

Overcome SQL Headache - Intuitive Grouping
1. Aligned grouping
Example 1: List the number of countries whose official languages are respectively Chinese, English and French.
MySQL8:
with t(name,ord) as (select 'Chinese',1
union all select 'English',2
union all select 'French',3)
select t.name, count(countrycode) cnt
from t left join world.countrylanguage s on t.name=s.language
where s.isofficial='T'
group by name,ord
order by ord;
Note: The charset the table uses and the session charset should be the same.
(1) show variables like ‘character_set_connection’ View the charset the current session uses;
(2) show create table world.countrylanguage View the table’s charset;
(3) set character_set_connection=[Charset]Update the charset the current session uses
esProc SPL script:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.countrylanguage where isofficial='T' ") |
| 3 | [Chinese,English,French] |
| 4 | =A2.align@a(A3,Language) |
| 5 | =A4.new(A3(#):name, ~.len():cnt) |
A1: Connect to the database;
A2: Get all records of official languages;
A3: List three official languages;
A4: Align all records with A3’s members in order by Language;
A5: Create a table sequence consisting of language name and the number of countries that use the language.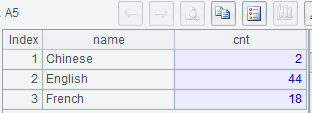
Example 2: List the number of countries whose official languages are respectively Chinese, English, French and others.
MySQL8:
with t(name,ord) as (select 'Chinese',1 union all select 'English',2
union all select 'French',3 union all select 'Other', 4),
s(name, cnt) as (
select language, count(countrycode) cnt
from world.countrylanguage s
where s.isofficial='T' and language in ('Chinese','English','French')
group by language
union all
select 'Other', count(distinct countrycode) cnt
from world.countrylanguage s
where isofficial='T' and language not in ('Chinese','English','French')
)
select t.name, s.cnt
from t left join s using (name)
order by t.ord;
esProc SPL script:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.countrylanguage where isofficial='T' ") |
| 3 | [Chinese,English,French,Other] |
| 4 | =A2.align@an(A3.to(3),Language) |
| 5 | =A4.new(A3(#):name, if(#<=3,~.len(), ~.icount(CountryCode)):cnt) |
A4: Align all records with A3.to(3) in order by Language, and append a group containing non-aligned records;
A5: Over the last group, calculate the number of countries with other CountryCodes.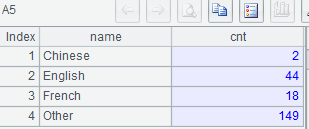
2. Enum grouping
Example 1: List the number of cities of different types according to the specified order.
MySQL8:
with t as (select * from world.city where CountryCode='CHN'),
segment(class,start,end) as (select 'tiny', 0, 200000
union all select 'small', 200000, 1000000
union all select 'medium', 1000000, 2000000
union all select 'big', 2000000, 100000000
)
select class, count(1) cnt
from segment s join t on t.population>=s.start and t.population<s.end
group by class, start
order by start;
esProc SPL script:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN' ") |
| 3 | =${string([20,100,200,10000].(~*10000).("?<"/~))} |
| 4 | [tiny,small,medium,big] |
| 5 | =A2.enum(A3,Population) |
| 6 | =A5.new(A4(#):class, ~.len():cnt) |
A3: ${…} is the macro replacement, which calculates the expression enclosed by the braces and takes the result as a new expression for recalculation. Here the final result is the sequence [“?<200000”,“?<1000000”,“?<2000000”,“?<100000000”].
A5: Over each record in A2, compare it with A3’s first condition, and add it to the corresponding group if the condition is satisfied.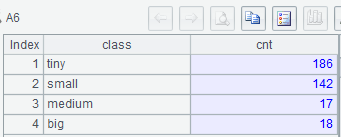
Example 2: List the numbers of metropolises in East China, in other areas in China, and the number of non-metropolises in China.
MySQL8:
with t as (select * from world.city where CountryCode='CHN')
select 'East&Big' class, count(*) cnt
from t
where population>=2000000
and district in ('Shanghai','Jiangshu', 'Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Other&Big', count(*)
from t
where population>=2000000
and district not in ('Shanghai','Jiangshu','Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Not Big', count(*)
from t
where population<2000000;
esProc SPL script:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN' ") |
| 3 | [Shanghai,Jiangshu, Shandong,Zhejiang,Anhui,Jiangxi] |
| 4 | [?(1)>=2000000 && A3.contain(?(2)), ?(1)>=2000000 && !A3.contain(?(2))] |
| 5 | [East&Big,Other&Big, Not Big] |
| 6 | =A2.enum@n(A4, [Population,District]) |
| 7 | =A6.new(A5(#):class, A6(#).len():cnt) |
A5: enum@n puts records that cannot meet any condition specified in A4 in the appended last group.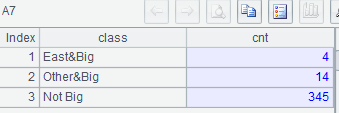
Example 3: List the numbers of metropolises all over China, in the East China, and the non-metropolises in China.
MySQL8:
with t as (select * from world.city where CountryCode='CHN')
select 'Big' class, count(*) cnt
from t
where population>=2000000
union all
select 'East&Big' class, count(*) cnt
from t
where population>=2000000
and district in ('Shanghai','Jiangshu','Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Not Big' class, count(*) cnt
from t
where population<2000000;
esProc SPL script:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN' ") |
| 3 | [Shanghai,Jiangshu, Shandong,Zhejiang,Anhui,Jiangxi] |
| 4 | [?(1)>=2000000, ?(1)>=2000000 && A3.contain(?(2))] |
| 5 | [Big, East&Big, Not Big] |
| 6 | =A2.enum@rn(A4, [Population,District]) |
| 7 | =A6.new(A5(#):class, A6(#).len():cnt) |
A6: If a record in A2 satisfies all conditions in A4, enum@r will add it to the corresponding group.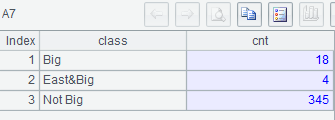
3. Position-based grouping
Example 1: List the numbers of cities of different types.
MySQL8: See the SQL code in Enum grouping.
esProc SPL script:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN' ") |
| 3 | =[0,20,100,200].(~*10000) |
| 4 | [tiny,small,medium,big] |
| 5 | =A2.group@n(A3.pseg(Population)) |
| 6 | =A5.new(A4(#):class, ~.len():cnt) |
A5: First calculate the segment number in A3 for A2.Population, and then put the current record into the corresponding group.
4. Grouping in the original order by comparing adjacent records
Example 1: List gold medal counts for the first 10 Olympic Games (Only the top three are recorded and there are no identical standings).
MySQL8:
with t1 as (select *,rank() over(partition by game order by gold\*1000000+silver\*1000+copper desc) rn from olympic where game<=10)
select game,nation,gold,silver,copper from t1 where rn=1;
esProc SPL script:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query("select * from olympic where game<=10 order by game, gold*1000000+silver*1000+copper desc") |
| 3 | =A2.group@o1(game) |
A3: Group records by game in the original order and get the first record from every group to form a new table sequence.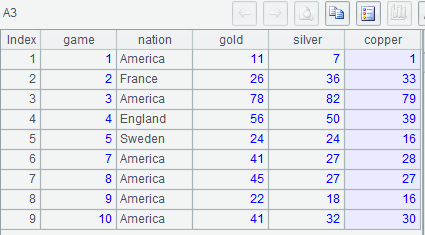
Example 2: Count the Olympic Games when a nation consecutively ranks first for the total number of medals.
MySQL8:
with t1 as (select *,rank() over(partition by game order by gold\*1000000+silver\*1000+copper desc) rn from olympic),
t2 as (select game,ifnull(nation<>lag(nation) over(order by game),0) neq from t1 where rn=1),
t3 as (select sum(neq) over(order by game) acc from t2),
t4 as (select count(acc) cnt from t3 group by acc)
select max(cnt) cnt from t4;
t1: Calculate the standings of each Game;
t2: List champion of each Game and make a mark with neq according to whether or not the winning nation changes (the value of neq is 1 if the winner is different from the previous one, and 0 if the winners are the same;
t3: Accumulate the number of 1 and 0 respectively into acc. This ensures that continuous same nations have same acc values and nonadjacent nations have different acc values.
esProc SPL script:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query("select * from olympic order by game, gold*1000000+silver*1000+copper desc") |
| 3 | =A2.group@o1(game) |
| 4 | =A3.group@o(nation) |
| 5 | =A4.max(~.len()) |
A4: Put continuous records with same nations into same group in the original order;
A5: Find the biggest length among groups, which is the biggest number of consecutive champions.
Example 3: List Olympic medal counts records for the nation that won the longest row of championships.
MySQL:
with t1 as (select *,rank() over(partition by game order by gold\*1000000+silver\*1000+copper desc) rn from olympic),
t2 as (select *,ifnull(nation<>lag(nation) over(order by game),0) neq from t1 where rn=1),
t3 as (select *, sum(neq) over(order by game) acc from t2),
t4 as (select acc,count(acc) cnt from t3 group by acc),
t5 as (select * from t4 where cnt=(select max(cnt) cnt from t4))
select game,nation,gold,silver,copper from t3 join t5 using (acc);
esProc SPL script:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query("select * from olympic order by game, gold*1000000+silver*1000+copper desc") |
| 3 | =A2.group@o1(game) |
| 4 | =A3.group@o(nation) |
| 5 | =A4.maxp(~.len()) |
A5: Find the group containing the most members.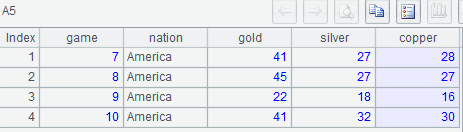
Example 4: Find the biggest number of Olympic Games when the gold medals of top 3 winners increase consecutively.
MySQL8:
with t1 as (select game,sum(gold) gold from olympic group by game),
t2 as (select game,gold, gold<=lag(gold,1,-1) over(order by game) lt from t1),
t3 as (select game, sum(lt) over(order by game) acc from t2),
t4 as (select count(*) cnt from t3 group by acc)
select max(cnt)-1 cnt from t4;
esProc SPL script:
| A | |
|---|---|
| 1 | =connect("mysql") |
| 2 | =A1.query("select game,sum(gold) gold from olympic group by game order by game") |
| 3 | =A2.group@i(gold<=gold[-1]) |
| 4 | =A3.max(~.len())-1 |
A3: Group records by game according to the specified condition. A new group will be created if the current number of gold medals is less than or equal to the previous number of gold medals.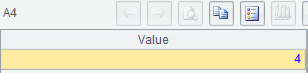
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

