

Final association query solution (JOIN Simplification and Acceleration Series 5)
By rethinking and redefining the equi-joins, we are able to simplify the join syntax. A direct and obvious effect is that queries become easy to write and understand. We offer three solutions – foreign key attributization, homo-dimension table interconnection, and sub table set-lization – to eliminate the JOIN keywords, making queries more conform to our natural thinking. The dimension alignment join syntax frees programmers from taking care of relationships between tables to let them create simple queries.
What’s more, the simplified join syntax helps avoid mistakes.
SQL allows writing join conditions in WHERE clause (which goes to the conventional Cartesian product-based join definition), and many programmers are accustomed to do so. There isn’t any issue when there are only two or three tables to be joined, but it is very likely that some join conditions are missed out if there are seven or eight or even a dozen of tables. The omission will cause a many-to-many complete cross join while the SQL statement is executing properly, leading to a wrong result (As previously mentioned, it is most probably that the SQL statement is wrong when a many-to-many join occurs) or a crashed database because of the quadratic scale of the Cartesian product if the table over which the join condition is missed out is too big.
We will not miss out any join condition by adopting the simplified join syntax because the syntax isn’t Cartesian product-based and denies the significance of the many-to-many relationship. With the syntax, the complete cross product is impossible.
SQL uses subqueries to handle a JOIN where sub tables need to be first grouped before aligning to the primary table. When there is only one sub table, we can JOIN tables first and then perform GROUP without using a subquery. Habitually and in an effort to avoid the subqueries, some programmers apply this rule to a JOIN with multiple sub tables by first writing JOIN and then GROUP, only to get a wrong result.
The dimension alignment join syntax will save programmers from this kind of mistake. It handles any number of sub tables in the same way without using subqueries.
The greatest impact of redefining JOIN operations is making associative queries convenient to achieve.
Now the agile BI techniques are popular. Vendors offer products claiming that they enable the businesspeople to perform queries and reports through drag and drop. The real-life effect, however, is far below expectation. IT resources are still a necessity. The reason behind this is that most of the business queries involve procedural computations that cannot be handled through drag and drop. Yet there are certain business queries that are non-procedural but still cannot be managed by businesspeople themselves.
Those are the status quo of join query service offered by most of the BI products. The service is a weakness of them. In our previous essays, we explained that it is the oversimplified SQL JOIN definition that is responsible for the difficulties in implementing join queries.
As a result, a BI product’s working mode becomes this: IT professionals pre-construct the model and the businesspeople make queries based on the model. The modeling is in fact the construction of a logical or physical wide table. That is to say, different models, which we call on-demand modeling, should be created for different joins. By doing this, a BI product loses its intended agility.
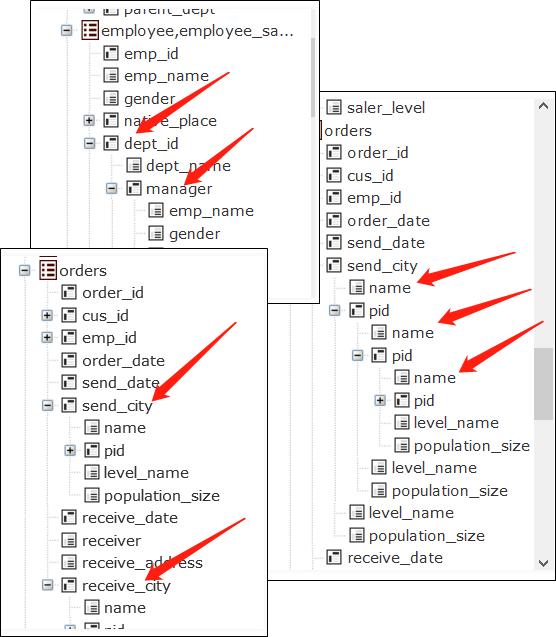
A different angle in looking at the JOIN operations will address the associative query issue at the root. The three join types we summed up and the corresponding solutions treat the multi-table associations as queries over one table, which, for the businesspeople, is easy to understand, though the attributes (fields) of a table become a little complicated. An attribute may have the sub-attributes (Referenced fields of the dimension table pointed by a foreign key), and a sub-attribute may also have the sub-attributes (with a multi-layer dimension table). Sometimes the field values are sets instead of single values (when a sub table is regarded as the field of the primary table). The perspective makes an ordinary join (A Chinese manager’s American employees are such an example), even a self-join, easy to understand, and a join where one table having same dimension fields not an issue any more (because each attribute has its own sub-attributes).
With this association mechanism, IT pros only need to define the data structure (metadata) once and create a certain interface (where table fields are listed in hierarchical tree structure instead of the commonly seen linear structure). The businesspeople can then perform joins themselves without turning to the IT department. Modeling is needed only when a change to the data structure occurs, rather than whenever a new associative query need appears. That constitutes the non-on-demand modeling. Under such a mechanism, a BI product becomes truly agile.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version