

Python vs. SPL 2--Set
A sequence consists of objects (or events) that are arranged in line, in this way, each element is either in front of or behind another element. Therefore, the order of the elements is quite important.
A set is a collective of concrete or abstract objects with particular attribute. The objects that make up the set are called the elements of the set, where there are no duplicate element and the order of the elements does not matter.
The above two paragraphs are the mathematical definitions of sequence and set, then what do they look like in Python and esProc SPL (SPL for short)?
Python
Simple set
Introduction of set
The native sequence in Python is a kind of data structure called list, taking the form of [1,2,3,4], which satisfies the basic definition of a sequence, that is, the order of the elements is important and duplicate elements are allowed.
The sequence in numpy library of Python is the data structure called array in the form of [1 2 3 4]. It also meets the basic definition of a sequence, i.e., the order of the elements is important and duplicate elements are allowed, but it does not support elements of different types.
The sequence in Pandas library of Python is the data structure called Series in the form of 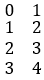 . It also satisfies the basic definition of a sequence, i.e., the order of elements is important and duplicate elements are allowed, except that Series sequence has its own index.
. It also satisfies the basic definition of a sequence, i.e., the order of elements is important and duplicate elements are allowed, except that Series sequence has its own index.
The native set in Python is a kind of data structure call set, taking the form of {1,2,3,4}, which meets the basic definition of a set, that is, the order does not matter and no duplicate element is allowed.
As for the commonly used set data structure, there are four of them. Although they are inter-convertible, the conversion itself is relatively costly with a large number of syntaxes.
Basic operation
The basic operations on a set include insertion, deletion, modification and selection, which are also a must for us to grasp. However, the syntaxes of these four data structures are not the same at all, and here we illustrate the operation of inserting elements.
Data structure |
Example |
Code |
Annotation |
Result |
list |
l=[1,2,3,4] |
l.append(5) |
Append at the end |
[1,2,3,4,5] |
l.insert(2,5) |
Insert at a specified position |
[1,2,5,3,4] |
||
array |
a=[1 2 3 4] |
np.hstack((a,[5])) |
Insert in horizontal position |
[1 2 3 4 5] |
np.vstack((a,[5,6,7,8])) |
Insert in vertical position |
[[1 2 3 4] [5 6 7 8]] |
||
Series |
s= |
s.append( |
Append a Series |
|
s[4]=5 |
Insert with index |
|
||
set |
st={1, 2, 3, 4} |
st.add(5) |
Append |
{1,2,3,4,5} |
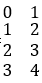
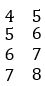

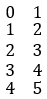
Other operations such as deletion, modification and selection, you can search by yourselves and a common conclusion can be easily got, that is, the syntax of the same operation is completely different for different data structures. Therefore, the best way to be proficient at them is to memorize them by rote and practice them on purpose.
Set operation
The commonly performed operations on set are intersection, difference, union, and conjunction. But the syntax of Python is difficult to figure out, leaving an impression that each kind of data structure is a brand-new language and requires a new kind of syntax. In the following we’ll illustrate with the intersection operation on the set:
Data structure |
Example |
Code |
Result |
list |
l1=[1,2,3] l2=[2,3,4] |
insect_l=[val for val in l1 if val in l2] |
[2, 3] |
array |
a1=[1 2 3] a2=[2 3 4] |
insect_a=np.intersect1d(a1,a2) |
[2 3] |
Series |
s1= s2= |
insect_s=pd.merge(s1,s2,on="v") |
|
set |
st1={1,2,3} st2={2,3,4} |
insect_st=st1.intersection(st2) |
{2,3} |
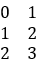
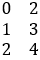

The data structure of “list” is easy and there is no ready-made set operation function, so we have to code on our own. In addition to using merge function on “Series”, we can also convert it to “array” and then perform operations on it. But this kind of operation does not belong to “Series”. Four kinds of data structures indicate four kinds of syntaxes.
Two-dimension set -- table
Introduction of set
There is no native data structure of two-dimension table in Python, and the commonly used two-dimension table structure is the Dataframe in Pandas, which is also a set of Series and the form of it is:

Each column of Dataframe is one Series. Although each Series does not support elements of different types, Dataframe supports Series of different types, for example, the int-type Series where the whole column is integers and the object-type Series where the whole column is strings, and the form of it is:

In this table, the “number” column is int64 type, and “string” column is object type.
The data structure of Dataframe, being more complex and not the usual two-dimension table structure, is essentially a matrix, and all operations have to adapt themselves to the matrix to perform.
Basic operation
The operations on Dataframe are similar to those on Series, and these two can be considered as one and the same. Here we still take elements insertion for example.
1. Insert rows
df.loc[4]={"a":5}
The result is:
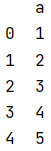
2. Insert columns
df["b"]=["a","b","c","d","e"]
The result is:

Compared with the element insertion operation on Series, the logic behind them stays the same, i.e., inserting through index, except that there is one more dimension in Dataframe.
Set operation
The set operations on Dataframe are also the same with those on Series, and here is an example of intersection:
1. Create two Dataframes
df1=pd.DataFrame({"a":[2,3,4,5,6]})
df2=pd.DataFrame({"a":[3,4,5,6,7]})
The result is:
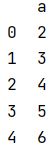

2. Intersection
insect_df=pd.merge(df1,df2,on="a")
The result is:

Python can complete these basic operations and set operations very well, but by observing the above simple examples, it is also obvious that Python is not easy for us to get started, especially Numpy and Pandas, the two third-party libraries. Both of them can be considered as independent languages, so it takes a lot of efforts to achieve proficiency in solving real-world problems with them.
esProc SPL
Simple set
Introduction of set
There is only one data structure of set in SPL, that is, sequence, which allows duplicate elements and the order of elements does matter. The sets in SPL are generalized sets, which allow different types of elements in the set and even the elements can be sets themselves.
Basic operation
The basic operations in SPL are easy, and here we take the insertion, deletion, modification and selection operations on sequence for example:
Data structure |
Example |
Operation |
Code |
Annotation |
Result |
sequence |
s=[2,3,4,5] |
Insert |
s1=s|6 |
Append at the end |
[2,3,4,5,6] |
s.insert(2,[1,7]) |
Insert at a specified position |
[2,1,7,3,4,5] |
|||
Delete |
s\[4,3] |
Delete a specified element |
[2,5] |
||
s.delete([2,4]) |
Delete the element at the specified position |
[2,4] |
|||
Modify |
s([1,3])=[8,9] |
Modify the element at the specified position |
[8,3,9,5] |
||
Select |
s([1,3,2]) |
Select by position |
[2,4,3] |
The syntax is quite simple and easy to master.
Set operation
Then we introduce the set operations in SPL, which can be even easier with operators.
Data structure |
Example |
Operation type |
Code |
Result |
sequence |
s1=[1,2,3,4] s2=[2,3,4,5] |
Intersection |
s1^s2 |
[2,3,4] |
Difference |
s1\s2 |
[1] |
||
Union |
s1&s2 |
[1,2,3,4,5] |
||
Conjunction |
s1|s2 |
[1,2,3,4,2,3,4,5] |
Two-dimension set -- table
Introduction of set
The tables in SPL are called table sequences, which are sequences with field structure in essence. And the form of table sequence is:
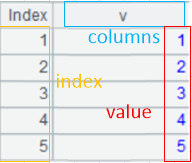
Each row of the table sequence is called one record, and reference of some records of the table sequence is called record sequence. And the records can exist outside the table sequence.
Basic operation
The essence of table sequence is sequence, and the records are its elements, thus the table sequence is to the records as the sequence is to the elements. These two are almost identical. For example, both table sequence and sequence delete and insert elements using the “delete” and “insert” function respectively.
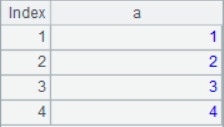
1. Create the table sequence
T=[1,2,3,4].new(~:a)
The result is:
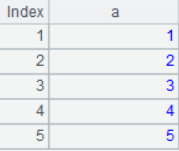
2. Insert rows
T=T.insert(0,5:a)
The result is:
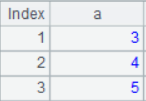
3. Delete rows
T=T.delete([1,2])
The result is:
Set operation
Record sequence is reference of some records of the table sequence. Set operations can also be performed with operators.
Select two record sequences from a certain table:
T=[2,3,4,5,6,7].new(~:a)
A1=T.select(a<7)
A2=T.select(a>2)
The result is:
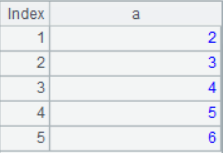
1. Intersection
A1^A2
The result is:
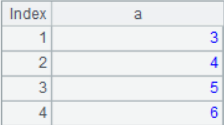
2. Difference
A1\A2
The result is:

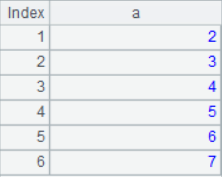
3. Union
A1&A2
The result is:
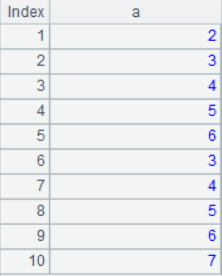
4. Conjunction
A1|A2
The result is:
The table sequences are independent objects, different from each other, thus it may be a little troublesome to perform set operations on them.
1. Create the table sequence
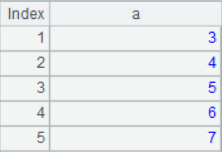
T1=[2,3,4,5,6].new(~:a)
T2=[3,4,5,6,7].new(~:a)
The result is:
2. Intersection
insect= [T1,T2].merge@i(a)
The result is:
3. Difference
diff= [T1,T2].merge@d(a)
The result is:
4. Union
union= [T1,T2].merge@u(a)
The result is:
5. Conjunction
conj=T1|T2
The result is:
Summary
The set data structures of Python are diverse, and the same operation may be quite different because of the different data structures. Some data structures are simple to understand, but the operations are inconvenient, such as “list”; some operations are easy but the data structures are complex and hard to understand, such as “Series”. These problems require the programmers to master all the operations of all data structures. In addition, there is no native two-dimension table in Python, so many structured data are difficult to process. What’ more, the third-party library Pandas has Dataframe data structure, but it is still obscure to understand, even simple set operations like intersection, difference, union and conjunction are very complicated and inefficient to perform.
On the contrary, the data structures in SPL are quite simple. The set is the very sequence, and the structure of two-dimension table is the same with that of the simple set -- sequence. Almost all the operations are in the same line with one another, therefore, once mastering the simple set operations, we can write simple and efficient code, achieving quick coding as well as quick performing.
Like a wild plant, Python is quite adaptable but is difficult to handle with. While the original Python is far too simple, making it cumbersome and inefficient to use. So instead of a language, Python is more of a collective of more than N third-party library languages. However, SPL has been elaborately designed to handle structured data and is a professional tool that is really easy to master.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version