

Full-text index of SPL
In structured data query, the requirement for full-text retrieval often arises. For example, we need to search for the countries whose name starts with Ch in the country table, or search for the records that contain water in the “content” field of “post” table.
Although the search-oriented full-text retrieval can solve this problem, it is not suitable for structured data computing task for the reason that it will face the large-scale web page with huge amount of data, and hence the index is also huge, and it may also involve the understanding of very professional natural language and the word segmentation technology.
Usually, the scale of structured data is much smaller than that of web page faced by search, and the scope for searching structured data will generally be limited to a certain field, therefore, the amount of data involved will be smaller. Moreover, the field content is usually a few characters or a sentence, and rarely a whole article like a web page.
In view of this feature of structured data, SPL adopts simpler technology, and provides a lightweight full-text index scheme.
Merging multiple indexes
The technology of merging multiple indexes can make multiple indexes work together to a certain extent, and this technology is also used in the full-text search solution of SPL.
Taking the user table as an example, we want to use the index of a single field to search for the users whose birthday is 2020-12-30 and whose city is Chicago. First, let’s look at the general process of creating the sorting index by city, as shown in Figure 1 below:
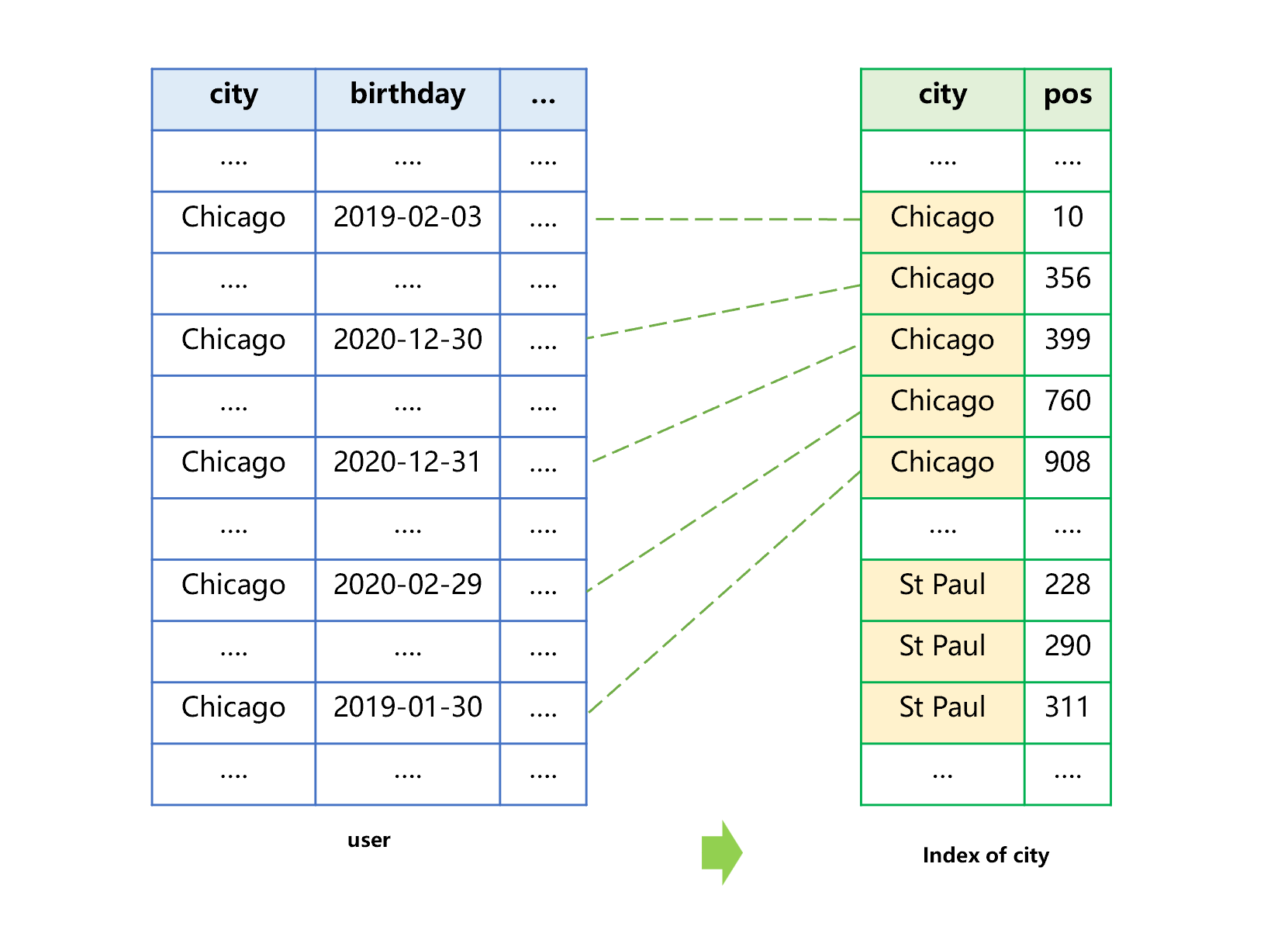
Figure 1 Creating an index by city
When creating the index, first sort the cities, and then store the sorted cities into the index together with their position (pos) recorded in the original table. For the convenience of understanding, we use natural number to represent the position in original table. The larger the value, the closer to the tail position.
We can see from figure 1 that the sorting process for generating index will not change the order of multiple Chicago records in the original table. Therefore, in the index, not only will the same city (e.g., Chicago) be stored together, but the pos of multiple records of same city in original table are also sorted from small to large.
Likewise, the process of creating an index by birthday is the same. See Figure 2 below:
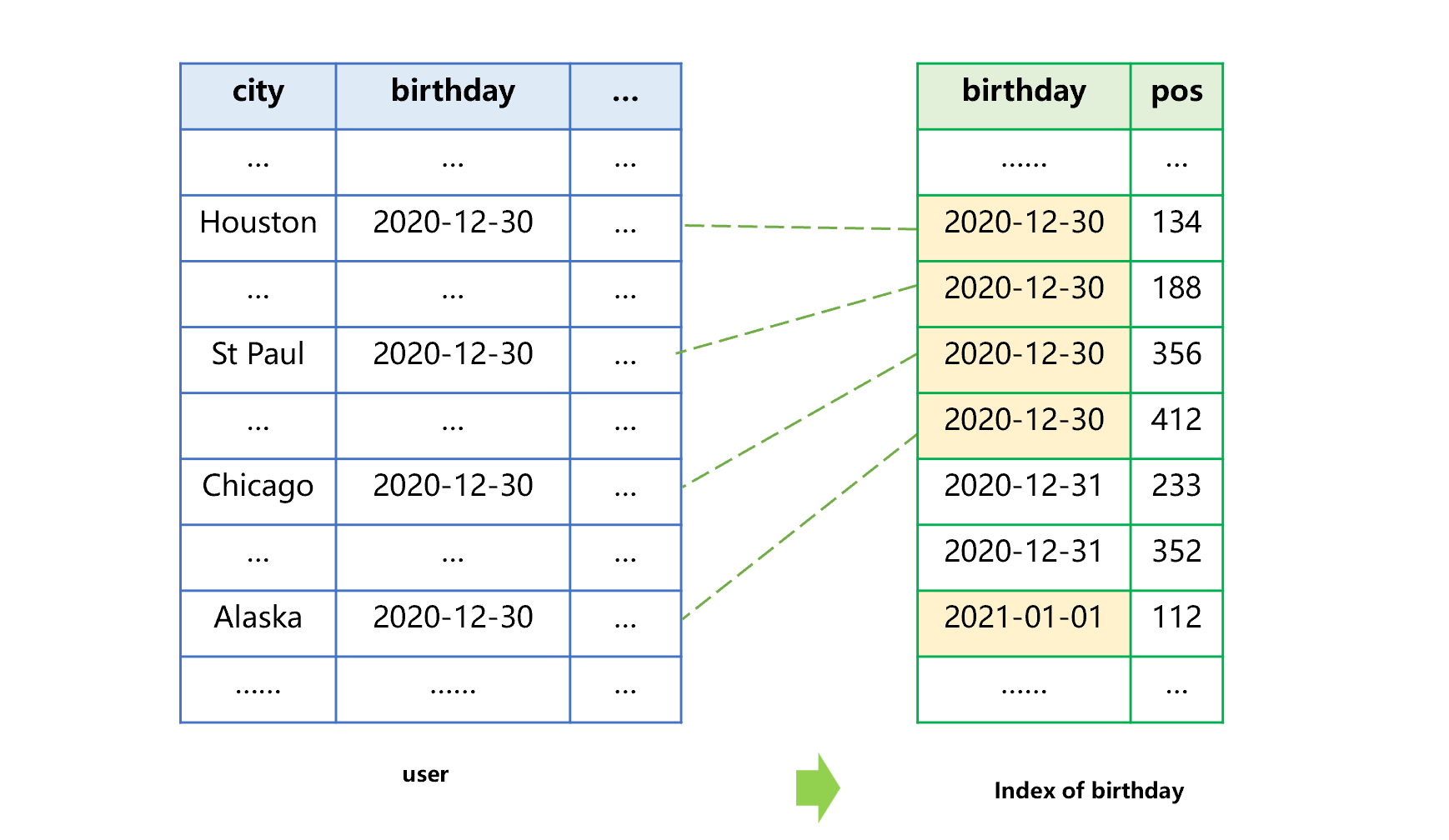
Figure 2 Creating an index by birthday
After the two indexes are established, using the city index can quickly locate the users whose city is Chicago, as shown in Figure 3 below:
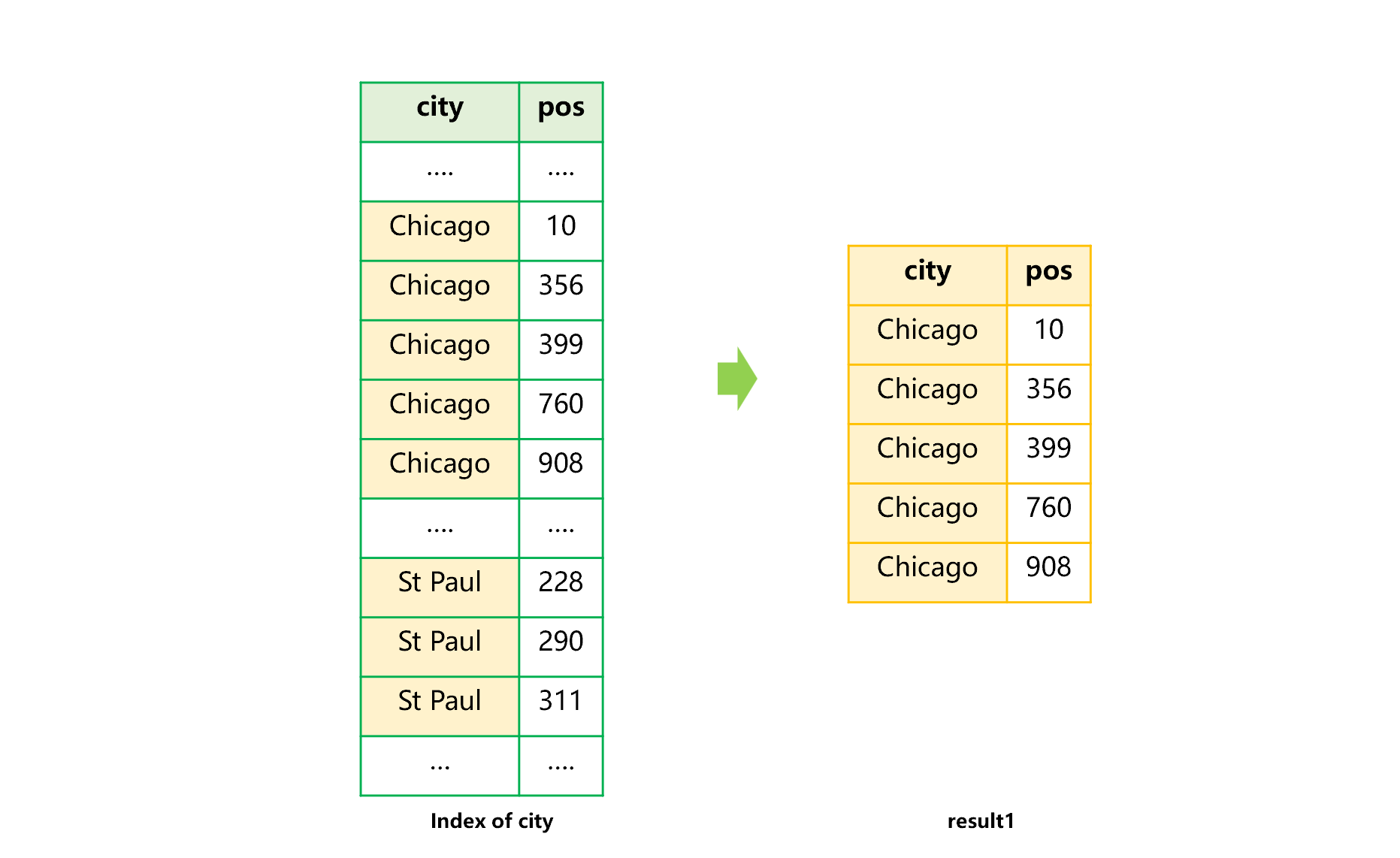
Figure 3 Searching for Chicago with index of city
As can be seen from figure 3 that when we want to continue to search for birthday = 2020-12-30 from result 1, the direct use of the birthday index does not work.
Similarly, using the birthday index can quickly locate 2020-12-30, as shown in Figure 4 below:

Figure 4 Searching for 2020-12-30 with birthday index
Likewise, to find the city Chicago from result 2, the direct use of the city index does not work either.
The merging multiple-index technology of SPL can utilize both the city index and the birthday index to work together to find final data. The general process is shown as below:
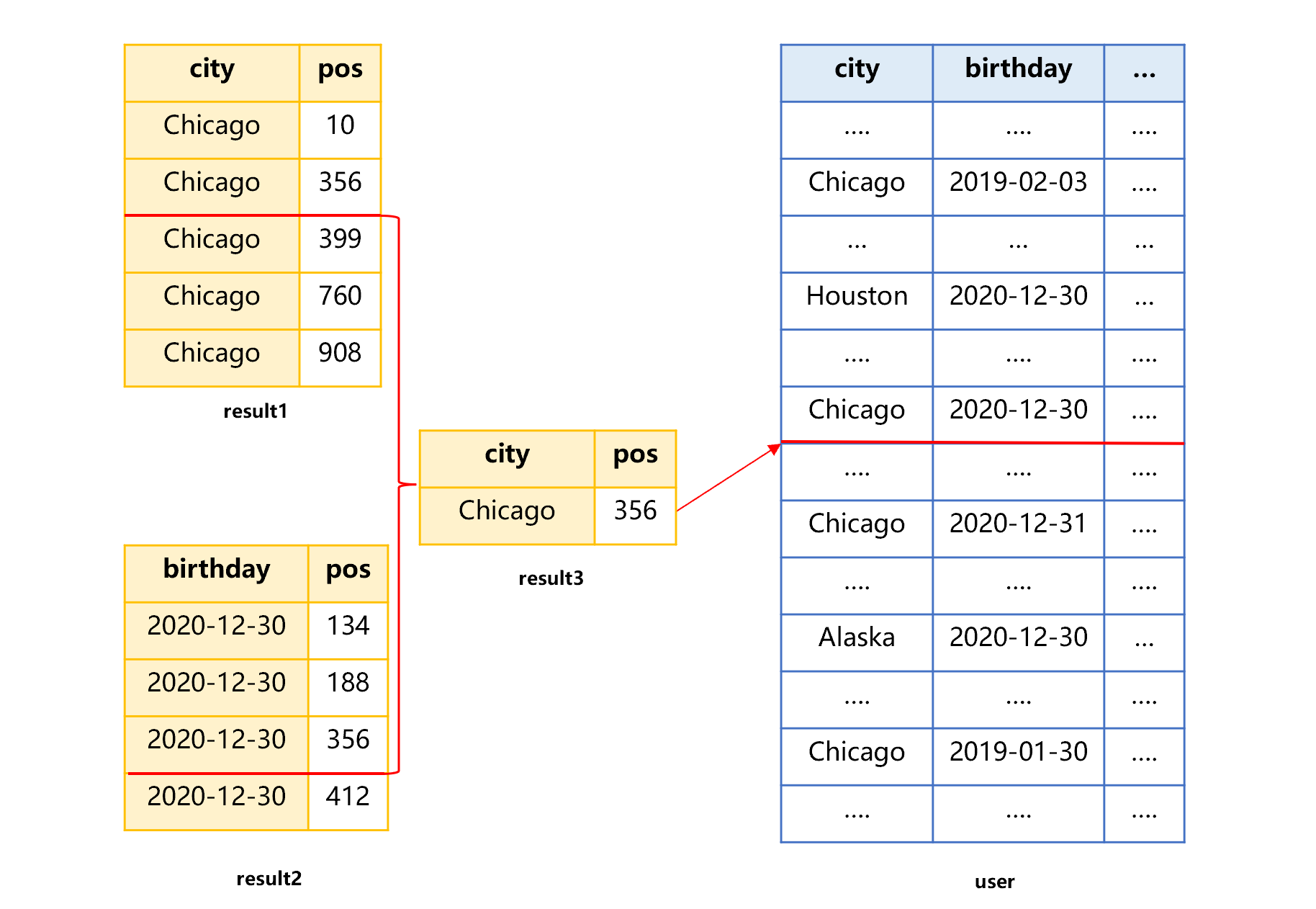
Figure 5 Merging multiple indexes
In this figure, both result 1 and 2 are ordered by the physical position (pos) of record. In this case, as long as using the merge algorithm to get the intersection (result 3) of the two results, we can get an index that satisfies two conditions of city and birthday, and then, using the position of record in result 3, the record that meets the conditions can be taken out from the user table.
However, this algorithm does not necessarily have more advantages in terms of complexity than traversing and calculating whether the birthday condition is true in the records that meet the city condition, because the latter algorithm only needs to traverse one set that meets the city condition, while this algorithm needs to traverse two sets: result 1 and result 2.
The advantage of merging multiple indexes is reflected in practice. To be specific, when finding the intersection through merging, there is no need to read the records of the original data table to calculate whether the birthday condition is true, just compare the indexes. Moreover, the index blocks may already be stored in memory. Even they are in external storage, they are stored continuously in only two columns (to-be-searched ‘TBS’ field and physical position) and in row-based storage format. Therefore, the reading performance is much better than the original dataset with multiple fields, discontinuous storage and columnar storage. In this way, the performance of merging and comparing will be better than that of reading and judging.
If we choose the smaller one of result 1 and result 2 as the reference to merge the larger one, we can stop merging once the traversal of smaller one is over, and the members in the larger one that are not yet traversed can be abandoned. In this way, the total number of traversing will not be very large. When creating an index, we can usually know the number of records of result 1 and 2.
Merging multiple indexes is also applicable to the case where there are conditions on more fields.
For multiple field conditions written on the cursor, such as city==“Chicago” && birthday==date(“2020-12-30”) &&, SPL will automatically find the available index in the given index file list and merge without the intervention of programmer.
Full-text index
The full-text retrieval for structured data refers to searching whether a certain string field contains the records of a certain determined substring. If the condition is like(X, “abc*”), that is, the substring is located in the front of TBS field, we can use the index of this field to locate quickly. Take the country table as an example. To use the sorting index of country names to search for the country whose name starts with Ch, the general process is as shown in Figure 6:
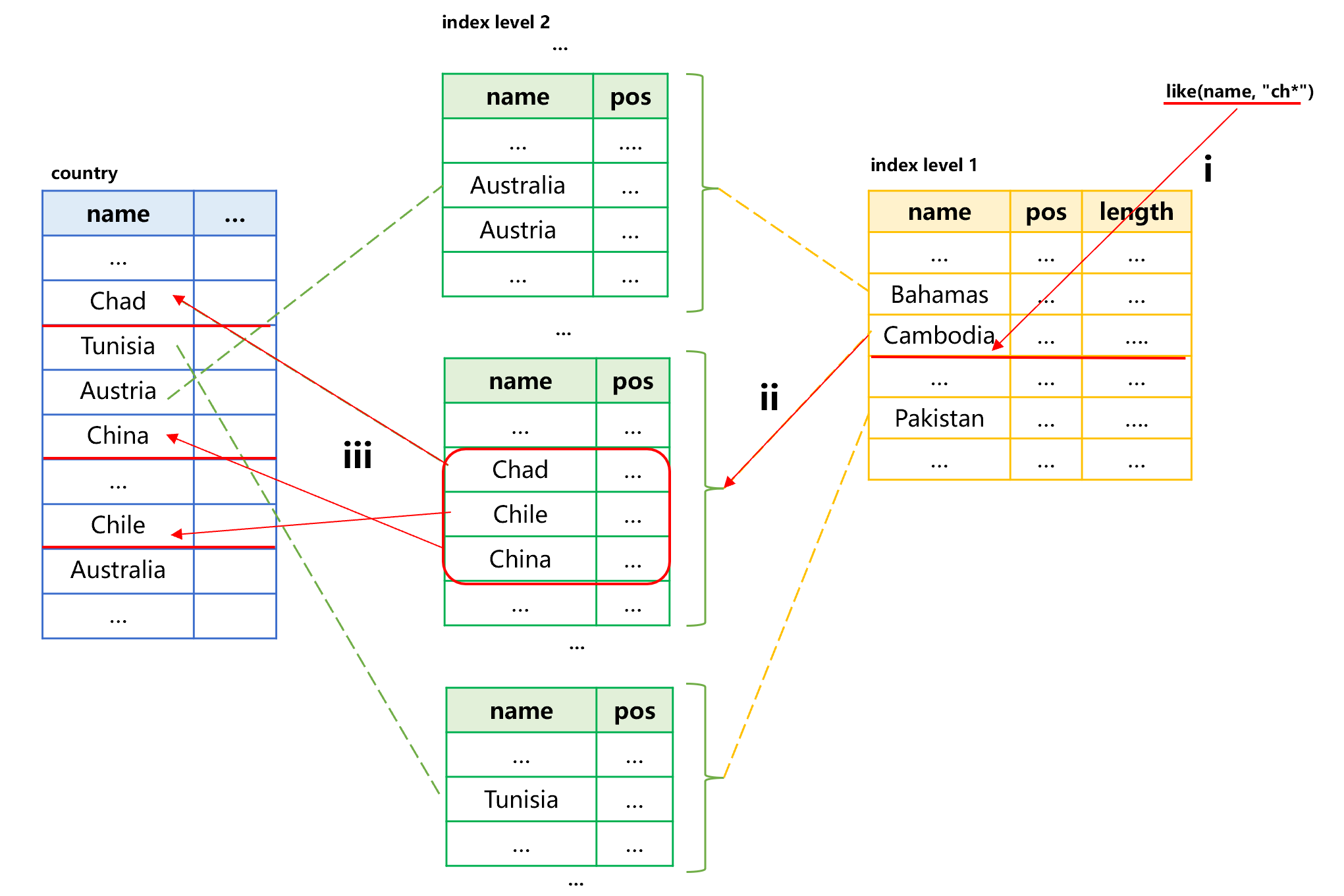
Figure 6: Search for countries by index
In this figure, assume the index of country names has two levels. Since the index is ordered by name, the records that meet the condition like(name, “Ch*”) are definitely stored continuously in the sorting index level 1 and 2. The search is divided into three steps, i), find the names starting with Ch from the index level 1, which are all in the Cambodia segment, and obtain their position and length in index level 2 segment; ii), read the index level 2 segment into the memory according to their position and length to find the first country Chad starting with Ch, and continue traversing until there is a country that does not start with Ch, at this time, we can get the position of all records starting with Ch in the original table; iii), sort these positions, and go to the original table to obtain target record.
When SPL finds the conditions such as like(name, “ch*”), it will automatically check the original table for a sorting index and take advantage of the index if available.
If the substring is located in the middle of the TBS fields, the sorting index or hash index does not work. Instead, we need to establish an index for text, that is, the full-text index.
For example, create a full-text index for the content field of post table to search for the records containing water in this field, and the condition is like(content,“*water*”).
The process of creating a full-text index in SPL is shown as below:
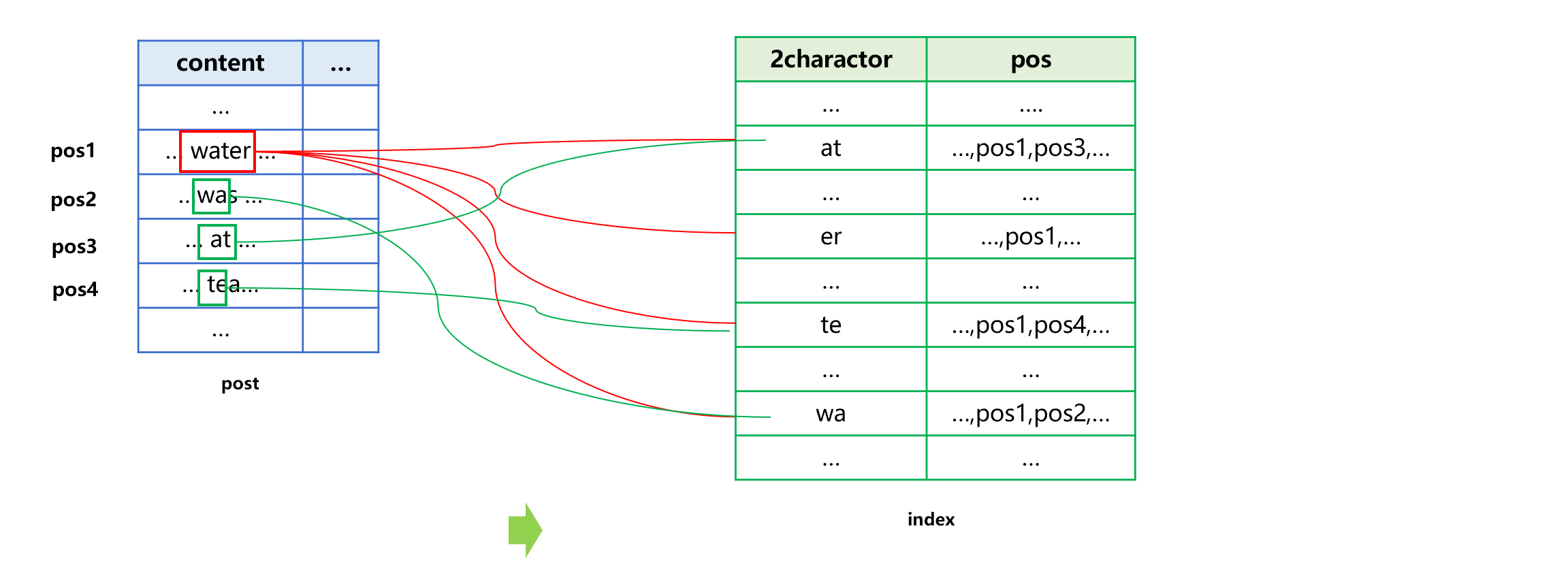
Figure 7: Creating full-text index
First, take apart the string in the content field, and take out all combinations of two (or three) characters that have appeared. For example, from the ‘water’ in the content field of record at pos1, we can get four combinations, wa, at, te, and er, and save them together with pos1, where the record containing “water’ is located.
The string of every record in content field needs to be got in this way. For example, when ‘was’ is split as wa and as, it also needs to store the two combinations together with the pos2 where the record appears. Since wa is already appeared, it should be merged and stored together.
After the content of all records are taken, sort all combinations and store them into the full-text index together with the corresponding record positions.
The index built in this way will not be very large. There are about thousands of commonly used characters (Chinese characters and English characters). If only two characters are taken, the maximum number of such combinations is thousands by thousands, about one million to ten million, which is not very large. If we take three characters, the number of combinations will be several billion to ten billion, which are still in the capacity scope of any modern relatively advanced server.
With the full-text index, we can search for the records containing water. See Figure 8 below for general process:
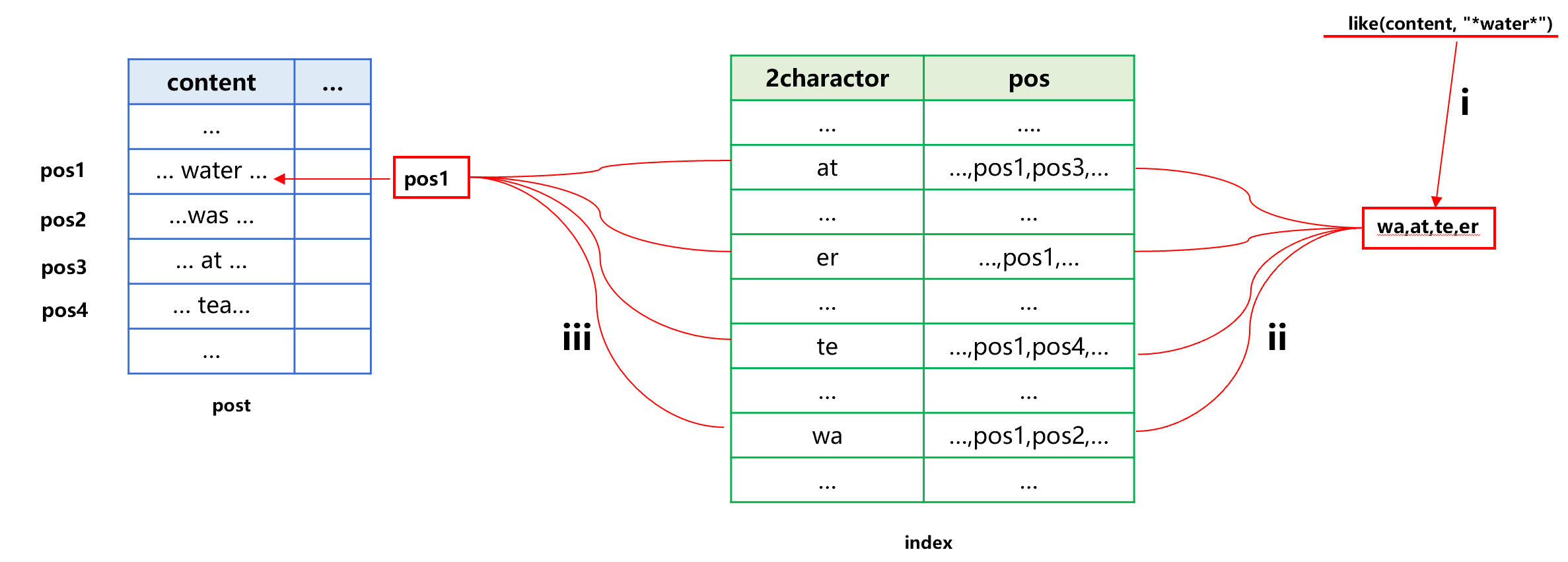
Figure 8 Search by full-text index
Step i, take out four combinations wa, at, te, and er from the TBS water; Step ii, find four results 1 to 4 corresponding to the four combinations from the full-text index; Step iii, employ the index merging technology to calculate the intersection of results 1 to 4, and sort the positions of original table records in the intersection to get the original table records, which is a new set.
In this new set, the four combinations ‘wa, at, te, and er’ are definitely appear at the same time, but they are not necessarily water. Therefore, we need to further search based on the condition like(content,“*water*”) in this new set so as to get the final result.
As can be seen from the introduction above, the full-text index greatly reduces the amount of computation compared to hard traversal, and does not need the high-cost full-text search technology like search engine.
The full-text index code of SPL is roughly as follows:
| A | |
|---|---|
| 1 | =file("post.ctx").open() |
| 2 | =file("post.idx") |
| 3 | =A1.index@w(A2;content) |
| 4 | =A1.icursor(like(content,"*water*");A2) |
In A3, use the index@w to create a full-text index, and store it to the index file post.idx. At present, the two-character scheme is used, which is already sufficient in many scenarios.
When searching in A4, specifying the index file A2 allows for the direct use of ‘like’ as a condition.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version