

Routable computing engine implements front-end database
Many large organizations have their own central data warehouse to provide data service to applications. As business grows, the load on data warehouse continues to increase. To be specific, the increased load comes from two aspects: one is that the data warehouse, as the data backend of front-end applications, will face increasing front end applications and concurrent queries; the other is that since it also undertakes the off-line batch job of raw data, the data volume and computing load will increase as batch job increases. As a result, the data warehouse is often overloaded, causing many problems like too long batch-job time (far exceeding the time limit that a business tolerates); too slow response to on-line query (the users have to wait for a long time, resulting in increasingly low satisfaction). Especially at the end of a month or year when computing load is at its peak, these problems will get worse.
To solve this problem, a natural idea that comes to our mind is to increase the capacity of data warehouse, that is, expand the capacity of existing data warehouse or replace it with other high-capacity data warehouse product. However, both the software cost and hardware cost incurred at capacity expansion are very high, and frequent expansion will cause an unbearable huge investment. Moreover, once it reaches the capacity limit, this method does not work.
The feasibility of replacing the existing data warehouse with another product is also not high, because it will involve multiple departments and applications, resulting in too high comprehensive cost and risk. Even if it is replaced, you cannot ensure it is an effective solution.
We find that many real-world applications exhibit a common characteristic: the frequency of accessing a small amount of (hot) data is much higher than that of accessing a large amount of (cold) data, for example, querying the data of the last few days may account for 80% to 90% of querying all data. We can take advantage of this characteristic to solve the above problem. The specific steps include, i)add a front-end database between the central database and the front-end applications to store the hot data; ii) submit all the query requests from the front-end application to the front-end database; iii)let the front-end database judge whether the query target is hot data or cold data, and determine whether to query the data locally or transfer the requests to central data warehouse; vi) merge the query results on hot and cold data and return the final result to the front end. See the figure below for the solution:
In this solution, the data flow path follows certain data routing rules: frequent queries on a small amount of hot data are handled in the front-end database, and occasional queries on a large amount of cold data are handled in the central data warehouse. In this way, the load of the central warehouse is greatly reduced and no longer becomes a bottleneck that ties down performance.
However, it is difficult for the traditional database or data warehouse software to implement this solution, owing to the fact that the computing power of the database is closed and only the data within the database can be calculated, and hence it is difficult to implement the routing rules, query transfer and result merging. Moreover, the front-end database and data warehouse are generally different types of software products, which makes it more difficult to implement such cross-database operation.
According to our envisaged scheme, only a small amount of hot data is stored in the front-end database. If the traditional database is used as front-end database, it can only calculate the hot data but cold data, not to mention the merging of calculation results on hot and cold data. Obviously, we won't store full data in the front-end database, otherwise, it will become the second central data warehouse, leading to huge cost and repeated construction.
When the calculation routing cannot be implemented on the front-end database, we can only find methods on the front-end application. One method is to have users select data source themselves on the interface. However, this method will lower the ease of use of the application and affect user satisfaction. Another method is to modify the application to implement the routing and data integration, but the application end is not good at handling such operation, resulting in a large amount of code, and high development and maintenance costs, and it is difficult to make this method be commonly used.
esProc SPL is a professional structured and semi-structured data computing engine, boasting an open computing power. If SPL is adopted, you can access the local data, or the data from different sources, and can easily implement various computing requirements of the above solution. Therefore, SPL is well suited to acting as the role of frond-end database. The architecture of the front-end database implemented in SPL is roughly as follows:
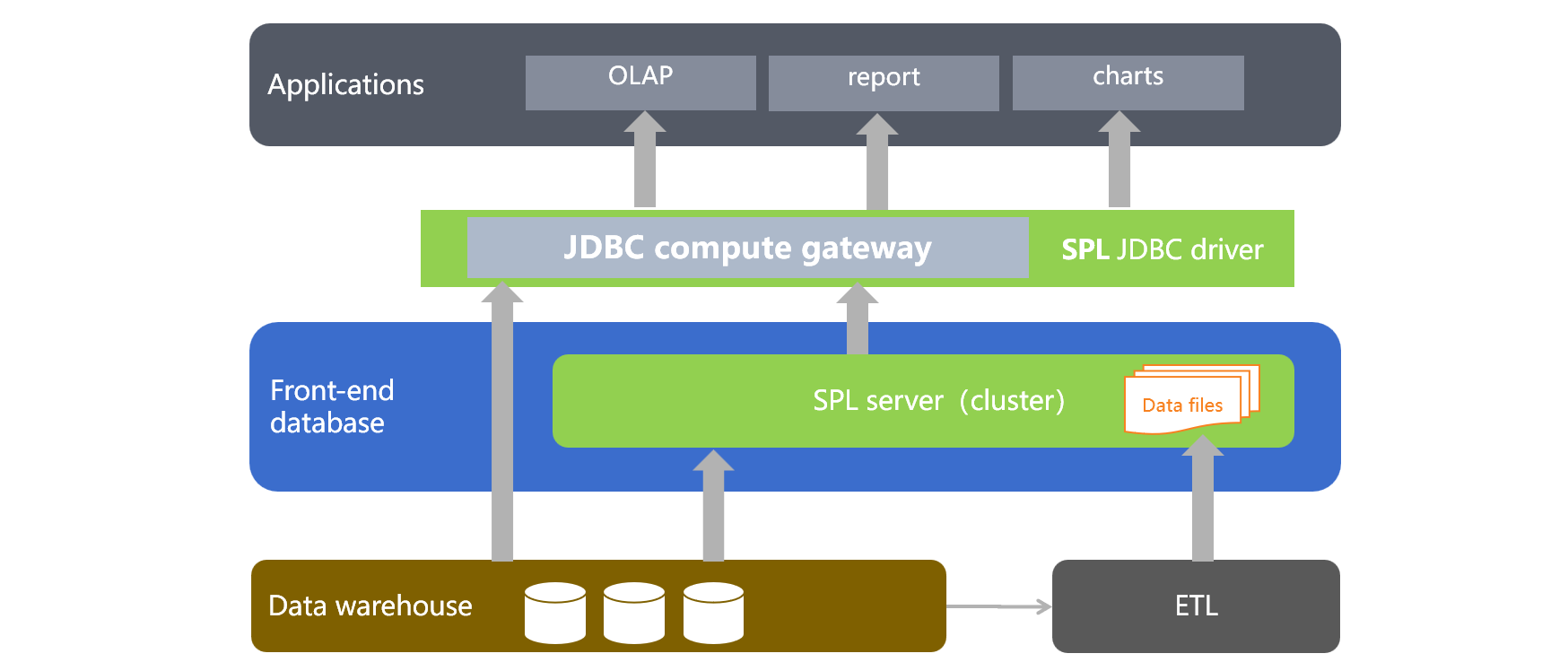
SPL is a lightweight computing engine. When the amount of hot data is not large, you only need to deploy one machine, or even you can directly embed SPL in front-end applications. Therefore, the system construction cost is much lower than that of traditional database.
SPL code for implementing data routing rules is very simple. Suppose the front-end application wants to group and aggregate by customer, and the input parameters are begin year and end year. Since more than 90% of the requests from the front-end application are to calculate the data of this year and last year, the hot data of these two years is stored in SPL’s composite table sales.ctx, and the full data is still stored in the sales table of central data warehouse. In this case, after the request of front-end application is submitted to the front-end database, SPL code to implement data routing is roughly as follows:
 |
A | B |
| 1 | =begin_year=2021 | =end_year=2022 |
| 2 | if begin_year>=year(now())-1 | =file("sales.ctx").open().cursor@m(...;year(sdate)<=end_year) |
| 3 | return B2.groups(customer;sum(…),avg(…),…) | |
| 4 | else | =connect("DW").query("select customter,sum(…),avg(…) from sales where year(sdate)>=? And year(sdate)<=? group by customer",begin_year,end_year) |
| 5 | return B4 |
A1, A2: The begin year and the end year submitted from front end should be passed in as parameter in practice, they are written directly in the code here for the ease of understanding.
A2-B3: If the begin year is greater than or equal to the last year, perform the calculation based on the local hot data file “sales.ctx”, and return the result. For the filtering and grouping calculations, SPL can implement them with just one or two functions.
A4-B5: If the begin year is smaller than the last year, connect to the central data warehouse DW to execute the request and return result. SPL can easily connect to various databases and data warehouses, and easily transfer front-end requests, and return final result to front-end application.
SPL encapsulates a large number of computing functions for structured and semi-structured data, and can implement very complex calculations in very simple code. In contrast, if a high-level language such as Java is employed in the front-end application to implement simple filtering, grouping and aggregating calculation, it needs to write a lot of code.
The front-end database implemented with routable computing engine esProc SPL caches a small amount of hot data accessed at high frequency locally, which can effectively improve system’s overall response speed, and reduce the wait time of user. Moreover, the front-end database separates the vast majority of query calculations from the central data warehouse, reducing the burden on the data warehouse.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

