

Variable preliminary filtering
There are often some variables in the data that are of poor quality or are not meaningful to the model. You can define some rules and delete them directly to reduce the amount of computation. Such as:
(1)Variables with high missing rate
(2)Unary variable
(3)Variable with too many categories
A |
|
1 |
=file("D://house_prices_train.csv").import@qtc() |
2 |
=A1.fname() |
3 |
=A2.((y=~,A1.align@a([true,false],!eval(y)))) |
4 |
=A2.new(~:col,A3(#)(1).len():null_no,round(null_no/A1.len(),3):null_rate,A1.field(#).icount():icount,if(!sum(A1.field(#)),"string","num"):type) |
5 |
=A4.select(null_rate<0.9 && icount>1 && !(type=="string" && icount>100)).(col).concat(",") |
6 |
=A1.new(${A5}) |
A2 Get field names
A3 Divide each field into two groups according to whether is missing
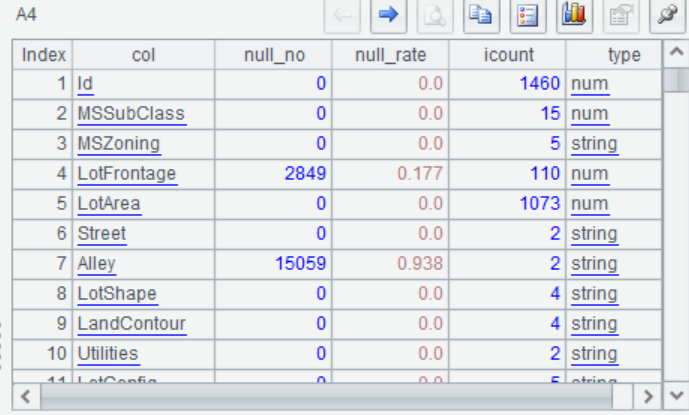
A4 Count the missing number , missing rate, number of distinct values, and data type of each field.
A5 Delete variables with a miss rate greater than 0.9, unary variables, and variables with a class number greater than 100

A6 Table after variable filtering
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_SPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL

