

How can the microservices really be "micro"
Microservices have been quite trendy in recent years, and using Java to replace SQL and stored procedures to develop business logic can indeed gain framework advantages. We will not delve into the details here. Of course, there is a reason why microservices can become popular.
But are microservices really “micro”?
We know that when faced with the same business logic, the code written in Java is much longer than SQL, about 10-20 times longer. Even with the assistance of new libraries and languages such as Stream, Kotlin, and Scala, when faced with slightly more complex computational requirements, the code length still far exceeds that of SQL and stored procedures. From this perspective, microservices are not “micro” at all.
The server side is like this, and the application side is even more so. What could have been done by directly connecting to a database and writing simple SQL statements, now that we have switched to obtaining data from microservices, it is extremely troublesome to make a grouping or join, often a few hundred lines. So making reports based on microservices has always been a challenge.
Even in terms of frameworks emphasized by microservices, microservices are not “micro” enough. Microservices are designed to decouple businesses, enabling them to more confidently respond to frequent changes. But Java is a compiled language, and when code changes, it needs to be recompiled and deployed, which is not only cumbersome but also may force unrelated parts of the entire application to be compiled and deployed together. To make each service independent, it is necessary to use heavy mechanisms such as Docker and even virtual machines, which cannot achieve lightweight hot swap. This is very unfriendly for microservices that originally wanted to adapt to frequent business changes.
With the help of esProc SPL, microservices can truly become “micro”.
esProc SPL is an open-source software written in Java, and it can be found here https://github.com/SPLWare/esProc.
Let’s take a look at how esProc SPL can solve the problem that microservices are not micro enough.
The reason why Java development is more cumbersome than SQL is a long story to tell, and we will discuss it as a separate topic in the future.
SPL overcomes the problems of Java and provides more structured data objects and richer calculation functions than SQL. Based on these, SPL code is usually simpler and easier to maintain than SQL, and of course, much simpler than Java.
The usual set operations such as grouping and join can be well supported, and it is completely done by itself and will not be translated into SQL.
Orders.sort( -Client, Amount)
Orders.groups( year(OrderDate), sellerid; sum(Amount), count(1) )
For more complex tasks, such as calculating which stocks have risen continuously for more than 3 days, the SQL code is lengthy and difficult to understand:
WITH A AS
(SELECT code,date, price-LAG(price) OVER (PARITITION BY code ORDER BY date) RisingPrice FROM stock)
B AS
(SELECT code,
CASE WHEN RisingPrice>0 AND
LAG(RisingPrice) OVER (PARTITION BY code ORDER BY date) >0 AND
LAG(RisingPrice,2) OVER PARTITION BY code ORDER BY date) >0
THEN 1 ELSE 0 END Rising3DaysTag FROM A)
SELECT DISTINCT code FROM B WHERE Rising3DaysTag =1
For the same calculation logic, using Java would be more cumbersome, but using SPL is very simple:
| A | |
|---|---|
| 1 | =stock.sort(date).group(code) |
| 2 | =A1.select((a=0,~.pselect(a=if(price>price[-1],a+1,0):3))>0).(code) |
SPL also has comprehensive process control statements, such as for loops, if branches, and subroutine calls. This is equivalent to combining Java’s procedural processing power with SQL’s data processing power, so the code will be more concise than both.
The SPL code is written in a grid, which is very different from the code usually written as text. This can make it more convenient to write debugging code. SPL also provides comprehensive debugging functions, such as single step execution, setting breakpoints, previewing WYSIWYG results, making debugging and development more convenient.
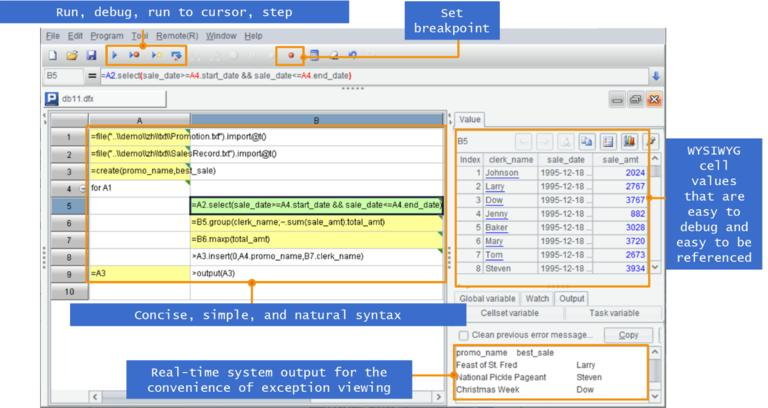
SPL also supports rich data sources, and it can be connected to and read from relational databases, NoSQL, or Hadoop/Kafka. Especially the Restful interface commonly used in microservices and multi-layer JSON format data can be well supported, making it easy to access, parse, and generate. It improves the development efficiency of microservices, so that microservices can be “micro” in both development and code.

Let’s take another look at the framework aspect. esProc SPL is pure Java software that can be seamlessly embedded into any Java application in the form of jar packages, just like the code written by programmers themselves, enjoying the advantages of mature Java frameworks together. esProc SPL provides a standard JDBC driver, allowing Java programs to call SPL code like executing database SQL or stored procedures. This is equivalent to embedding a lightweight and powerful database engine into Java.
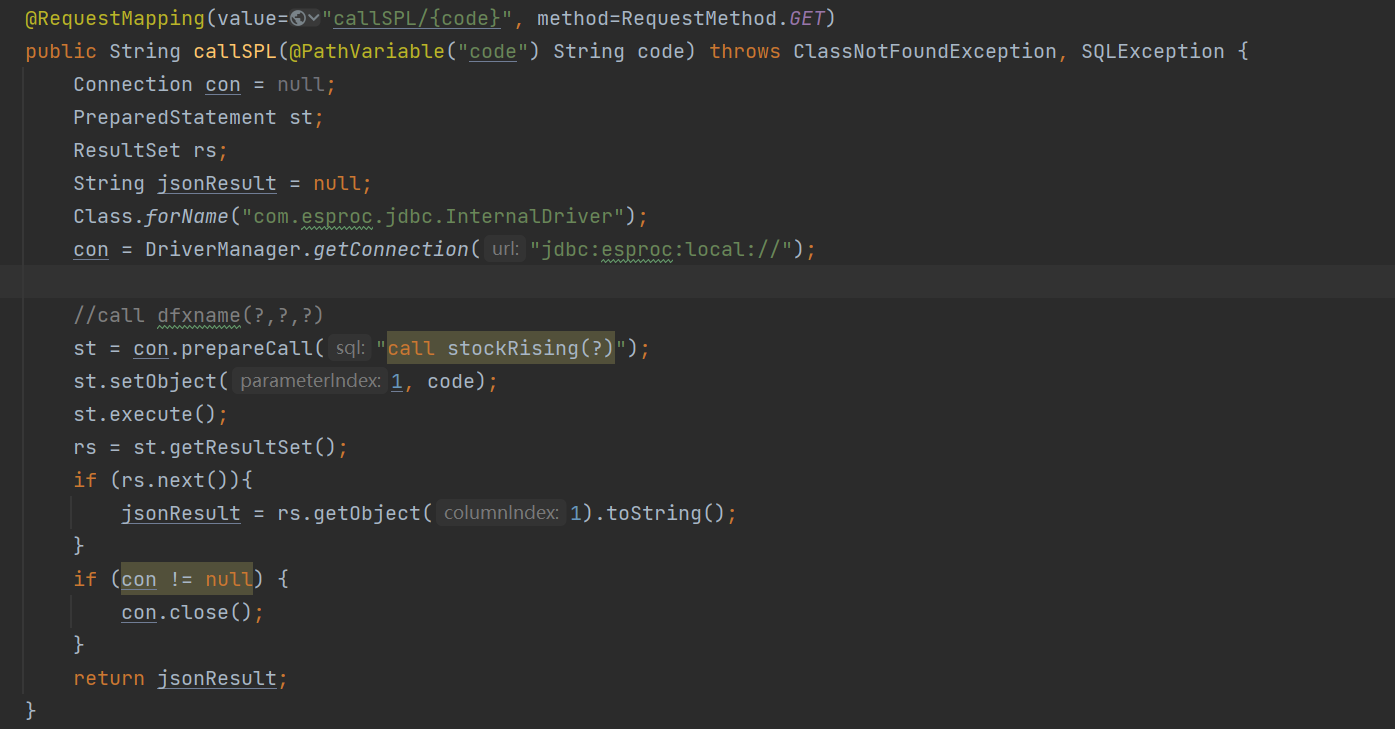
SPL is interpreted and executed, and code modifications can be generated immediately without the need for compilation and deployment, which naturally achieves hot swap of business logic, especially suitable for the diverse target scenarios of microservices.
SPL scripts can be stored as files and placed outside the main application, with each service corresponding to an SPL script, which naturally has independence. No longer requires the use of additional mechanisms such as Dockers or virtual machines, consumes minimal resources, and the framework becomes more “micro”.
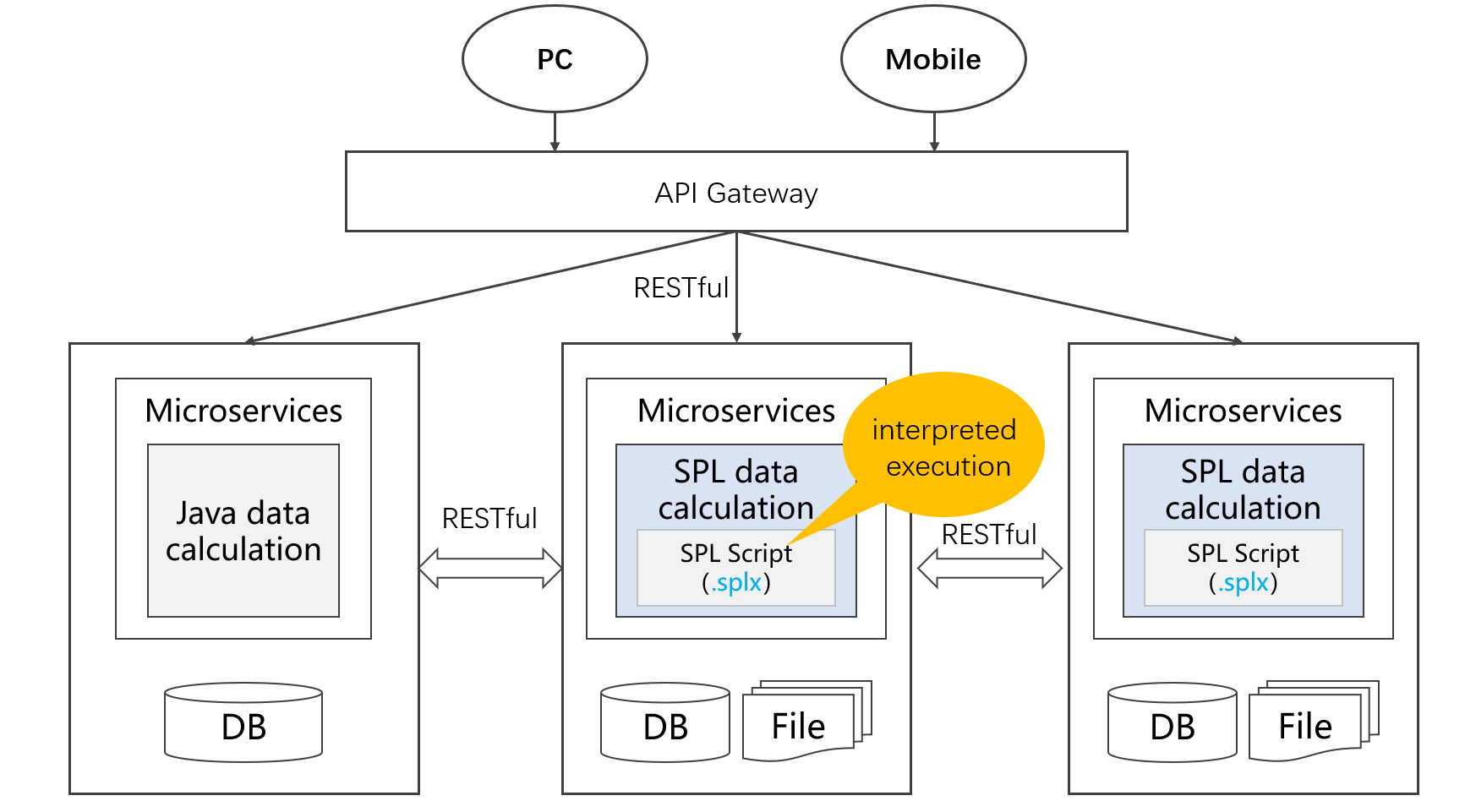
With the support of esProc SPL, microservices can truly become “micro” services and are more suitable for “hot” applications.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version