

Numerical the categorical variables
Categorical variables are usually in the form of characters, which can not be directly recognized and calculated by the algorithm, and must be converted into numerical data. In SPL, functions provided which can automatically handle categorical variables.
For categorical variables with no more than 6 categories, the A.bi()or P.bi(cn) functions can be used to split the categorical variable into multiple binary variables with values of 0,1.
For categorical variables with a large number of categories, the variables can be mapped to integers using A.setenum()or P.setenum(cn)
For example, in the Titanic data, the variable "Pclass" has a class number of 3 and the variable "Cabin" has a class number of 148, which are numeralized as follows:
A |
|
1 |
=file("D://titanic.csv").import@qtc() |
2 |
=file("D://titanic_t.csv").import@qtc() |
3 |
=A1.bi("Pclass") |
4 |
=A2.bi@r("Pclass",A3(2)) |
5 |
=A1.setenum@c("Ticket") |
6 |
=A2.setenum@rc("Ticket",A5(2)) |
A1 Import the modeling data
A2 Import the prediction data
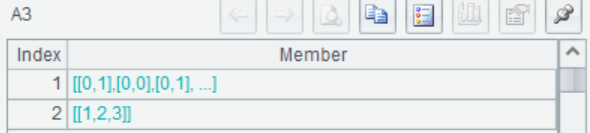
A3 In the modeling data, multiple binary variables are derived from "Pclass", A3(1) returns the processing result, and A3(2) returns the processing record Rec
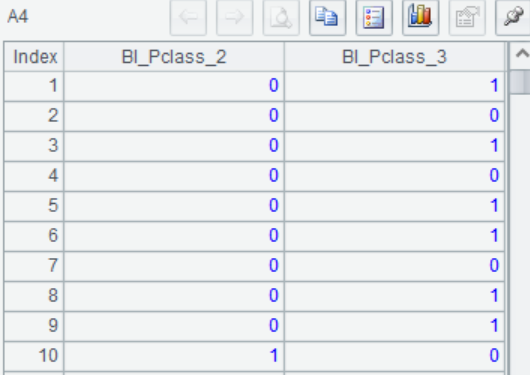
A4 The same variables are derived on the prediction data according to A3's processing record Rec
A5 The classification variable "Ticket" is mapped to integers, and the mapping result and mapping record Rec are returned. @c indicates that the original data is changed to the mapping data.
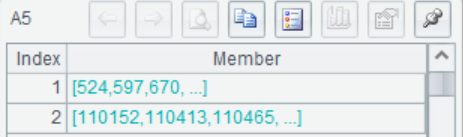
A6 According to the mapping record of A5, the same variable is mapped on the prediction data and the mapping result is returned.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

