

How come there are tens of thousands of tables in a database
Many large databases accumulate a large number of data tables after running for many years, with severe cases reaching tens of thousands, making the database very bloated. These data tables are often many years old, for some of which the construction reasons may have been forgotten or they may no longer be useful, but they are difficult to confirm and you dare not delete them. This brings a huge burden to the operation and maintenance work. Along with these tables, there are still a large number of stored procedures constantly updating data to these tables, occupying computing resources and often forcing the database to scale up.
Are these tables truly necessary for the business? Is the business so complex that it requires thousands of tables to describe?
People with development experience know that this is unlikely, as a few hundred tables can describe a fairly complex business. Most of these tables are so-called intermediate tables and are not used to store basic data.
Then, why will there be intermediate tables?
Intermediate tables are mostly used to serve the data presentation (reporting or querying). When the raw data volume is large or the calculation process is complex, direct calculation is troublesome and the performance is poor. We will first calculate some intermediate results and store them. When presenting them, we will then perform some simple filtering and aggregations based on parameters, and the user experience will be much better. These intermediate data will exist in the form of data tables, and will also be updated regularly along with the stored procedures. Front end reports are unstable businesses that require frequent modifications and additions, resulting in an increasing number of intermediate tables.
Some intermediate tables are caused by external data sources, and sometimes applications need to import data from outside the database before they can be mixed calculated with data from within the database, which can also result in more tables in the database. Moreover, many external data are in a multi-layered JSON format, and multiple associated tables need to be created in relational databases for storage, which further exacerbates the problem of having too many intermediate tables.
The reason for putting intermediate data into the database is mainly to obtain the computing power of the database. Lack of strong computing power outside the database, while the computing power of the database is closed (it cannot compute data outside the database). In order to obtain the computing power of the database, these data can only be imported into the database, thus forming intermediate tables.
There are two engineering structural reasons in the database that could be accomplices to this matter:
A database is an independent process with computing power outside the application and not subordinate to any particular application. All applications share one database and can access it. An intermediate table generated for one application may be referenced by another application, which creates coupling between applications. Even if the creator of an intermediate table has been offline and is not used, it cannot be deleted because it may be used by another application, and the intermediate table will remain.
Database tables are organized and managed in a linear form. It’s OK when the quantity is small, but it can be chaotic when there are too many (thousands or even tens of thousands), and people usually use a tree structure to organize and manage numerous items. However, relational databases do not support this solution (its schema concept can be understood as only supporting two layers), which requires tables to be given longer names for classification. On the one hand, this is inconvenient to use, and on the other hand, it requires high levels of developing management. When work is urgent, specification is not considered, and when it goes online, these matters will be forgotten. Business A will have dozens of tables, while Business B will also have dozens. Over time, a large number of intermediate tables will be left behind.
Intermediate tables and related stored procedures consume a large amount of expensive data storage and computing resources, which is obviously not cost-effective.
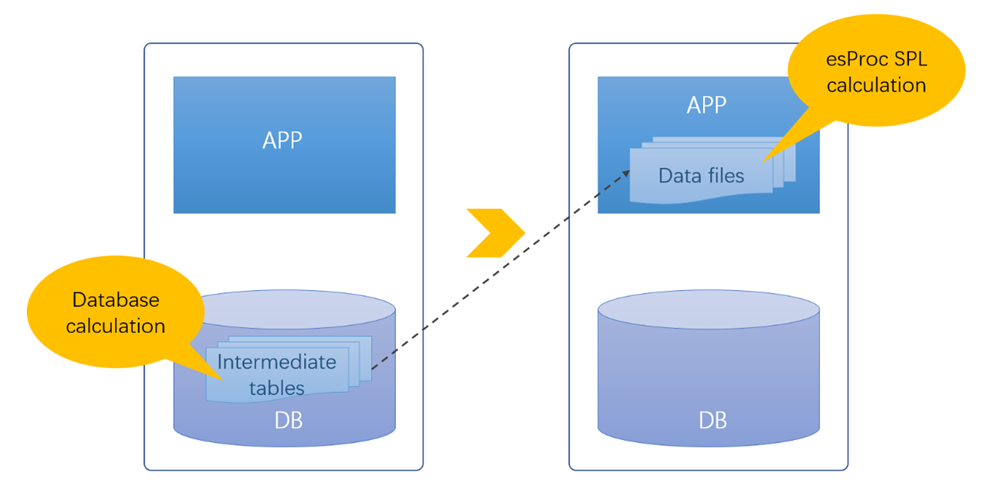
If an independent computing engine can be implemented so that calculations no longer rely on database services, then the database can be streamlined.
This is esProc SPL.
esProc SPL has open and integrable computing capabilities. Openness refers to the separation of computing power and storage, and the computation does not rely on storage, meaning that storage and computation are separated. Otherwise, if a specific storage scheme is required, the bloating of the database is simply replaced by bloating in another place. Integrability refers to the ability of embedding computing power into an application and become a part of the application, rather than being an independent process like a database, so as not to be shared by other applications (modules) and avoid coupling issues between applications.
The intermediate data no longer needs to be stored in the database in the form of data tables, but can be placed in the file system and provided with computing power by SPL. For read-only intermediate data, when using file storage, there is no need to consider rewriting and corresponding transaction consistency issues. The mechanism is greatly simplified, which can achieve better performance than databases. The file system can also adopt a tree organization scheme to classify and manage the intermediate data of various applications (modules), making it more convenient to use. This way, the intermediate data will naturally belong to a certain application module and will not be accessed by other applications. When an application is modified or taken offline, the corresponding intermediate data can be modified or deleted accordingly without worrying about coupling issues caused by sharing. The stored procedures used to generate intermediate data can also be moved outside the database as part of the application, without causing coupling issues.
| A | B | |
|---|---|---|
| 1 | =file("/data/scores.btx").cursor@b() | /Read as a cursor |
| 2 | =A1.select(CLASS==10) | /Filter |
| 3 | =A1.groups(CLASS;min(English),max(Chinese),sum(Math)) | /Group & Aggregation |
SPL provides high-performance binary file formats that utilize mechanisms such as compression, columnar storage, and indexing. It also supports parallel segmentation and related high-performance algorithms to further improve computational performance.
SPL can also directly implement mixed calculation of data outside and inside database, without the need for external data sources to be imported into the database. Instant data retrieval has better real-time performance and can fully utilize the advantages of the original data sources, which we have already discussed in multi-source mixed computing.
With the open and integrable computing capability of esProc SPL, it will be more convenient to design application frameworks. Computing can be placed in the most suitable position, without the need to deploy extra databases to obtain computing power. The database can focus on doing its most suitable thing, and complex and flexible computing can be left to SPL to solve, maximizing resource utilization.
Finally, esProc SPL is open source. It is here https://github.com/SPLWare/esProc.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version