

It's not surprising that it's N times faster than ORACLE, such lightweight is the king
Oracle is a widely used database, and it is not a professional analytical database. When the data volume is large, it often results in poor computational performance, which affects the user experience. Nowadays, there are many new analytical databases that are faster or even far superior in performance than Oracle. So when Oracle performance is insufficient, replacing to these databases seems to solve the problem.
The matter is not so simple.
Firstly, these new databases generally cannot completely replace Oracle. Oracle is not only used for OLAP, but also for OLTP, and these faster analysis databases do not have the ability of OLTP (new databases that support OLTP, including HTAP advocates, may not run faster than Oracle without the help of larger clusters). Therefore, the new database has to coexist with Oracle, and there are two databases as a result.
To say the least, even if the current Oracle is only used for OLAP, it may not be completely replaced. Oracle’s support for complex SQL is quite good, and optimization is also done well. The main reason for its slow performance is that it also needs to support OLTP and cannot use columnar storage. If these new databases cannot take advantage of columnar storage (most of the columns in the entire table need to be referenced), and face many complex SQL statements, due to insufficient optimization experience, they may not be able to run as well as Oracle under the same hardware resources, and often need to rely on clusters. In addition, Oracle also has strong stored procedure functionality, which is also a capability that many new databases lack. If there are such operations in applications, Oracle still needs to be used.
Not being able to completely replace Oracle means that there need to be two sets of databases, each doing their own specialized calculations, and overall, the user experience can become better.
Going further, even if the new database can completely replace Oracle in terms of functionality and performance, there is still a migration risk issue. For businesses that are actually functioning, it is not advisable to hastily migrate them all to a new database. Generally, a gradual migration plan with two databases coexisting should also be adopted.
So, adopting a new database with better performance will almost certainly result in the phenomenon of two databases.
However, the co-existing of two databases is a very heavy thing, as the architecture becomes complex and deployment and operation are also much more troublesome, which means a sharp increase in costs. If the new database used still requires distributed deployment, it will be even heavier, even heavier than the original Oracle (most Oracle runs on a standalone machine).
There are also business issues. Oracle is typically used by high-end commercial users who will also purchase a commercial database, which is a significant cost. This type of user is also very cautious about introducing a new database and other architectural adjustments, making it difficult to scale out at any time. They often buy enough capacity for several years at a time, which causes waste in the early stage.
In short, it’s very expensive!
Is there another option?
Use lightweight esProc SPL!
esProc SPL can also easily run N times the computational performance of Oracle. The following is a test result of TPCH 100G (in seconds):
| esProc SPL | StarRocks | ClickHouse | Oracle | |
|---|---|---|---|---|
| q1 | 9.7 | 14.0 | 15.4 | 114.3 |
| q2 | 1.3 | 0.6 | 17.3 | 1.9 |
| q3 | 8.8 | 9.8 | memory overflow | 165.8 |
| q4 | 4.9 | 5.7 | memory overflow | 158.4 |
| q5 | 8.9 | 13.1 | memory overflow | 174.5 |
| q6 | 4.5 | 3.9 | 4.8 | 126.7 |
| q7 | 10.5 | 12.4 | memory overflow | 181.5 |
| q8 | 6.9 | 8.3 | memory overflow | 209.7 |
| q9 | 16.8 | 21.3 | memory overflow | 256.0 |
| q10 | 8.3 | 11.1 | 58.3 | 195.6 |
| q11 | 0.9 | 1.3 | 6.7 | 8.7 |
| q12 | 4.9 | 4.8 | 10.7 | 186.0 |
| q13 | 12.1 | 21.3 | 134.1 | 33.3 |
| q14 | 3.3 | 4.6 | 10.2 | 170.0 |
| q15 | 4.7 | 7.1 | 11.2 | 161.8 |
| q16 | 2.7 | 2.9 | 4.0 | 10.8 |
| q17 | 5.3 | 4.2 | 44.6 | 156.5 |
| q18 | 6.4 | 20.8 | memory overflow | 416.8 |
| q19 | 5.8 | 6.0 | >600 | 144.1 |
| q20 | 5.2 | 5.2 | 31.2 | 171.0 |
| q21 | 11.9 | 14.5 | syntax error | 360.7 |
| q22 | 2.5 | 1.9 | 8.4 | 37.7 |
| Total | 146.3 | 194.8 | - | 3441.8 |
It can be seen that because it is not a professional analytical database, Oracle’s computing performance is indeed not superior, but it has comprehensive functions and can implement all the cases. For detailed test reports, please refer to: SPL computing performance test series: TPCH .
Strictly speaking, esProc SPL is not a database, but a professional computing engine. It directly uses files to store data, supports its own columnar storage format files, and provides high-performance algorithms commonly used in modern data warehouses. This way, as long as the data is converted into files of these formats, high-performance calculations can be implemented. esProc does not have the concept of “(data)base”, which means there is no concept of loading into database and exporting out of database, as well as inside or outside a database. Data files can be stored in directories, moved freely, redundant, and even placed on the cloud, making management very free and convenient. The complexity of operation and maintenance is much lower than that of databases.
This is lightweight storage.
esProc provides a JDBC driver similar to a database for upper-level applications to call:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = conn.createStatement();
ResultSet result = statement.executeQuery("=T(\"Orders.btx\").select(Amount>1000 && like(Client,\"*s*\")
Unlike regular databases, esProc, as a pure Java program, can be seamlessly embedded into Java applications for execution. The entire computing engine is built into the JDBC driver package, unlike databases that require an independent server process. The esProc core package is less than 15MB, and with various third-party data source drivers, it is only hundreds of MBs and can even run smoothly on Android. esProc is like the code written by programmers themselves, packed into a large package, running within the same process, and enjoying the framework advantages brought by mature Java frameworks together. This is equivalent to esProc moving the computing power that was originally only available in data warehouses into the application.
This is lightweight deployment.
esProc no longer uses SQL, but has its own programming language SPL. SPL has all the computing power of SQL:
Orders.sort(Amount) // sorting
Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // filtering
Orders.groups(Client; sum(Amount)) // grouping
Orders.id(Client) // distict
join(Orders:o,SellerId ; Employees:e,EId) // join
...
For complex operations, SPL is much more convenient than SQL. For example, in this task, to calculate the longest consecutive days for a stock to rise, SQL needs to be written in multiple nested, lengthy, and difficult to understand:
select max(ContinuousDays) from (
select count(*) ContinuousDays from (
select sum(UpDownTag) over (order by TradeDate) NoRisingDays from (
select TradeDate,case when Price>lag(price) over ( order by TradeDate) then 0 else 1 end UpDownTag from Stock ))
group by NoRisingDays )
The same calculation logic is much simpler to write in SPL:
Stock.sort(TradeDate).group@i(Price<Price[-1]).max(~.len())
This is lightweight code.
Lightweight does not necessarily mean weak functionality, on the contrary, the functionality of esProc SPL is more powerful than many new databases:
SPL has comprehensive process control statements, such as for loops and if branches, and also supports subroutine calls, which implements the ability of store procedures; And many new databases have weak or even no stored procedure capabilities.
SPL supports a variety of external data sources, making it easy to perform multiple data source calculations, such as Oracle and Restful mixed calculations. Specifically, based on the cold data in files and the hot data in Oracle mixed calculations, real-time calculation and statistics can be easily achieved; Due to the closed nature of databases, mixed computing has always been a challenging problem.
SPL has richer high-performance algorithms than SQL, which can more fully utilize hardware resources. It is often possible to use a single machine to achieve the effect of a distributed data warehouse cluster, as shown in Here comes big data technology that rivals clusters on a single machine
esProc SPL also has a simple and easy-to-use development environment that provides single step execution, breakpoint setting, and WYSIWYG result preview. The development efficiency is much higher than SQL and stored procedures:
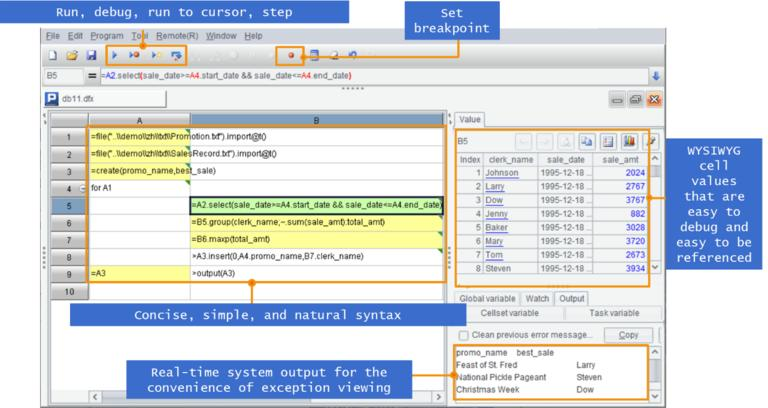
(Here A programming language coding in a grid is a more detailed introduction to SPL.)
Finally, esProc SPL is open source and free. It is here https://github.com/SPLWare/esProc .
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version