

The significance of open computing ability from the perspective of SPL
Relational database provides SQL, so it has strong computing ability. Unfortunately, however, this ability is closed, which means that the data to be calculated and processed by database must be loaded into database in advance, and whether the data is inside or outside the database is very clear. On the contrary, the open computing ability means that the data of multiple sources can be processed directly without having to load them into database.
Database has metadata, you need to define tables before using them. Since the data can only be loaded into database after they are organized to meet the constraints, closeness of computing ability is natural. Conversely, what kind of computing is open? It is an ability that is very flexible, and can calculate the data directly without the need to organize in advance, and there is no any constraints or restrictions.
Currently there are many such open data computing engines, Spark is one of the relatively famous ones. However, compared with Spark, esProc SPL is better as SPL is lighter in technology, simpler in coding and higher in computing performance.
In addition to concise syntax and high computing performance, SPL has strong open computing ability, for example, SPL can calculate the data of multiple sources directly, and can also do mixed computing.
Then, which is more advantageous, open or closed computing ability? Since SPL and SQL are often compared, let's look at the difference between them from the perspective of openness, as well as the significance of openness to construction cost of data application system.
Solve direct computation on diverse data source
Diverse data sources are very common in the informatization of modern enterprise. In addition to the most common RDB, there are also other data sources like NoSQL, CSV/Excel, WebService. Data analysis, as a comprehensive mean, its data may come from multiple sources. To do data analysis, it definitely involves cross-source data calculation.
SQL (database) performs poorly in implementing cross-source calculation. For example, DBLink, as the representative of cross-database query solutions, is not only very unstable and inefficient, but can only work based on database. As a result, multiple data sources are often organized before computation in practice, that is, the data of other sources are imported into the same database through ETL before computation, thus avoiding cross-source computation. However, this way causes some problems, mainly reflected in three aspects.
The first is the real-time of data. If the available data needs to be loaded into database through ETL, two processes are required: data organizing and loading. Both processes need time, and the latter is very slow. The time consumed in the latter process will inevitably lead to poor real-time of data. In addition to the time cost, the extra processes will increase the development cost, after all, the works need to be done manually.
The second is the storage cost. Storing multiple-source data into one database will occupy valuable database space, and hence it will increase storage cost and capacity-expansion pressure. In fact, many data do not need to be stored into database persistently, especially some temporary queries. However, the “closeness” of database requires computing following the storing, otherwise it won’t work.
The third is that it cannot make use of the advantages of diverse data sources themselves. As we know, the reason why there are diverse data sources is that each type of data has its unique advantage and plays a different role in different application scenarios. For example, RDB is stronger in computing ability but lower in IO efficiency, so it undertakes more computing tasks; Oppositely, NoSQL is high in IO efficiency, and can adopt multiple/multi-layer dynamic structures, it is very flexible in this regard, yet its computing ability is often weak; As for files like Text/JSON, they do not have computing ability at all, but they are more flexible in use and management, and easier to implement parallel computing to improve performance. If all data are imported into RDB, their respective advantage cannot be exploited, resulting in an increase in application cost, and it also needs to spend more cost to make up for hardware loss caused by the same database.
Now let's look at SPL.
Compared to SQL, SPL is more open, and supports multiple data sources. You can calculate such data directly in SPL. More importantly, SPL has the ability to join different data sources to do mixed computing.

Since SPL supports mixed computing of diverse data sources, the development and time costs caused by the loading process mentioned above can be saved. In addition, the real-time computing of multiple data sources can fully ensure the real-time of data, and it is no longer a problem to implement T+0 query after dividing data into different databases. Moreover, since the data are no longer loaded into databases thoughtlessly, the storage cost of database is greatly reduced, and the capacity-expansion pressure is relieved.
SPL also has the ability to fully retain respective advantage of various data sources. Specifically, RDB is stronger in computing ability, you can make RDB do part of calculations first and then let SPL do the rest calculations in many scenarios; NoSQL and file are high in IO transfer efficiency, you can read and calculate them directly in SPL; MongoDB supports multi-layer data storage, you can let SPL use it directly. Such ability significantly saves manpower as well as hardware and software costs.
For more information: visit: Which Tool Is Ideal for Diverse Source Mixed Computations
Avoid the drawback of stored procedure
When solving complex computations with SQL, stored procedure is a common technology. By proceduring SQL in stored procedure, and implementing complex computation in a step-by-step manner, very complex computing scenarios can be handled. However, the stored procedure has obvious disadvantages: i) it cannot be migrated. Different databases support stored procedure at different degree, which makes it almost impossible to migrate stored procedure and harder to extend; ii)it is difficult to develop and debug stored procedure, and the development cost is high; iii) sharing a stored procedure by multiple applications will cause tight coupling between applications, resulting in an increase in application cost; iv) there exist management and security problems. The flat structure of database cannot manage stored procedures like tree-structure of file system. Once there are more stored procedures, the management will be in chaos, and management problem will occur. The creation and modification of stored procedures require higher privilege on database, this will bring potential security risk and increase overall operating cost. Many companies have now explicitly banned stored procedures, which shows that the disadvantages of stored procedures are indeed intolerable.
So how to solve these problems? Aftera moment's thought you will find that the reason for using stored procedure is to take advantage of the computing ability of database. Although SQL is not good in many aspects, it is much simpler and efficient than other high-level languages like Java, therefore, relying on database is inevitable. If outside-database computing can obtain same effect, for sure we can discard stored procedures. Moving stored procedure out of database and implementing an “outside-database stored procedure” in SPL can solve these problems.
SPL provides an open computing ability that does not depend on database, and the change of database does not require modifying SPL computational scripts, the migrating problem of stored procedure is therefore solved; SPL’s concise and easy-to-use IDE environment has complete editing and debugging functions, making it easier to implement algorithms; the “outside-database stored procedure” does not rely on database and can be stored with application, the coupling problem is thus solved; the management problem is solved by adopting the tree structure of file system; SPL runs independently of the database, and hence security risk is avoided.
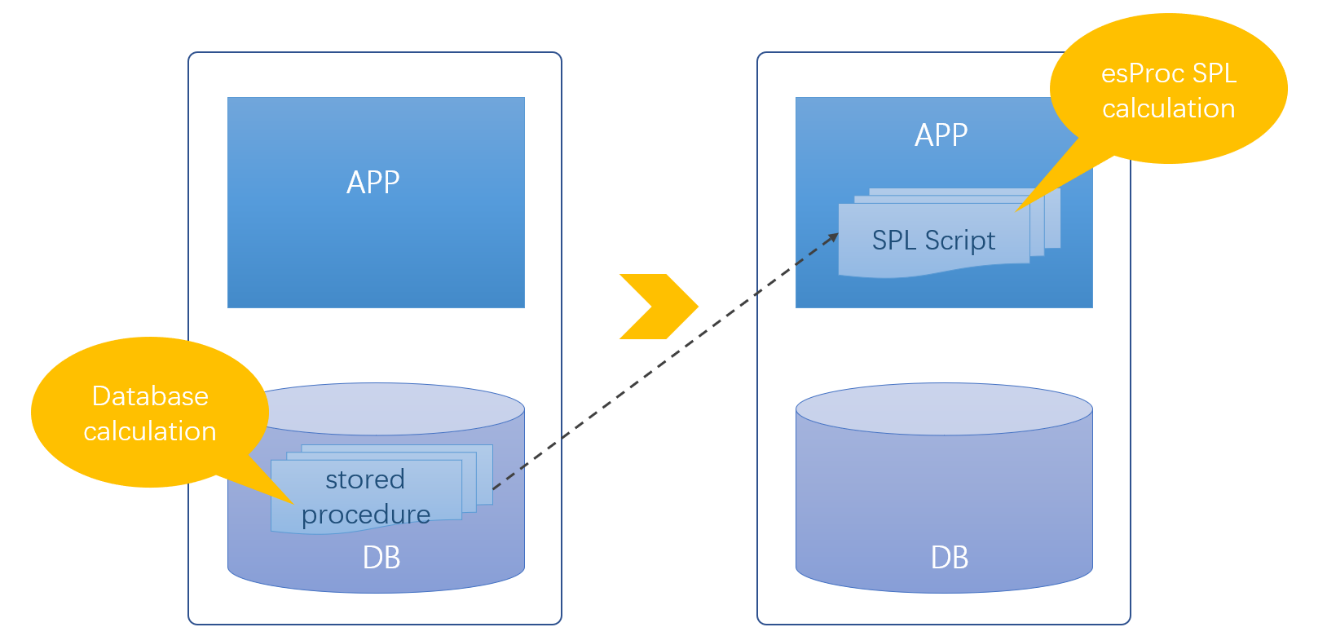
Therefore, even if we put aside the problems of stored procedures like difficult to code and poor performance (visit: Is SPL more difficult or easier than SQL? for reference), SPL can bring many benefits from the perspective of openness alone.
For more information: visit: Goodbye, Stored Procedures - the Love/Hate Thing
Eliminate intermediate tables, reduce unnecessary databases
Usually, the intermediate tables of database are the intermediate result generated for the convenience of subsequent calculations. Since these results are stored in database in the form of table, they are called intermediate tables. Some complex calculations cannot be accomplished in one step, the intermediate results will be stored as intermediate tables before proceeding. Sometimes, in order to improve query performance, the query result will be pre-processed into intermediate table, and this phenomenon also occurs in above-mentioned process that loads diverse data sources into databases. Once the intermediate table is created, it is often difficult to delete because you don’t know whether this table is being used by other applications. As a result, more and more tables are accumulated, sometimes as many as tens of thousands. Too many intermediate tables will cause capacity and performance problems.
Space is needed for storing intermediate tables, and occupying too much database space will cause an increase in storage cost and put pressure on capacity expansion; Too many intermediate tables will make management become difficult and increase management cost; Both the generation and maintenance of intermediate tables need to be done on regular basis. Even if the intermediate tables expire, you often have to retain them because the coupling relationship is not known. These useless tables will still consume database’s computing resources, resulting in exhaustion of database resources, decrease in performance and increase in hardware cost.
In fact, the reason why intermediate tables are stored in database is still to exploit the computing ability of database (SQL), as intermediate tables need to be used (computed) in subsequent calculations. If storing as files, it can only be hard-coded (in Java), which is much more complicated than SQL. Therefore, intermediate tables rely heavily on databases and SQL.
In contrast, SPL has enough open computing ability, and can calculate directly based on files. With this ability, intermediate tables can be moved out of database and stored externally, and the intermediate tables problems can be solved in subsequent calculations with the aid of SPL.

With the support of SPL’s outside-database calculation ability, various problems originally caused by intermediate tables are solved. To be specific, file storage no longer occupies database’s storage space, reducing the capacity-expansion pressure of database, and making it more convenient to manage database; the outside-database calculation no longer occupies database’s computing resources, and the saved resources can better serve other businesses; Storing files externally and computing in SPL reduce the cost. Furthermore, the high-performance private file storage scheme that SPL provides significantly improves computing performance and reduces hardware cost.
For more information, visit: Open-source SPL Eliminates Tens of Thousands of Intermediate Tables from Databases
Implement hot and cold data layering through data routing
Sometimes, in order to timely meet the data request of front-end application, a front-end database will be installed close to the application end, and then moving common data into this database to compute can better serve the application, and reduce the pressure of the central data warehouse, that’s killing two birds with one stone.
However, when we take traditional database as front-end database, some problems occur. Because what is stored in front-end database is a small amount of hot data, the application requirement of querying full data cannot be satisfied. If all data is moved from data warehouse to front-end database, not only is the workload huge, but it involves repeated construction, leading to high cost; If only part of data is moved, it needs to limit the data query range at the application end due to the lack of routing function (unable to identify data location) and cross-database query ability, which is very cumbersome.
Fortunately, SPL has the cross-source (cross-database) computing ability and supports data routing, you can take SPL as a frond-end database to solve these problems.
In practice, we divide the data into three layers: hot data, warm data and cold data. Since the hot data is used at very high frequency, we can load it into memory through SPL so that they can be accessed and calculated at high speed; Warm data used at high frequency could be stored as high-performance file format that SPL provides, so that the files can be read directly when querying; The large amount of cold data used at very low frequency is still stored in the central data warehouse. In this way, SPL can route the data processing tasks to corresponding data location based on front-end query request (SPL provides corresponding SQL parsing and conversion functions), that is, the hot and warm data are calculated in SPL, and the cold data is calculated in the central data warehouse, and finally SPL merges the calculation results and returns them to application end. Since most calculations (high-frequency data) are performed in SPL, and only a small number of queries are transferred to the central data warehouse, not only the original data query range problem is solved, but it effectively reduces the pressure of the central data warehouse and achieves a better front-end query experience.

For more information: visit: Which Is the Best Technique for Separating Cold Data from Hot Data?
Solve HTAP requirements
For HTAP (Hybrid Transaction and Analytical Process), we hope to meet AP and TP requirements through one database, and fundamentally, we hope to be able to handle the full-data query, namely T+0 query on the basis of meeting TP requirements. However, since there are significant differences between AP and TP, it inevitably needs to employ different technologies to implement the two requirements.
Currently there are two ways to implement HTAP based on database system. One is to adopt multiple copies, and different copies are stored in different methods (columnar storage or row-based storage) to meet different TP and AP requirements. The other is to separate TP and AP scenarios at the base layer, and encapsulate respectively with mature technology of TP and AP fields, while designing a unified external access interface.
No matter which way is adopted, we will face the following problems.
High migration risk, high cost. If the original business database is not a HTAP database (high probability), then it will involve database migration, which will face high risk and high cost.
Unable to obtain the advantage of diverse data sources. Modern business system involves many types of data sources, it is not easy to migrate all data into a new database, and it cannot take advantage of the respective advantages of diverse data sources. This is consistent with the problems of diverse data sources we discussed earlier.
Fail to meet performance expectations. To implement high performance, columnar storage alone is not enough. For some complex computations, it needs to design specialized data storage methods (such as ordered storage, data type conversion, pre-calculation) according to computing characteristics. The performance often fails to meet the expectation by simply “automatic” row-to-column converting.
In fact, we can introduce SPL based on the original independent TP and AP systems to implement HTAP with the aid of SPL’s open cross-source computing ability, high-performance storage and computing abilities and agile development ability.
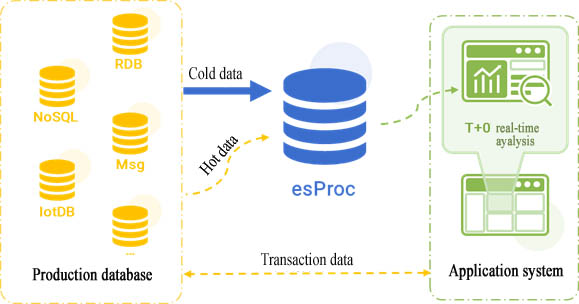
SPL implements HTAP in a way that combines with the existing system. In this way, it only needs to make a few modifications to original system, there is almost no need to modify TP data source, and even original AP data source can continue to be used to make SPL to gradually take over AP business. Having partially or completely taken over AP business, the historical cold data is stored in SPL’s high-performance file, and original ETL process that moves the data from business database to data warehouse can be directly migrated to SPL. When the cold data is large in amount, and no longer changes, storing them in SPL’s high-performance file can obtain higher computing performance; when the amount of hot data is small, storing them still in original TP data source enables SPL to read and calculate directly. Since the amount of hot data is not large, querying directly based on TP data source will not have much impact, and the access time will not be too long. After that, by making use of SPL’s cold and hot data mixed computing ability, we can achieve T+0 real-time query for full data. The only thing we need to do is to periodically store cold data in SPL's high-performance file, and keep the small amount of recently generated hot data in original data source. In this way, not only is HTAP implemented, but it implements a high-performance HTAP, and there is little impact on the application architecture.
For more information: visit: HTAP database cannot handle HTAP requirements
Gradually improved Lakehouse
Data lake and data warehouse relate to each other very closely but what they focus are different. The former focuses more on the retention and storage of raw data, while the latter pays more attention on computing. Therefore, a natural idea is to integrate them to achieve the goal of “Lakehouse”.
At present, the common integration method is to providethe privileges for data warehouse to access the data of data lake. In practice, it needs to create an external table/schema in data warehouse to map RDB’s table or schema, or hive’s metastore. This process differs little from the implementation method that a traditional database (like DBLink) accesses external data, and the disadvantages are very obvious. This is also caused by database's closeness that the data can only be loaded into database for calculation after being organized to meet the constraints, and the organizing process will lead to the loss of a lot of raw data and data lake value. Therefore, constraints, closed system and inflexibility are the main problems that data lake technology is facing.
If the database is open enough, and has the ability to directly calculate the unorganized data of data lake, and even the ability to perform mixed computing based on many types of data sources while providing high-performance mechanism to ensure the computing efficiency, then it is easy to implement Lakehouse.
This goal can be implemented in SPL.
SPL has the ability to directly calculate the raw data of data lake without constraints, and there is no need to load data into database. Moreover, SPL has the mixed computing ability for diverse data sources. Whether the data lake is built based on a unified file system or diverse data sources (RDB, NoSQL, LocalFile, Webservice), a direct mixed computing can be done in SPL to quickly output the value of data lake. Furthermore, the high-performance file storage (the storage function of data warehouse) that SPL provides can be utilized to allow data to be organized unhurriedly when calculations are going on in SPL, while loading the raw data into SPL’s storage can obtain higher performance. The data are still stored in file system after they are organized in SPL storage, and theoretically, they can be stored in the same place with data lake. In this way, a real Lakehouse is implemented.
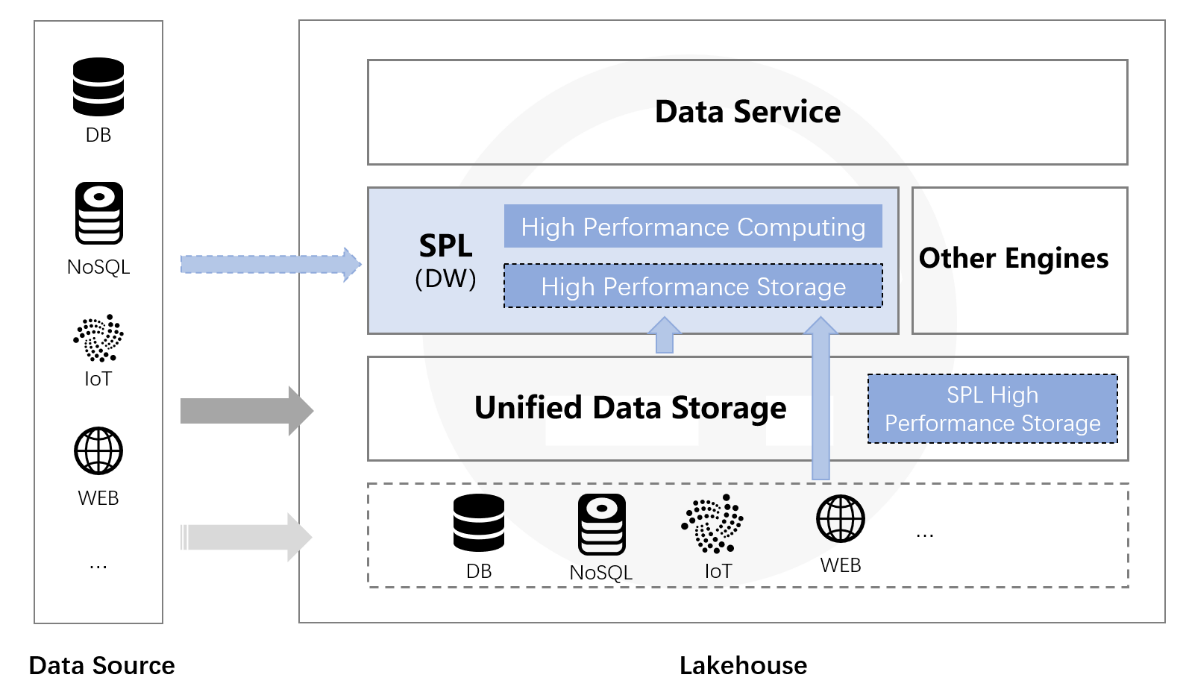
With the support of SPL, the organization and computation of data can be carried out at the same time, and the data lake is built in a stepwise and orderly manner. Moreover, the data warehouse is perfected in the process of building the data lake, making data lake has strong computing ability, and implementing a real Lakehouse.
For more information: visit: The current Lakehouse is like a false proposition
On the whole, SPL that has open computing ability is more flexible, more efficient, lower in application cost and more advantageous, compared to the closed SQL (database).
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_SPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL

