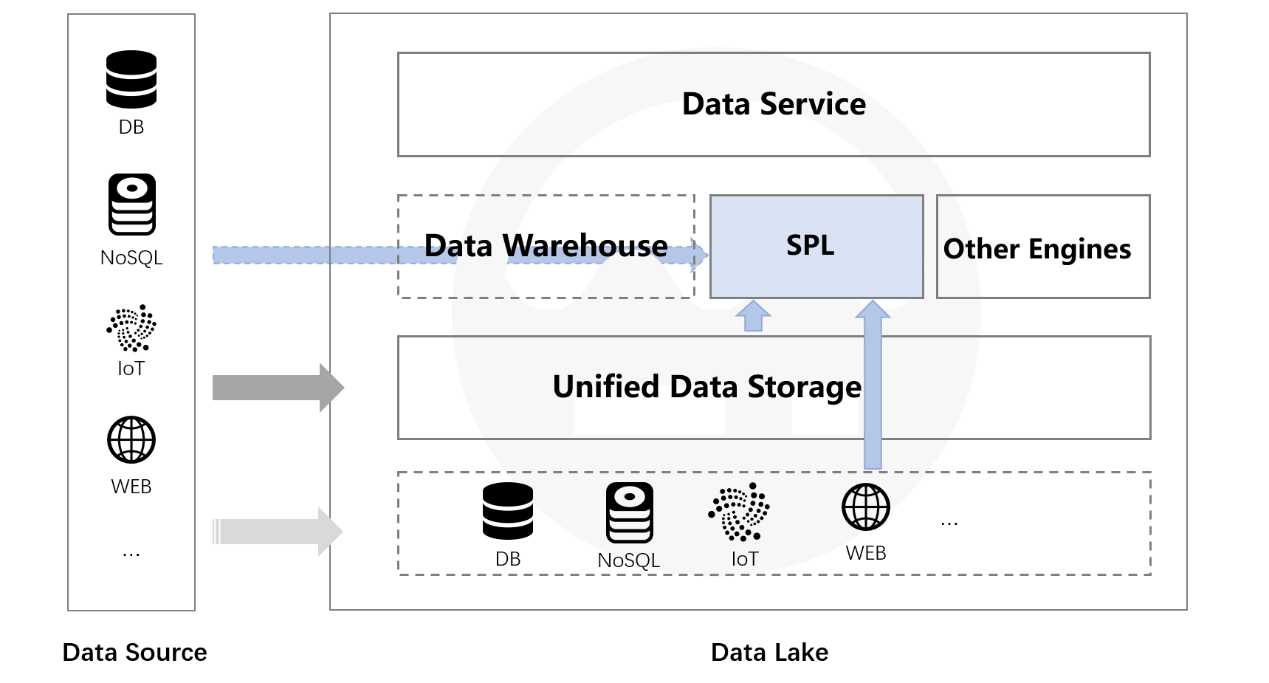
Open and all-around computing power
Diverse-source mixed computing ability
SPL supports various data sources, including RDB, NoSQL, JSON/XML, CSV, Webservice, etc., and mixed computations between different sources. This enables direct use of any type of raw data stored in the data lake and extraction of its value without the “loading” step and preparation. And this flexible and efficient use of data is just one of the goals of data lakes.

Being agile like this, the data lake will be able to provide data services to applications as soon as it is established rather than after the prolonged cycle of data preparation, loading and modeling. The more flexible data lake service enables real time response to business needs.
Particularly, SPL’s good support for files gives powerful computing ability to them. Storing lake data in a file system can also obtain computing power nearly as good as, even greater than, the database capability. This introduces computing capacity on the basis of part iii and makes the originally impossible triangle feasible.
Besides text files, SPL can also handle data of hierarchical format like JSON naturally. Data stored in NoSQL and RESTful can thus be used directly without transformation. It’s really convenient.
A |
||
1 |
=json(file("/data/EO.json").read()) |
|
2 |
=A1.conj(Orders) |
|
3 |
=A2.select(Amount>1000 && Amount<=3000 && like@c(Client,"*s*")) |
Conditional filtering |
4 |
=A2.groups(year(OrderDate);sum(Amount)) |
Grouping & aggregation |
5 |
=A1.new(Name,Gender,Dept,Orders.OrderID,Orders.Client,Orders.Client,Orders.SellerId,Orders.Amount,Orders.OrderDate) |
Join |
All-around computing capacity
SPL has all-around computational capability. The discrete data set model (instead of relational algebra) it is based arms it with a complete set of computing abilities as SQL has. Moreover, with agile syntax and procedural programming ability, data processing in SPL is simpler and more convenient than in SQL.
SPL boasts a wealth of class libraries for computations.
Accessing source data directly
SPL’s open computing power extends beyond data lake. Generally, if the target data isn’t synchronized from the source to the lake but is needed right now, we have no choice but to wait for the completion of synchronization. Now with SPL, we can access the data source directly to perform computations, or perform mixed computations between the data source and the existing data in the lake. Logically, the data source can be treated as part of the data lake to engage in the computation so that higher flexibility can be achieved.
High-performance computations after data transformation
SPL’s joining makes data warehouse optional. SPL has all-around, remarkable computing power and offers high-performance file storage strategies. ETLing raw data and storing it in SPL storage formats can achieve higher performance. What’s more, the file system has a series of advantages like flexible to use and easy to parallelly process.
SPL provides two high-performance storage formats – bin file and composite table. A bin file is compressed (to occupy less space and allow fast retrieval), stores data types (to enable faster retrieval without parsing), and supports the double increment segmentation technique to divide an append-able file, which facilitates parallel processing in an effort to further increase computing performance. The composite table uses column-wise storage to have great advantage in handling scenarios where only a very small number of columns (fields) is involved. A composite table is also equipped with the minmax index and supports double increment segmentation technique, letting computations both enjoy the advantages of column-wise storage and be more easily parallelly processed to have better performance.
It is easy to implement parallel processing in SPL and fully bring into play the advantage of multiple CPUs. Many SPL functions, like file retrieval, filtering and sorting, support parallel processing. It is simple and convenient for them to automatically implement the multithreaded processing only by adding the @m option. They support writing parallel program explicitly to enhance computing performance.
In addition, SPL supports a variety of high-performance algorithms SQL cannot achieve, the commonly seen TopN operation, for example. It treats calculating TopN as a kind of aggregate operation, which successfully transforms the highly complex sorting to the low-complexity aggregate operation while extending the field of application.
A |
||
1 |
=file(“data.ctx”).create().cursor() |
|
2 |
=A1.groups(;top(10,amount)) |
Get orders records where the amount rank in top 10 |
3 |
=A1.groups(area;top(10,amount)) |
Get orders records where the amount rank in top 10 in each area |
The SPL statements do not involve any sort-related keywords and will not trigger a full sorting. The statement for getting top N from a whole set and that from grouped subsets are basically the same and both have high performance. SPL boasts many more such high-performance algorithms.
Assisted by all these mechanisms, SPL can achieve performance orders of magnitude higher than that of the traditional data warehouses. The storage and computation issues after data are transformed are solved. Data warehouses won’t be a data lake necessity any longer.
Furthermore, SPL can perform mixed computations directly on/between transformed data and raw data by making good use of values of different types of data sources rather than by preparing data in advance. This creates highly agile data lakes.
SPL enables performing lake building phases side by side while, conventionally, they can only be performed one by one (loading, transformation and computation). Data preparation and computation can be carried out concurrently and any type of raw, irregular data can be computed directly. Dealing with the computation and the transformation at the same time rather than in serial order is the key to building an ideal data lake.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version