

SQL is consuming the lives of data scientists
SQL is widely used, and data scientists (analysts) often need to use SQL to query and process data in their daily work. Many enterprises hold the view that as long as the IT department builds a data warehouse (data platform) and provides SQL, data scientists can freely query and analyze enterprise data.
This view is seemingly true, since SQL enables data scientists to query and calculate data. Moreover, SQL is very much like English and seems easy to get started, and some simple SQL statements can even be read as English directly.
For example, the SQL statement for filtering:
Select id,name from T where id=1
This statement is almost identical to English “Query id and name from T if id equals 1”.
Another example: the SQL statement for grouping and aggregating:
Select area,sum(amount) from T group by area
This statement is also very similar to English expression “Summarize amount by area from T”.
Looking like English (natural language) has a significant benefit, that is, simple in coding. The implementation of data query with a natural language makes it possible for even business personnel (data scientists are often those who are familiar with business but not proficient in IT technology) to master, which is exactly the original intention of designing SQL: enable ordinary business personnel to use.
Then what does it actually go?
If all the calculation tasks were simple like grouping and filtering, most business personnel could indeed master, and it is also simple to code in SQL. However, the business scenarios that data scientists face are often not that simple, for example:
Find out the top n customers whose sales account for 50% and 80% of the total sales based on the sales data, so as to carry out precision marketing;
Analyze which restaurants are most popular, which time periods are the busiest, and which dishes are the most popular based on the number of customers, consumption amount, consumption time, consumption location and other data of each chain restaurant;
Calculate each model’s sales, sales volume, average price and sales regions, etc., based on car sales data, so as to analyze which models are the hottest and which models need to adjust price and improve design;
Find out stocks that have experienced a rise by the daily limit for three consecutive trading days (rising rate >=10%) based on the stock trading data to construct an investment portfolio;
Calculate the maximum number of days that a certain stock keeps rising based on its market data to evaluate its historical performance;
Conduct a user analysis based on game login data, listing the first login records of users and the time interval from the last login, and counting users’ number of logins within three days prior to the last login;
Evaluate whether a customer will default on the loan based on some data of his/her account like balance, transaction history and credit rating, and identify which customers are most likely to default;
Determine which patients are most in need of prevention and treatment based on their medical records, diagnostic results and treatment plans;
Calculate user's monthly average call duration, data consumption amount and peak consumption time period, and identify which users are high-consumption user, based on operator’s data such as users' call records, SMS records and data consumption;
Perform a funnel analysis based on e-commerce users’ behavior data, calculating the user churn rate after each event such as page browsing, adding to cart, placing order, and paying;
Divide customers into different groups such as the group having strong purchasing power, the group preferring women's clothing, the group preferring men's clothing based on the e-commerce company's customer data such as purchase history and preferences to facilitate developing different promotional activities for different groups;
…
These examples only account for a very small part of actual calculation tasks. We can see from the examples that most of data analysis that make business sense are somewhat complex, rather than simply filtering and grouping. For such analysis, it is not easy or even impossible for us to code in SQL. Let’s attempt to code several tasks in SQL to see the difficulty to implement.
Find out the top n customers whose cumulative sales account for half of the total sales, and sort them by sales in descending order:
with A as
(select customer, amount, row_number() over(order by amount) ranking
from orders)
select customer, amount
from (select customer,
amount,
sum(amount) over(order by ranking) cumulative_amount
from A)
where cumulative_amount > (select sum(amount) / 2 from orders)
order by amount desc
Find out stocks that have experienced a rise by the daily limit for three consecutive trading days (rising rate >=10%):
with A as
(select code,
trade_date,
close_price / lag(close_price) over(partition by code order by trade_date) - 1 rising_range
from stock_price),
B as
(select code,
Case
when rising_range >= 0.1 and lag(rising_range)
over(partition by code order by trade_date) >= 0.1 and
lag(rising_range, 2)
over(partition by code order by trade_date) >= 0.1 then
1
Else
0
end rising_three_days
from A)
select distinct code from B where rising_three_days = 1
Calculate the maximum number of trading days that a certain stock keeps rising:
SELECT max(consecutive_day)
FROM (SELECT count(*) consecutive_day
FROM (SELECT sum(rise_or_fall) OVER(ORDER BY trade_date) day_no_gain
FROM (SELECT trade_date,
CASE
when close_price > lag(close_price)
OVER(ORDER BY trade_date) then
0
Else
1
end rise_or_fall
FROM stock_price))
GROUP BY day_no_gain)
e-commerce funnel analysis (this code only counts the number of users of three steps respectively: page browsing, adding to cart, and placing order):
with e1 as
(select uid, 1 as step1, min(etime) as t1
from event
where etime >= to_date('2021-01-10')
and etime < to_date('2021-01-25')
and eventtype = 'eventtype1'
and …
group by 1),
e2 as
(select uid, 1 as step2, min(e1.t1) as t1, min(e2.etime) as t2
from event as e2
inner join e1
on e2.uid = e1.uid
where e2.etime >= to_date('2021-01-10')
and e2.etime < to_date('2021-01-25')
and e2.etime > t1
and e2.etime < t1 + 7
and eventtype = 'eventtype2'
and …
group by 1),
e3 as
(select uid, 1 as step3, min(e2.t1) as t1, min(e3.etime) as t3
from event as e3
inner join e2
on e3.uid = e2.uid
where e3.etime >= to_date('2021-01-10')
and e3.etime < to_date('2021-01-25')
and e3.etime > t2
and e3.etime < t1 + 7
and eventtype = 'eventtype3'
and …
group by 1)
select sum(step1) as step1, sum(step2) as step2, sum(step3) as step3
from e1
left join e2
on e1.uid = e2.uid
left join e3
on e2.uid = e3.uid
The tasks, without exception, nest multiply-layer subqueries. Although some SQL codes are not long, it’s difficult to understand (like the example of calculating the maximum number of days that a stock keeps rising), let alone code; Some tasks are so difficult that it is almost impossible to code (like the funnel analysis).
It is indeed easy and convenient to code in SQL for simple calculations, but when the computing task becomes slightly complex, it is not easy. The actual computing tasks, however, especially those faced by data scientists, most of them are quite complex. Moreover, simple tasks do not require data scientists to code at all, because many BI tools provide the visual interface through which simple queries can be directly dragged out. Therefore, we can basically conclude that:
The SQL code that needs data scientists to write is not simple!
What consequences will this cause?
This will directly lead to a situation where the data scientist needs to consume a lot of time and energy to write complex SQL code, resulting in a low work efficiency. In short, SQL is consuming the lives of data scientists.
How SQL consumes the lives of data scientists
Difficult to code when encountering complex tasks
Just like the SQL code examples given above, although some codes are not long, it is difficult to understand and more difficult to write. One of the reasons for this phenomenon is that English-like SQL leads to the difficulty in stepwise computing.
The purpose of designing SQL as a language like English is to enable the business personnel (non-technical personnel) to use as well. As discussed earlier, this purpose can indeed be achieved for simple calculations. However, for professional analysts like data scientists, the computing scenarios they face are much more complex, this purpose will cause difficulties instead of bringing convenience once the calculation task becomes complex.
One of the advantages of natural language is that it can express in a fuzzy way, yet SQL needs to follow very strict syntax and a minor non-compliance will be rejected by interpreter. As a result, instead of benefiting from being like English, it causes serious disadvantages. Designing the syntax to be like natural language seems easy to master, but it is the opposite in fact.
In order to make the whole SQL statement conform to English habits, many unnecessary prepositions need to be added. For example, FROM, as the main operation element of a statement, is placed at the end of statement; a redundant BY is added after GROUP.
The main disadvantage of being like natural language is the procedural character. We know that stepwise computing is an effective way to deal with complex calculations, and almost all high-level languages support this feature. However, this is not the case for natural language, which needs to rely on a few pronouns to maintain the relationship between two sentences, yet a few pronouns cannot sufficiently and accurately describe the relationship, so a more common practice is to put as many things as possible into one sentence, resulting in the appearance of a large number of subordinate clauses when handling complex situation. When this practice is manifested in SQL, multiple actions such as SELECT, WHERE and GROUP need to be put into one statement. For example, although WHERE and HAVING have the same meaning, it still needs to use both of them in order to show difference, which will lead to a phenomenon where one SQL statement nests multiple-layer subqueries when the query requirements become complex, and this phenomenon will inevitably bring difficulties to coding and understanding. This is also the case in practice, where the complex SQL statements that analysts face are rarely measured in rows but often in KBs. For the same code of 100 lines, the complexities of writing it as 100 statements and one statement are completely different. It is difficult to understand such SQL statement. Even if the programmers take a great effort to work it out, they may have no idea what it means after two months.
In addition to the lack of procedural character, a more important reason for being difficult to code in SQL is its defect in theoretical basis: the relational algebra, which was born 50 years ago, lacks necessary data types and operations, making it very difficult to support modern data analysis business.
While SQL system has the concept of record data type, it has no explicit record data type. SQL will treat a single record as a temporary table with only one record, i.e., a single-member set. The characteristic of lacking discreteness will make data scientists fail to process analytical task according to natural way of thinking, resulting in serious difficulties in understanding and coding.
For example, for the funnel analysis case above, although CTE syntax makes SQL have the stepwise computing ability to a certain extent, it is still very complicated to code. Specifically, every sub-query needs to associate the original table with the result of the previous sub-query, and it is difficult to code such roundabout JOIN operation, which is beyond the ability of many data scientists. Normally, we only need to group by user, then sort the in-group data by time, and finally traverse each group of data (users) separately. The specific steps depend on actual requirements. Treating the data that meets condition or the grouped data as separate record to calculate (i.e., the discreteness) can greatly simplify the funnel analysis process. Unfortunately, SQL is unable to provide such ordered calculation due to the lack of the support for discreteness, and thus it has to associate repeatedly, resulting in difficult in coding and slow in running.
In fact, such discrete record concept is very common in high-level languages such as Java and C++, but SQL does not support this concept. Relational algebra defines rich set operations, but is poor in discreteness. As a result, it is difficult for SQL to describe complex multi-step operations (the performance is also poor). And such theoretical defect cannot be solved by engineering methods.
For more information about the defects of SQL in data types and operations, visit: Why a SQL Statement Often Consists of Hundreds of Lines, Measured by KBs?
Difficult to debug
In addition to being difficult to code, it is difficult to debug SQL code, which exacerbates the phenomenon “consuming the lives of data scientists”.
Debugging SQL code is notoriously difficult. The more complex the SQL code, the harder it is to debug, and complex SQL code is often the most in need of debugging, as correctness should always be the top priority.
When we execute a long SQL code that nests sub-queries and find the result is incorrect, how should we debug? Under normal circumstances, the only thing we can do is to split the code and execute layer by layer to ascertain the problem.
However, when the SQL statement is too complex, this debugging method may be very time-consuming and difficult, for the reason that there may exist a large number of nested subqueries and association queries in the statement, and splitting is often not easy.
Despite that fact that many SQL editors provide the interactive development interface, it does not help much for debugging complex SQL statement. In addition, difficult in debugging will affect development efficiency, resulting in a further decrease in development efficiency.
Low performance
Besides the two shortcomings mentioned above, complex SQL code often leads to low performance. Low performance means waiting, and in some big data computing scenarios, data scientists need to wait for hours or even a day, and their lives are consumed in this process. When encountering an unlucky situation where data scientists find the calculation result is incorrect after waiting for a long time, they have to repeat this process, which will lead to a multiplied time cost.
Why does complex SQL code run slowly?
The query performance of complex SQL code depends mainly on the optimization engine of database. A good database will adopt more efficient algorithms based on the calculation goal (rather than executing according to the literally expressed logic of SQL code). However, the automatic optimization mechanism often fails in the face of complex situations, and too transparent mechanism will make us difficult to manually intervene in the execution path, let alone make SQL execute the algorithms we specify.
Let's take a simple example: take the top 10 out of 100 million pieces of data, SQL code:
SELECT TOP 10 x FROM T ORDER BY x DESC
Although this code contains sorting-related words (ORDER BY), database’s optimization engine won’t do a big sorting in fact (sorting of big data is a very slow action), and will choose a more efficient algorithm instead.
If we make slight changes to the task above: calculate the top 10 in each group, then SQL code:
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY Area ORDER BY Amount
DESC) rn
FROM Orders )
WHERE rn<=10
While the complexity of this code does not increase much, the optimization engines of most databases will get confused, and cannot identify its real intention, and instead they have to carry out a sorting according to the literally expressed logic (there is still the words ORDER BY in the statement). As a result, the performance decreases sharply.
The SQL codes in real-world business are much more complex than this code, and failure to identify the real intention of code is quite common for database’s optimization engine. For example, the SQL statement for funnel analysis mentioned earlier needs to associate repeatedly, resulting in the difficulty to code, and the extreme low performance to execute.
Of course, using the user-defined function (UDF) can enhance SQL’s ability, allowing us to implement the desired algorithms. However, this method is often unrealistic. Not to mention that the storage of databases cannot ensure performance when algorithm changes, the difficulty of implementing UDF itself is beyond the technical ability of the vast majority of data scientists. Even if UDF is implemented with great effort, it would face the complexity problem mentioned earlier, and performance is often not guaranteed.
Closedness
The shortcomings of SQL don't stop there.
SQL is the formal language of database, yet the database has closedness, which will lead to the difficulty in data processing. The so-called closedness means that the data to be computed and processed by database must be loaded into database in advance, and there is clear definition about whether data is inside or outside the database.
In practice, however, data analysts often need to process data from other sources including text, Excel, program interfaces and web crawlers and so on. Some of these data are only used temporarily, and if they can be used only after loading into database each time, not only will it occupy the space of database, but the ETL process will consume a lot of time. In addition, loading data into database is usually constrained. Some non-compliant data cannot be written to database. In this case, it needs to take time and effort to organize the data first, and then write the organized data to database (writing data to database is time-consuming). Once time is wasted, life is wasted.
Of course, besides SQL, data scientists have other tools like Java and Python. Then, do these tools work?
Java supports procedural calculation and has good discreteness, but its support for set operation is poor. Java lacks basic data types and computing libraries, which makes data processing extremely cumbersome. For example, the grouping and aggregating operation, which is easy to implement in SQL, is not easy for Java, and it is more difficult for Java to implement other operations such as filtering, join and multiple mixed operations. Moreover, Java is too heavy for data analysts, and is very poor in interactivity, and thus it is not usable in practice even if any calculation can be implemented in Java in theory.
Compared with Java, Python is a little bit better. Python has richer computing libraries and is simpler in implementing the same calculation (its computing ability is often comparable to SQL). However, for complex calculations, it is also cumbersome, and Python does not have much advantage over SQL. Moreover, Python’s interactivity is not good, either (it still needs to print and output the intermediate results manually). And, due to the lack of true parallel computing mechanism and storage guarantee, Python also faces performance issue in big data computing.
It there any other choice?
esProc SPL, a tool rescuing data scientist
For data scientists who often process structured data, esProc SPL is a tool that is well worth adding to their data analysis “arsenal”.
esProc is a tool specifically designed for processing structured data, and its formal language, SPL (Structured Process Language), boasts completely different data processing ability from SQL and JAVA.
Simpler in coding
Firstly, let's take a look at how SPL differs from SQL in accomplishing the tasks mentioned above:
Find out the top n customers whose cumulative sales account for half of the total sales, and sort them by sales in descending order:
A |
||
1 |
=db.query(“select * from orders”).sort(amount:-1) |
|
2 |
=A1.cumulate(amount) |
Get a sequence of cumulative amounts |
3 |
=A2.m(-1)/2 |
Calculate the final cumulative amount, i.e., the total |
4 |
=A2.pselect(~>=A3) |
Find the position where the amount exceeds half of the total |
5 |
=A1(to(A4)) |
Calculate the maximum number of days that a stock keeps rising:
A |
|
1 |
=stock.sort(tradeDate) |
2 |
=0 |
3 |
=A1.max(A2=if(closePrice>closePrice[-1],A2+1,0)) |
Find out stocks that have experienced a rise by the daily limit for three consecutive trading days (rising rate >=10%):
A |
B |
C |
D |
|
1 |
=db.query(“select * from stock_price”).group(code).(~.sort(trade_date)) |
=[] |
Result set is in C1 |
|
2 |
for A1 |
=0 |
||
3 |
if A2.pselect(B2=if(close_price/close_price[-1]>=1.1,B2+1,0):3)>0 |
Get stocks that end limit-up in three consecutive trading days |
||
4 |
>C1=C1|A2.code |
Funnel analysis of an e-commerce business:
A |
|
1 |
=["etype1","etype2","etype3"] |
2 |
=file("event.ctx").open() |
3 |
=A2.cursor(id,etime,etype;etime>=date("2021-01-10") && etime<date("2021-01-25") && A1.contain(etype) && …) |
4 |
=A3.group(uid).(~.sort(etime)) |
5 |
=A4.new(~.select@1(etype==A1(1)):first,~:all).select(first) |
6 |
=A5.(A1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==A1.~ && etime>t && etime<t1+7).etime, null)))) |
7 |
=A6.groups(;count(~(1)):STEP1,count(~(2)):STEP2,count(~(3)):STEP3) |
From the SPL codes above, we can see that SPL is simpler than SQL. Even those who don’t know SPL syntax can basically understand these SPL codes. If they familiarize themselves with SPL syntax, implementing these calculations is not difficult.
The reason why SPL is simpler is that it naturally supports procedural calculation.
As mentioned earlier, procedural calculation can effectively reduce the implementation difficulty of complex business, and the improvement of development efficiency can help data scientists create more value. Although CTE syntax and stored procedure make SQL have the procedural computing ability to a certain extent, it is far from enough. In contrast, SPL naturally supports procedural calculation, and can divide complex calculation into multiple steps, thereby reducing implementation difficulty.
For example, for the calculation of number of days that a stock keeps rising, SPL allows us to calculate according to natural train of thought: sort by trading days first, and then compare the closing price of the day with that of the previous day (if the comparison result is greater than 1, cumulate with the help of intermediate variable, otherwise reset to zero), and finally find the maximum value in the sequence, which is the value we want. The entire calculation process does not require nesting, and can be easily implemented step by step according to natural thinking, which are the benefits that procedural calculation brings. Also, for the funnel analysis, the implementation difficulty is reduced through stepwise computing, and the code is more universal, and can handle the funnel calculation with any number of steps (the only thing that needs to do is to modify the parameter).
Another reason why SPL is simpler is that it provides richer data types and computing libraries, which can further simplify calculation.
SPL provides a professional structured data object: table sequence, and offers rich computing library based on the table sequence, thereby making SPL have complete and simple structured data process ability.
Here below are part of conventional calculations in SPL:
Orders.sort(Amount) // sort
Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // filter
Orders.groups(Client; sum(Amount)) // group
Orders.id(Client) // distinct
join(Orders:o,SellerId ; Employees:e,EId) // join
By means of the procedural calculation and the table sequence, SPL can implement more calculations. For example, SPL supports ordered operation more directly and thoroughly. In the above SPL code for calculating the number of days that a stock rises, it uses [-1] to reference the previous record to compare the stock prices. If we want to calculate the moving average, we can write avg(price[-1:1]). Through ordered operation, the calculation of the maximum number of days that a stock keeps rising can be coded this way:
stock.sort(trade_date).group@i(close_price<close_price[-1]).max(~.len())
For the grouping operation, SPL can retain the grouped subset, i.e., the set of sets, which makes it convenient to perform further operations on the grouped result. In contrast, SQL does not have explicit set data type, and cannot return the data types such as set of sets. Since SQL cannot implement independent grouping, grouping and aggregating have to be bound as a whole.
In addition, SPL has a new understanding on aggregation operation. In addition to common single value like SUM, COUNT, MAX and MIN, the aggregation result can be a set. For example, SPL regards the common TOPN as an aggregation calculation like SUM and COUNT, which can be performed either on a whole set or grouped subsets.
In fact, SPL has many other features, making it more complete than SQL and richer than Java/Python. For example, the discreteness allows the records that make up a data table to exist dissociatively and be computed repeatedly; the universal set supports the set composed of any data, and allows such set to participate in computation; the join operation distinguishes three different types of joins, allowing us to choose an appropriate one according to actual situation...
These features enable data scientists to process data more simply and efficiently, putting an end to the waste of lives.
Easy to edit and debug
Another factor affecting development efficiency is the debugging environment. How to debug code and interact with data scientists more conveniently is also a key consideration for SPL. For this purpose, SPL provides an independent IDE:
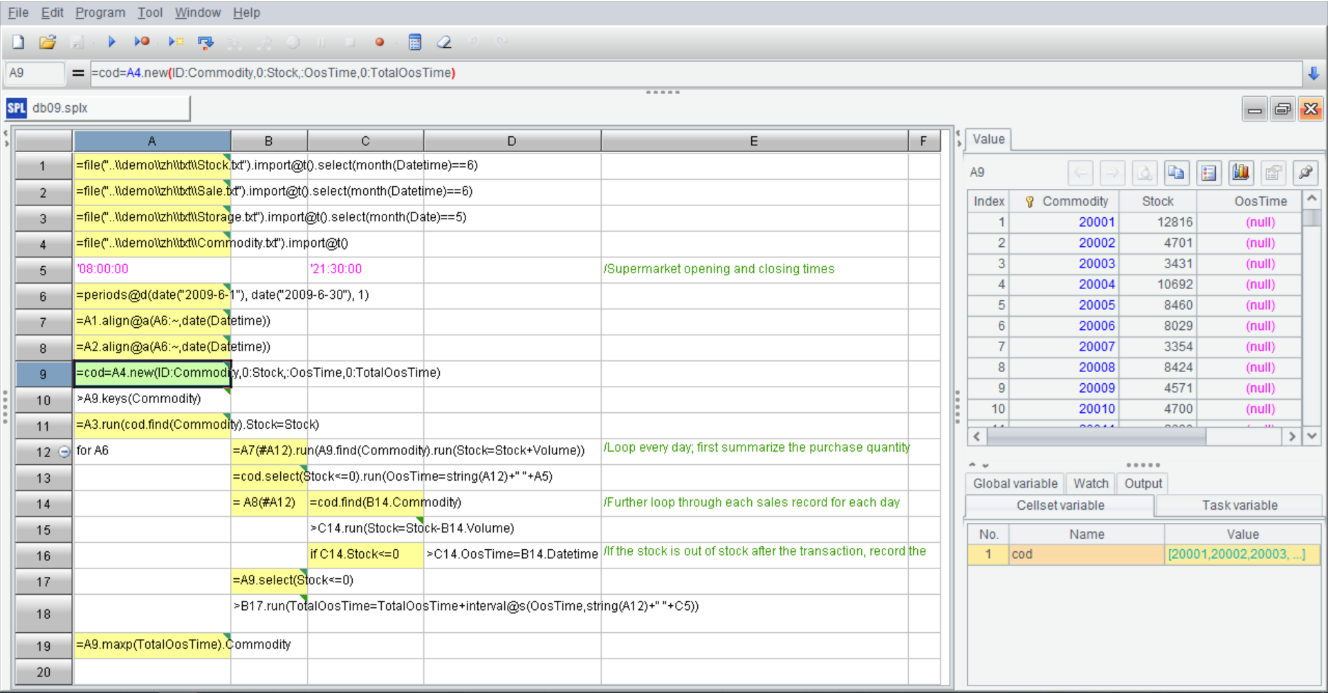
Unlike other programming languages that use text to program, SPL adopts grid-style code to program. The grid-style code has some natural advantages, which are mainly reflected in three aspects. First, there is no need to define variables when coding. By referencing the name of previous cells (such as A1) directly in subsequent steps, we can utilize the calculation result of the cells. In this way, racking our brains to name variables is avoided. Of course, SPL also supports defining variables; Second, the grid-style code looks very neat. Even if the code in a cell is very long, it will occupy one cell only and will not affect the structure of whole code, thus making code reading more conveniently; Third, the IDE of SPL provides multiple debugging ways, such as run, debug, run to cursor. In short, easy-to-use editing and debugging functionalities improves coding efficiency.
Moreover, on the right side of the IDE, there is a result panel, which can display the calculation result of each cell in real time. Viewing the result of each step in real time further improves the convenience of debugging. With this feature, not only can data scientists easily implement routine data analysis, but they can also conduct interactive analysis, and make decision on what to do next instantly based on the result of the previous step. In addition, this feature enables data scientist to review the result of a certain intermediate step conveniently.
High performance
Supporting procedural calculation and providing rich computing libraries allow SPL to quickly accomplish data analysis tasks, and its easy-to-use IDE further improves development efficiency. Besides, what about the performance of SPL? After all, the computing performance is also crucial for data scientists.
In order to cope with the big data computing scenario where the amount of data exceeds memory capacity, SPL offers cursor computing method.
=file("orders.txt").cursor@t(area,amount).groups(area;sum(amount):amount)
Moreover, SPL provides parallel computing support for both in-memory and external storage calculations. By adding just one @m option, parallel computing can be implemented and the advantages of multi-core CPU can be fully utilized, which is very convenient.
=file("orders.txt").cursor@tm(area,amount;4).groups(area;sum(amount):amount)
In addition to cursor and parallel computing, SPL offers many built-in high-performance algorithms. For example, after SPL treats the previously mentioned TOPN as an ordinary aggregation operation, sorting action is avoided in the corresponding statement, so the execution is more efficient.
Similarly, SPL provides many such high-performance algorithms, including:
In-memory computing: binary search, sequence number positioning, position index, hash index, multi-layer sequence number positioning...
External storage search: binary search, hash index, sorting index, index-with-values, full-text retrieval...
Traversal computing: delayed cursor, multipurpose traversal, parallel multi-cursor, ordered grouping and aggregating, sequence number grouping...
Foreign key association: foreign key addressization, foreign key sequence-numberization, index reuse, aligned sequence, one-side partitioning...
Merge and join: ordered merging, merge by segment, association positioning, attached table...
Multidimensional analysis: partial pre-aggregation, time period pre-aggregation, redundant sorting, boolean dimension sequence, tag bit dimension...
Cluster computing: cluster multi-zone composite table, duplicate dimension table, segmented dimension table, redundancy-pattern fault tolerance and spare-wheel-pattern fault tolerance, load balancing...
In order to give full play to the effectiveness of high-performance algorithms, SPL also designs high-performance file storage, and adopts multiple performance assurance mechanisms such as code compression, columnar storage, index and segmentation. Once flexible and efficient storage is available, data scientists can design data storage forms (such as sorting, index and attached table) based on the calculation to be conducted and the characteristic of data to be processed, and adopt more efficient algorithms based on the storage form so as to obtain an extreme performance experience. Saving time is to save lives.
Openness
Unlike the database that requires loading data into database before calculation (closedness), SPL can directly calculate when facing diverse data sources, and hence it has good openness.
SPL does not have the concept of “base” of traditional data warehouses, nor does it have the concept of metadata, let alone constraints. Any accessible data source can be regarded as the data of SPL and can be calculated directly. Importing data into database is not required before calculation, and exporting data out of database is also not required deliberately after calculation, the calculation result can be written to the target data source through an interface.
SPL encapsulates access interfaces for common data sources such as various relational databases (JDBC data source), MongoDB, HBase, HDFS, HTTP/Restful, SalesForces and SAP BW. Logically, these data sources have basically the same status, and can be calculated separately or in a mixed way after being accessed, and the only difference is that different data sources have different access interfaces, and different interfaces have different performance.
Under the support of openness, data scientists can directly and quickly process data of diverse sources, saving the time spent on data organization, importing into and exporting from the database, and improving data processing efficiency.
Overall, SPL provides data scientists with comprehensive structured data processing ability, and structured data is currently the top priority of data analysis. With SPL, not only can faster analysis efficiency be achieved, but it can also sufficiently guarantee the performance. Only with a tool that is simple in coding, fast in running, good in openness and interactivity, will the lives of data scientists not be wasted.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

