

kmeans
Using kmeans(), you can cluster samples according to the specified cluster number.
Currently, the cluster number in SPL only supports 2.
For example, there is a set of samples [[1,2,3,4],[2,3,1,2],[1,1,1,-1],[1,0,-2,-6]], cluster the samples with the cluster number of 2. And use the clustering model to predicting on samples [[6,2,3,5],[0,3,1,5],[1,2,1,-1],[1,5,2,-6]]
A |
|
1 |
[[1,2,3,4],[2,3,1,2],[1,1,1,-1],[1,0,-2,-6]] |
2 |
[[6,2,3,5],[0,3,1,5],[1,2,1,-1],[1,5,2,-6]] |
3 |
=kmeans(A1,2) |
4 |
=kmeans(A3,A2) |
5 |
=kmeans(A1,2,A2) |
A1 Input the training samples
A2 Input the prediction samples
A3 With k=2 as the parameter, a clustering model is established on the sample A1, and return the model information R
A4 Model R in A3 is used to predict on A2 samples and return the prediction result. Samples 1, 2 and 3 are of the same class, and sample 4 is the other class
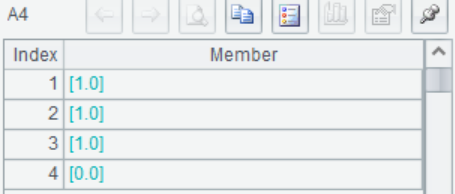
A5 Continuous modeling and prediction, directly return the prediction results, the effect is equivalent to A3+A4
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

