

SPL Operations for Beginners
As a structured computation engine, SPL brings a lot of brand-new concepts, which go far beyond the traditional relational-algebra-based coding systems. Maybe they are strange to programmers or users familiar with SQL or Java. This essay is intended to help understanding those SPL concepts correctly and master the key ones quickly.
Discreteness and general sets
In SPL, record is a basic data type, and a data table is a set of records. A record which is also a member of a data table is allowed to exist and operate separately and repeatedly outside of the table. Such a record is a discrete record.
One example is to calculate the age difference and salary difference between Jack and Rose according to employee table. The SPL code is as follows:
A |
B |
|
1 |
=file("employee.btx").import@b(name,age,salary) |
|
2 |
=A1.select@1(name=="Jack") |
=A1.select@1(name=="Rose") |
3 |
=A2.age-A3.age |
=A2.salary-A3.salary |
A2 and B2 respectively perform filtering to get target records. The two are independent of the employee table and can operate separately. A3 and B3 respectively use the two discrete records to perform two computations.
Note that the two discrete records are not copies. A2 and B2 reference the original records directly, avoiding extra time consumption the copying operation brings and reducing space usage.
SPL discrete records can be computed to generate a new set, that is, a new data table, through certain operations, such as the commonly seen intersection, union, difference, and other set-operations. For instance, the following SPL code performs multiple set operations based on the employee table:
A |
B |
|
1 |
=file("employee.btx").import@b(name,dept,gender,salary) |
|
2 |
=A1.select(gender=="F") |
=A1.select(salary>=4000) |
3 |
=A2^B2 |
=A2\B2 |
4 |
=A2&B2 |
|
A2 and B2 perform filtering to get records of female employees and those of employees whose salaries are above 4000 respectively and generate two new sets.
A3 calculates intersection of two new sets and returns records of female employees who get a salary above 4,000. B3 calculates difference of two new sets and returns records of female employees whose salaries are below 4,000. A4 calculates union of two new sets and returns records of all female employees and of male employees whose salaries are 4,000 and above. All these set operations have their applications in actual business scenarios.
All records participating in the set operations are discrete records that are also members of A1’s table sequence. No copying is involved.
Actually, the concept of discrete records is common in high-level languages such as Java and C++. SQL, however, does not have such a concept.
The relational algebra on which SQL is based defines a rich collection of set operations, but it has poor discreteness and does not support discrete records. Other high-level languages such as Java has high discreteness but gives poor support of set operations. SPL combines merits of SQL and Java to have both discreteness and set orientation. This means that it supports set data type and related computations, as well as discrete members that can operate autonomously or form a new set.
Discreteness and thorough set orientation are significant. Therefore, SPL’s theoretical basis is named “discrete data set”. It is important that a SPL beginner understand the two concepts well. Based on discreteness, SPL promotes the use of general sets and applies them in various computing scenarios including grouping, aggregation, order-based computations, joins and so on. We will explain them in the following section.
Lambda syntax
Same as SQL, SPL also offers Lambda syntax and extends it. Mastering Lambda syntax is essential to become proficient in using SPL.
For an ordinary function f(x), if parameter x is an expression, it will be first computed before function f is executed. For max(3+5,2+1), for instance, 3+5 and 2+1 are first computed and then max(8,3) is computed. If parameter x contains variables, like max(x+5,y+1), the function cannot be computed before x and y have been assigned values. After values are assigned to them, x+5 and y+1 are first computed, and their results are passed to the max function for further computation.
Yet, parameter expressions in some functions cannot be pre-computed, like that in A1.select(gender=="F"), which gets records of female employees in the above code. Expression gender=="F" cannot be computed before the select function begins to execute. This is because gender value can only be assigned during looping through members of set A1, and then the expression can be computed.
In this case the whole expression is taken as the parameter to pass to the select function for execution. This is equivalent to defining a temporary function as select function’s parameter. This type of coding is called Lambda syntax. And a function such as select is called loop functionin SPL. The essence of a loop function is using a function as the parameter.
SQL supports using an expression as a statement’s parameter, which achieves the basic Lambda syntax. For instance:
select * from employee where gender='F'
Expression gender='F' in WHERE condition isn’t computed before the statement begins to execute. Instead, it is computed on each record during traversal. This amounts to using a function defined through expression as the WHERE operation’s parameter.
SPL extends the Lambda syntax, making it applicable to any sets, and offers the special symbols to reference the current member, its ordinal number, and its neighboring members. This further simplifies the coding.
Here is an example. A set stores a company’s sale amounts from January to December, and we can perform the following computation based on it:
A |
|
1 |
=[820,459,636,639,873,839,139,334,242,145,603,932] |
2 |
=A1.select(#%2==0) |
3 |
=A1.(if(#>1,~-~[-1],0)) |
A2 performs filtering to get sale amounts of all even-numbered months. A3 calculates growth rate of sale amount in each month.
In the code, # represents the ordinal number of the current member during a loop operation; ~ represents the current member; and ~[-1] is the member previous to the current one. Generally, [-i] is the one i members before the current member, and [i] is the one i members after the current one.
Adata table is also a set. We can directly reference a member of this set using symbols ~, # and []. Suppose we have a monthly sale table storing a company’s sale amounts from January to December and each month’s overhead. We can perform the following computations based on it:
A |
|
1 |
=file("sales.btx").import@b(month,sales,costs) |
2 |
=A1.(~.sales-~.costs).min() |
3 |
=A1.(if(#>1,~.sales-~[-1].sales,0)).max() |
A2 calculates the minimum difference between the sale amount and the cost. A3 gets the maximum monthly sales increment.
In a data table, records are its members. A field of the current record is written as ~.sales, where ~ can be omitted in many cases. ~.sales-~[-1].sales, for instance, can be just written as sales-sales[-1].
Learn and find more about symbols ~,#and [] in SPL Programming - [Sequence As a Whole] Lambda Syntax.
The Java Stream and Kotlin supports Lambda syntax, too, but they do not offer specialized design for processing structured data. As a result, we need to take the current record as a parameter to pass to the function defined with Lambda syntax and should always write it explicitly when referencing a field of the current member. When we calculate the profit using sale amount and cost and if name of the parameter representing the current member is x, for instance, the expression, rather than involving field names only, should be “x.sales - x.costs”. Java also does not offer symbols ~,#, [] as SPL does.
Orderliness and position-based coding
The SPL data table is an ordered set. Its records are numbered in order starting from 1. The ordinal number of a record represents its position in an ordered set, which constitutes orderliness.
The orderliness lets us access a record in a certain position through its ordinal number, as well as computing the neighboring records. After storing price data of a certain stock according to transaction date, for instance, we can perform position-based computations using SPL code below:
A |
B |
|
1 |
=file("stock.btx").import@b(sdate,price) |
|
2 |
=A1(1) |
=A1.m(-1) |
3 |
=A1.pselect@1(sdate==date("2022-10-11")) |
|
4 |
=A1.m(A3-1) |
= A1.m(A3).price- A4.price |
5 |
=A1.derive(~.price-~[-1].price) |
|
A2 gets the first record, which is data of the first transaction date. B2 gets the last record, which is data of the latest transaction date. The m() function gets a member backwards when its parameter is a negative number.
A3 gets the ordinal number of the record of 2022-10-11. A4 gets the previous record according to A3’ ordinal number, which is data of the previous transaction date. B4 calculates the price increment on 2022-10-11 compared with the previous transaction date.
A5 calculates the price increment for each transaction date compared with the previous transaction date.
Based on ordered data and making use of ordinal numbers and with the help of symbols ~,# and [], the originally hard to express computation becomes simple and intuitive.
Order-based computations is a typical scenario that requires both discreteness and set orientation. The concept of order makes sense only in a set as a single value does not have order. This represents set orientation. On the other hand, an order-based computation involves a member and at least one neighboring member, which demands discreteness.
The relational algebra is based on unordered sets, whose members do not naturally have ordinal numbers, and does not offer position-based computing mechanism and neighboring member reference method. Though contemporary SQL is able to handle certain order-based computations thanks to local optimization in engineering in real-world applications, the common order-related scenarios remain a hard and complex issue, even with the help of window functions. Yet, SPL makes a big difference.
Orderliness is a unique SPL concept that SQL does not have, and an essential point beginners need to master. Making use of orderliness can simplify the traditional complicated computations and speed up computations that are originally slow. We will explain certain aspects of these in the following part, but you can also find more in RaqForum.
Understanding grouping & aggregation
Based on discreteness and thorough set orientation, SPL supports a set of sets. This enables the language to perform grouping operations in their essential forms – split a larger set into multiple subsets according to a certain rule and return a new set consisting of grouped subsets.
On many occasions, an aggregation on the subsets generated by a grouping operation is needed, such as calculating sum, average, the maximum value, etc. But a grouping operation may have other purposes. For instance, we want to find employees who have same birthdays. The simple solution is to group employees by birthday, get grouped subsets having more than one member and union these selected subsets. In such a case, we are more interested in grouped subsets themselves than the aggregate value (like member count in a grouped subset). In SPL, a grouping operation returns grouped subsets. This means that grouping and aggregation are divided and become two independent operations. So, it is easy to implement the solution to the above computing task in SPL. Below is the code:
A |
|
1 |
=file("employee.btx").import@b(name,dept,birthday) |
2 |
=A1.group(month(birthday),day(birthday)) |
3 |
=A2.select(~.len()>1) |
4 |
=A3.conj() |
A2:Group employee table, the large set, into multiple smaller sets, which are the grouped subsets. Having the support of discreteness, each grouped subset is made up of members of the original set (the employee table) rather than copies.
Generally, two people born on same date in the same month have same birthdays. So, the grouping condition here is the month and day in birthday field.
A3:Get grouped subsets that have more than one member. Those are employees having same birthdays.
A4:Union these selected grouped subsets.
On some occasions, we need to perform several types of aggregations on grouped subsets generated by same grouping criteria. As the SPL grouping operation obtains and retains grouped subsets, we can calculate different aggregate values on them, avoiding repeated grouping operations – even one grouping operation is costly – and increasing performance. To count employees in each department and calculate average salary in departments having greater than 10 employees, for instance, SPL has the following code:
A |
|
1 |
=file("employee.btx").import@b(dept,salary) |
2 |
=A1.group(dept) |
3 |
=A2.new(~.dept,~.len()) |
4 |
=A2.select(~.len()>=10).new(~.dept,~.avg(salary)) |
A2:Group employee table by dept and gets a result set of grouped subsets. Each grouped subset is a set of employees in one department.
A3:Get the department and count members in each grouped subset in loop. The symbol ~ represents the current row of A2’s grouping result, which is a grouped subset.
A4:Again, according to A2’s grouping result, we select grouped subsets whose members are equal to or greater than 10, and get department and calculate average salary in each subset.
SPL’s separation of grouping operation and subsequent aggregation makes it applicable in more scenarios, such as when some aggregate operations are hard-to-compute and we need to write another block of code based on the grouping result and when grouped subsets need to be further grouped.
Different from SPL, SQL does not have explicit set data type. As a result, it cannot return a result which is a set of sets, cannot achieve a separate grouping operation, and has no choice but to glue the grouping operation to the aggregation.
SPL treats all methods of splitting a larger set as grouping operations. Besides the regular equi-grouping, the language offersalignment groupingand enumerated groupingthat could get an incomplete partition result. You can find related essays in RaqForum.
After discreteness and set orientation, let’s move on to look at SPL orderliness that helps increase performance of grouping operations. Usually, a grouping operation is achieved through the HASH algorithm. If we know that data is already ordered by the grouping field, we can perform neighbor comparisons only. This avoids computing HASH values as well as hash collisions, and it makes easy parallel processing. For the above example, if we pre-sort the employee table by department, we can compare only the neighboring records and put those having same department in one group. We call this algorithm order-based grouping. The order-based grouping is much simpler and brings noticeable performance increase. Just need to make small changes on the original code:
A |
|
1 |
=file("employee.btx").import@b(dept,salary) |
2 |
=A1.group@o(dept) |
3 |
=A2.new(~.dept,~.len()) |
4 |
=A2.select(~.len()>=10).new(~.dept,~.avg(salary)) |
In A2, group() function works with @o option to group records through comparing only neighbors and combining those with same department.
SPL offers new understanding about aggregation operations, too. In SPL, apart from usual single value like SUM, COUNT, MAX and MIN, the aggregation result can also be a set, such as the commonly seen TOPN computations. SPL regards getting TOPN as an aggregation on either a whole set or a grouped subset, like SUM and COUNT. To find employees whose salaries are within the bottom TOP10 and get employees in each department whose salaries rank in TOP3 based on the employee table, SPL has the following code:
A |
|
1 |
=file("employee.btx").import@b(name,dept,salary) |
2 |
=A1.top(10;salary) |
3 |
=A1.groups(dept;top(-3;salary):top3) |
4 |
=A3.conj(top3) |
A2 gets records of employees who get a salary of bottom TOP10. A3 and A4 get from each department records of employees whose salaries rank in TOP3.
Relational algebra cannot treat TOPN computations as aggregation. It can only get TOPN from a whole set after the result set is sorted at output, and it is hard for it to get TOPN from a grouped subset without turning to a roundabout way that patches ordinal numbers to records. By treating TOPN as a type of aggregation, SPL can avoid sorting a whole data set in practice so that the computation can get high performance. A SQL TOPN, however, is always accompanied with ORDER BY operation, which requires whole set sorting in theory. The only chance of improvement is the optimization in engineering implementation of database.
Cursor
To process big data, SPL provides cursor. A SPL cursor’s basic functionality is similar to that of a database cursor. Both read data in order. Different from a database cursor, a SPL cursor reads data from a file and reads a batch of data each time. To calculate total amount, count orders and calculate average amount based on orders table, for instance, SPL reads data from the table cursor in loop using the following code:
A |
B |
C |
|
1 |
=0 |
=file("orders.ctx").open().cursor(amount) |
=0 |
2 |
for B1,10000 |
>A1+=A2.len() |
|
3 |
>C1+=A2.sum(amount) |
||
4 |
=C1/A1 |
In addition to the basic function of reading data in loop, SPL cursor has richer uses than SQL cursor. SPL defines a wealth of cursor functions and allows attaching various operations to a cursor. For orders whose amounts are above 5000, to calculate the total amount of and their number, SPL has code below:
A |
|
1 |
=file("orders.ctx").open().cursor(amount) |
2 |
=A1.select(amount>5000) |
3 |
=A2.groups(;sum(amount):S,count(amount):C) |
4 |
=A3.S/A3.C |
A2 and A3 attach two steps of computation respectively – perform filtering to get orders whose amounts are above 5000 and sum the amounts and count the number.
Cursor-based computations are external storage computations, which are essentially unlike in-memory computations. Yet, as we can see from this example, SPL cursor functions are designed like in-memory functions, making easy learning and convenient programming.
As a beginner, you need to make special note that A2’s select()function in the above code does not truly perform the filtering action to get orders whose amounts are above 5000 but only defines the operation on the cursor. SPL will execute the pre-defined select action when groups() function in the next step begins to traverse data. SPL reads a batch of records each time, filters and summarizes them, and then reads the next batch.
We call the cursor select() function returns delayed cursor, which is truly executed when data is fetched. The groups() function triggers traversal action on cursor instantly and does not return a cursor. Such an operation is called instant computation. It is important that you know whether a cursor function is a delayed cursor or not according to its return value.
The benefit of a delayed cursor is that there isn’t an intermediate result. In this example, if the filtering operation returns a result, it is probable that the result cannot fit into the memory and needs to be written to hard disk for retrieval in the next step. Hard disk read/write is very slow and the performance is much lower than a delayed cursor brings.
Another difference from the database cursor is that the SPL cursor can be a multicursor, which is easy to parallelly process and supports multi-purpose traversalthat enables to calculate multiple types of aggregate values during one cursor traversal. SPL also offers program cursorspecifically for handling complex computations and the scale-out cluster cursor. You can find more and detailed explanations about them in RaqForum.
Understanding association
SQL defines JOIN as Cartesian product of two sets (tables)andthen a filtering on it according to a certain condition. The oversimple definition cannot reflect the characteristics of all types of JOINs, making it hard to code or optimize relatively complicated scenarios.
In real-world applications, most JOIN operations are equi-joins where the join condition is an equation. SPL further divides equi-joins into three types – foreign key association, homo-dimension table associationand primary-sub table association. Programmers can choose the most suitable methods to handle different association tasks. The classification reflects characteristics of different associations and enable using specialized approaches according to these characteristics. As a result, syntax becomes simple, and performance is improved.
In a foreign key association, a table’s non-primary-key field is associated with the primary key of another table. The former is called fact table and the latter is dimension table. In the following figure, for instance, orders table is the fact table, and customer table, product table and employee table are all dimension tables.
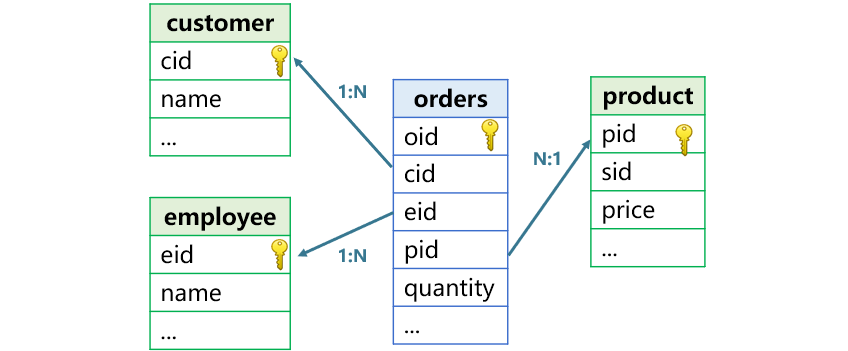
For such an association task, SPL offers a natural and intuitive method – foreign key value – address conversion. According to this method, we associate orders table and employee table and filter orders data by employee name and order date using the following code:
A |
B |
|
1 |
=file("employee.btx").import@b().keys@i(eid) |
=file("orders.btx").import@b() |
2 |
>B1.switch(eid,A1:eid) |
|
3 |
=B1.select(eid.name=="Tom" && odate=…) |
|
In A2, orders table’s eid field is converted to corresponding record of employee table, that is the foreign key value- address conversion. The A3 can use eid.name to reference the record’s name field. The dot operator (.) means an address reference.
In a homo-dimension table association, two tables are associated through their primary keys. Employee table and manager table are homo-dimension tables (as shown below), where the former’s primary key eid is associated with the latter’s primary key mid. Certain employees are managers and both eid and mid are employee ids. A homo-dimension table association is a one-to-one relationship.
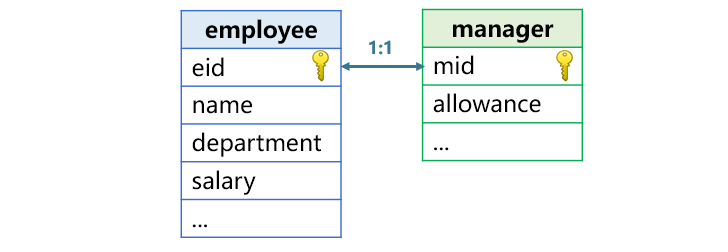
SPL uses join()function to perform the homo-dimension table association. For instance, to get each employee’s (including managers) id, name and income (salary and allowance), SPL has the code below:
A |
B |
|
1 |
=file("employee.btx").import@b().keys(eid) |
=file("manager.btx").import@b().keys(mid) |
2 |
=join@1(A1:e,eid;B1:m,mid) |
|
3 |
=A2.new(e.eid:eid,e.name:name,e.salary+m.allowance:income) |
|
In a primary-sub table association, a table’s primary key is associated with a part of the other table’s primary key. In the following two tables, orders table’s primary key is oid (order id) and order_detail table’s primary key is a composite one consisting of oid (order id) and pid (product id). The orders table’s primary key oid is associated with the order_detail table’s oid field, which is a part of the primary key. The former is the primary table, and the latter is the sub table. They have the relationship of one-to-many.
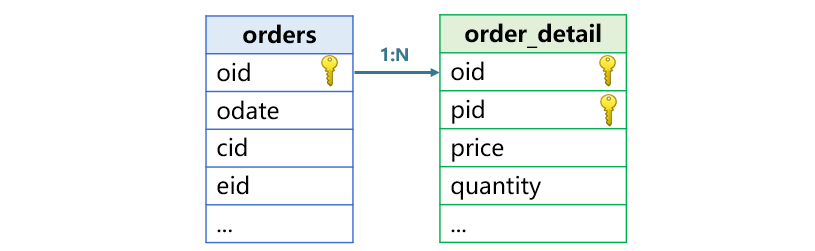
SPL also uses join() function to handle such as case. To calculate each customer’s total order amount, for instance, the SPL code is as follows:
A |
B |
|
1 |
=file("orders.btx").import@b() |
=file("order_detail.btx").import@b() |
2 |
=join(A1:o,oid;B1:od,oid) |
|
3 |
=A2.groups(o.cid:cid;sum(od.price*od.quantity)) |
|
Unlike homo-dimension table association, oid is only part of the order_detail table’s primary key. There could be multiple matching records having same oid. In the result returned from join() function, an orders record will appear repeatedly because each order_detail record has one matching orders record while each orders record has multiple order_detail records. The number of records in the result set is the same as the record count in order_detail table.
SQL handles all scenarios of JOIN operations in a general way, while SPL deals with them according to their own ways using different functions. SPL also uses different approaches, even including different storage schemes, to optimize performance for different JOIN scenarios involving huge volumes of data. It is important that SPL beginners master the innovative concepts SPL gives to association operations. When handling an association operation, you know what type of join it is and choose an appropriate way to accomplish it. There are a lot of related articles in RaqForum.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version