

Scudata SPL Cloud
Data computing on the cloud can help enterprises reduce costs and increase efficiency, and a common approach is to use cloud data warehouses. Currently, almost all cloud data warehouses have evolved from traditional data warehouses. At the beginning of the birth of data warehouses, there was no consideration of going to the cloud. Cloud data warehouses will face many problems such as storage and computing separation, elastic expansion, serverless, and openness. Although some engineering methods can be used to achieve some functions in disguised form, it still cannot fundamentally solve the problems.
Scudata SPL Cloud (SSC) provides another option. SSC is a cloud computing service specifically designed for (semi) structured data, with features such as high performance, low code, versatility, and openness. It supports features such as storage and computing separation, elastic expansion, and serverless.
SSC can completely replace the functionality of cloud data warehouses, but it itself is not a traditional cloud data warehouse. The core of SSC is computing and does not provide data management or metadata content to describe data. SSC only provides users with convenient, flexible, and efficient cloud computing services after putting computing on the cloud. This design can bring many benefits:
Essentially, the storage of SSC is built on file system, and SSC only designs a more efficient file format. Whether the files are stored in a network system or in cloud object storage does not make any difference. With this feature, storage and computation separation can be naturally supported, instead of bypassing the file system and directly accessing the hard disk like in a data warehouse. To achieve storage and computation separation, it is very difficult to refactor from the bottom layer (with extremely high complexity).
Without a closed storage system like a data warehouse, SSC is more flexible and open when used, with files that can accommodate data of any structure. In the meanwhile, SSC can also access various cloud data sources, and data can be calculated without the need for “loading into database”. Regardless of storage (data is not private), data can be calculated anywhere, which is the openness of SSC performance.
SSC does not store or have metadata, which can avoid the time cost of loading metadata. Computing nodes can be quickly started or shut down as needed, which is more conducive to implementing elastic computing. In the meanwhile, without the constraints of metadata, SSC naturally supports multi-tenant and serverless, without the user isolation and maintenance of user related state environment caused by metadata, making it more concise and efficient overall.
The characteristics and advantages of SSC will be explained in detail below.
SSC involves multiple components and concepts, so let’s take a look first.
QDB: Full name QDBase, it is the core of SSC, responsible for data processing and providing services.
QVM: Full name QDBase Virtual Machine, it is a computing resource of SSC that is bound to cloud virtual machines and dynamically created or destroyed according to request requirements. Each QVM comes with a QDB service program for processing computing tasks.
QVA: Full name QDBase Virtual Allocator, the allocation system of QVM. Each QVA manages a batch of virtual machines, responds to task requests, assigns virtual machines, and starts QVM.
QVS: Full name QDBase Virtual Service, a service program deployed by users to accept and process computing requests. QVS can run on the user’s own machine (which can be a cloud virtual machine) in embedded or server mode, and is configured with user cloud object storage information.
SPL, also known as Structured Process Language, is a formal language for QDB, oriented for structured and semi structured data.
There are two application modes of SSC, which can directly use public cloud services or be deployed privately on public clouds.
Application Mode
Public Cloud
SSC currently supports three cloud providers: AWS, GCP, and Azure.
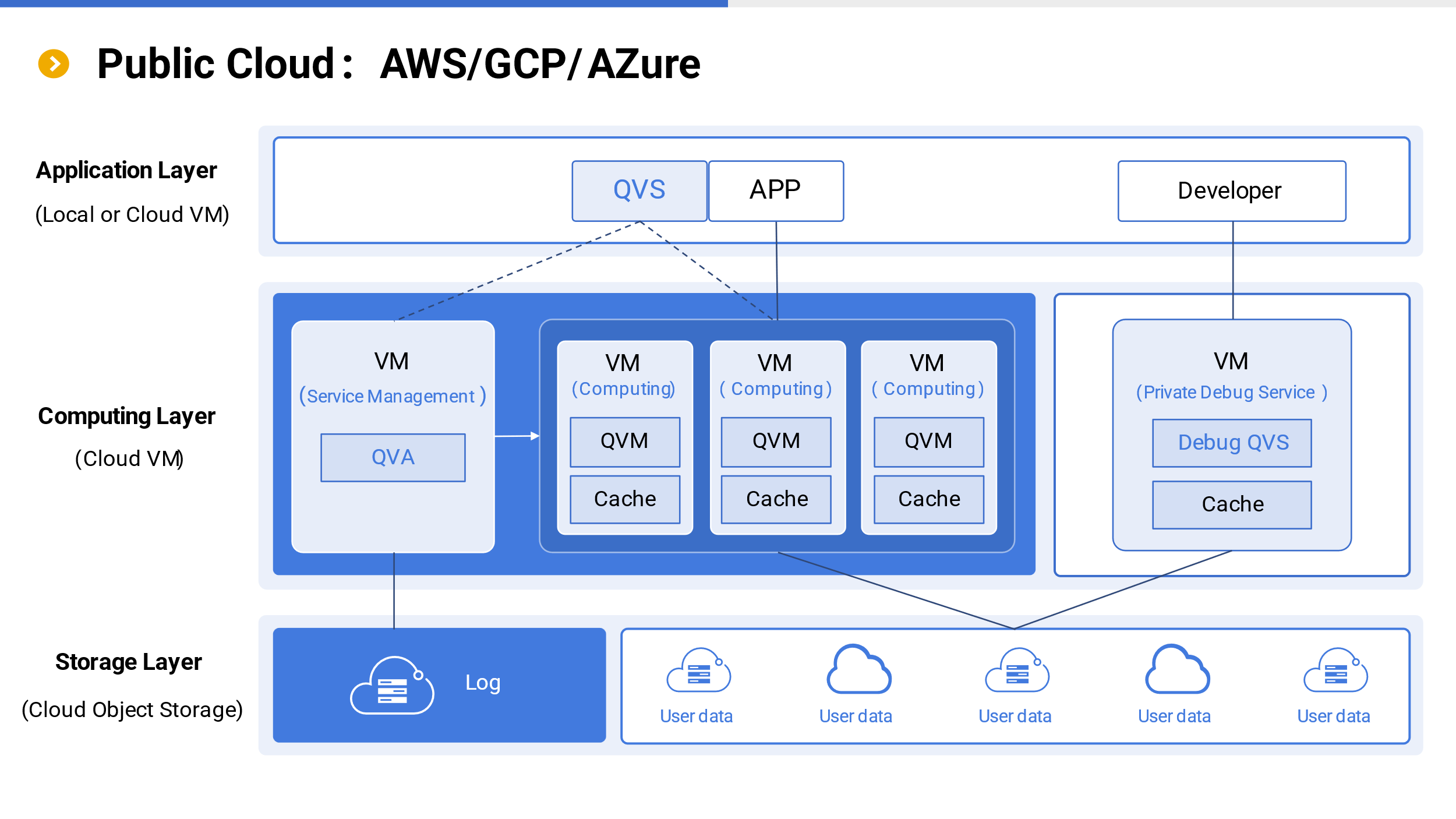
From the architecture diagram, it can be seen that the application structure of SSC consists of storage layer, computing layer, and application layer.
The storage layer is divided into two parts, both using cloud-based object storage. The blue part on the left belongs to SSC, which is the root storage of public clouds, used to store system information such as user logs. It is transparent to users and users do not need to care when using SSC. In fact, the storage belonging to SSC is just that.
We know that the storage and computing of cloud data warehouses are integrated, and data needs to be moved in before it can be used (for computing). But SSC is different. SSC does not provide data storage, and user data is still where it was originally stored (with cloud object storage). Simply give the access interface to SSC. Data does not need to be uploaded to SSC, and SSC does not own user data, let alone manage storage. The benefits of doing so are more flexible usage, lower costs, and natural support for multi-tenant and more security. User self-management of data is a very important feature of SSC, which is completely different from the architecture of cloud data warehouses.
The computing layer runs as a whole on cloud virtual machines, mainly running QVA and QVM services. The QVA on the left is the management service for the entire SSC, which runs permanently and is mainly used for system operation and maintenance management, user management, and allocation/recycling of QVM resources.
The middle part of the computing layer is the virtual machines used for actual computing. QVA dynamically creates a QVM (starts the virtual machine) based on user requests for computing, and then recycles computing resources (destroys the virtual machine) after task completion. QVM will cache the hot data used by users locally on the virtual machine for high-performance computing.
The right part of the computing layer is the QVS service for development and debugging. Similar to storing user data on their own cloud, QVS for debugging services is also deployed on the user’s own virtual machine, either on the cloud or locally. The debugging process does not consume SSC resources (without incurring fees) and is private to users, hence it is called private debugging.
The application layer includes development, user applications (APPs), and built-in QVS for applications. If the APP has a computing requirement, it needs to apply for QVM from QVA through its built-in QVS, and directly connect to QVM to achieve the computing task. There is no need to transfer through other services, and QVM reads storage layer user data (or cache) for calculation. The built-in QVS can be an independent server or embedded with an application. The APP and its built-in QVS can be installed locally or on virtual machines purchased by users themselves.
Users can directly develop and debug scripts based on the private debugging service QVS, and support local script upload and remote script download.
From the perspective of the entire architecture, the biggest difference between SSC (blue part) and other cloud products is that user data and debugging are both private to users. SSC does not own user data and will not increase user costs due to debugging. In addition, the greater advantages of SSC lie in development efficiency and computational performance. High development efficiency can effectively reduce development costs, while high performance can lower hardware costs.
Private deployment on public cloud
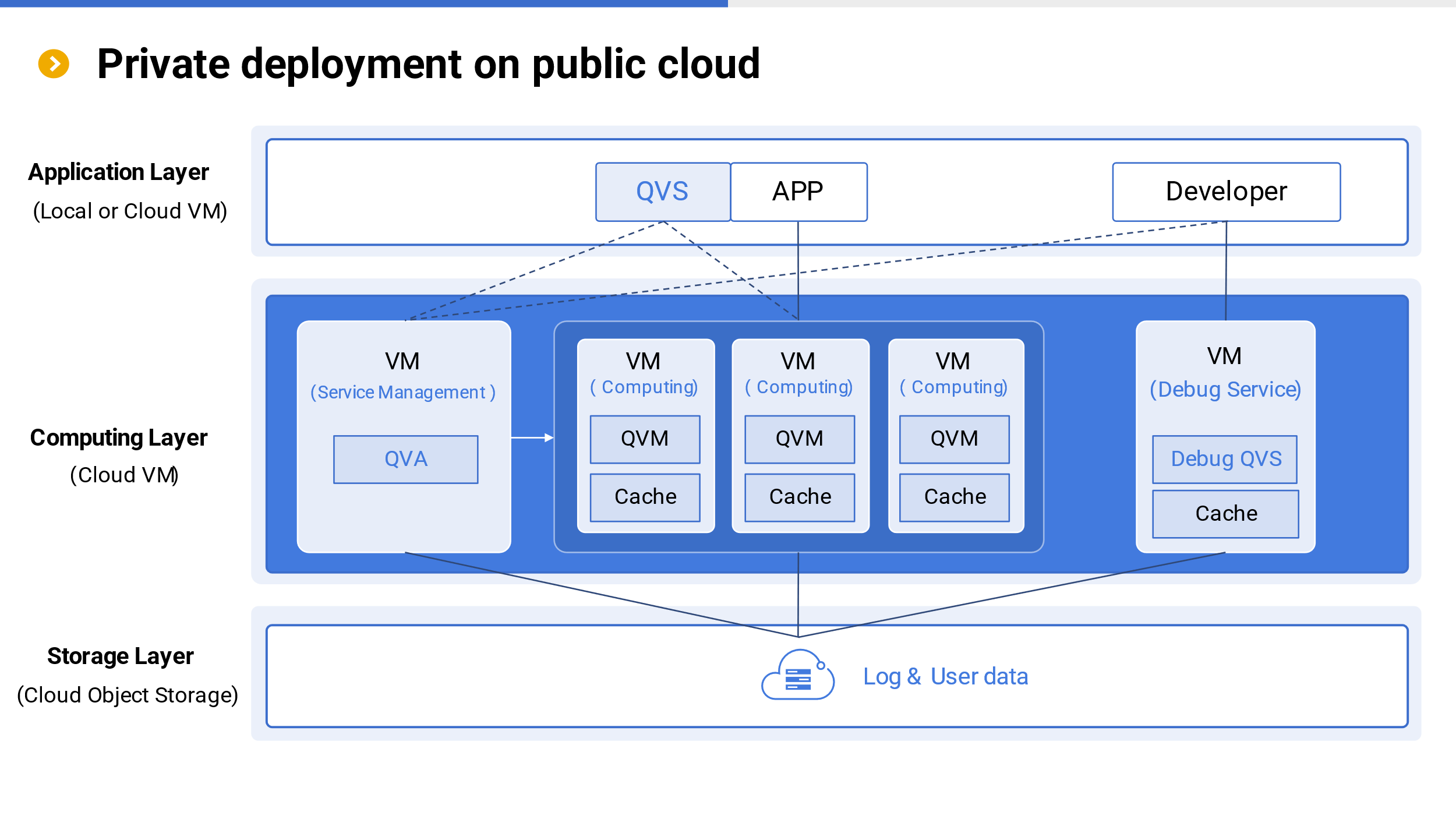
SSC can be deployed as cloud software by users on public clouds. The structure of private deployment is similar to that of public cloud, with the only difference being that it is entirely user private. System logs and user data can be directly stored on public cloud object storage.
The two usage modes can be selected according to actual needs and are relatively flexible.
SSC characteristics
Separation of storage and computation
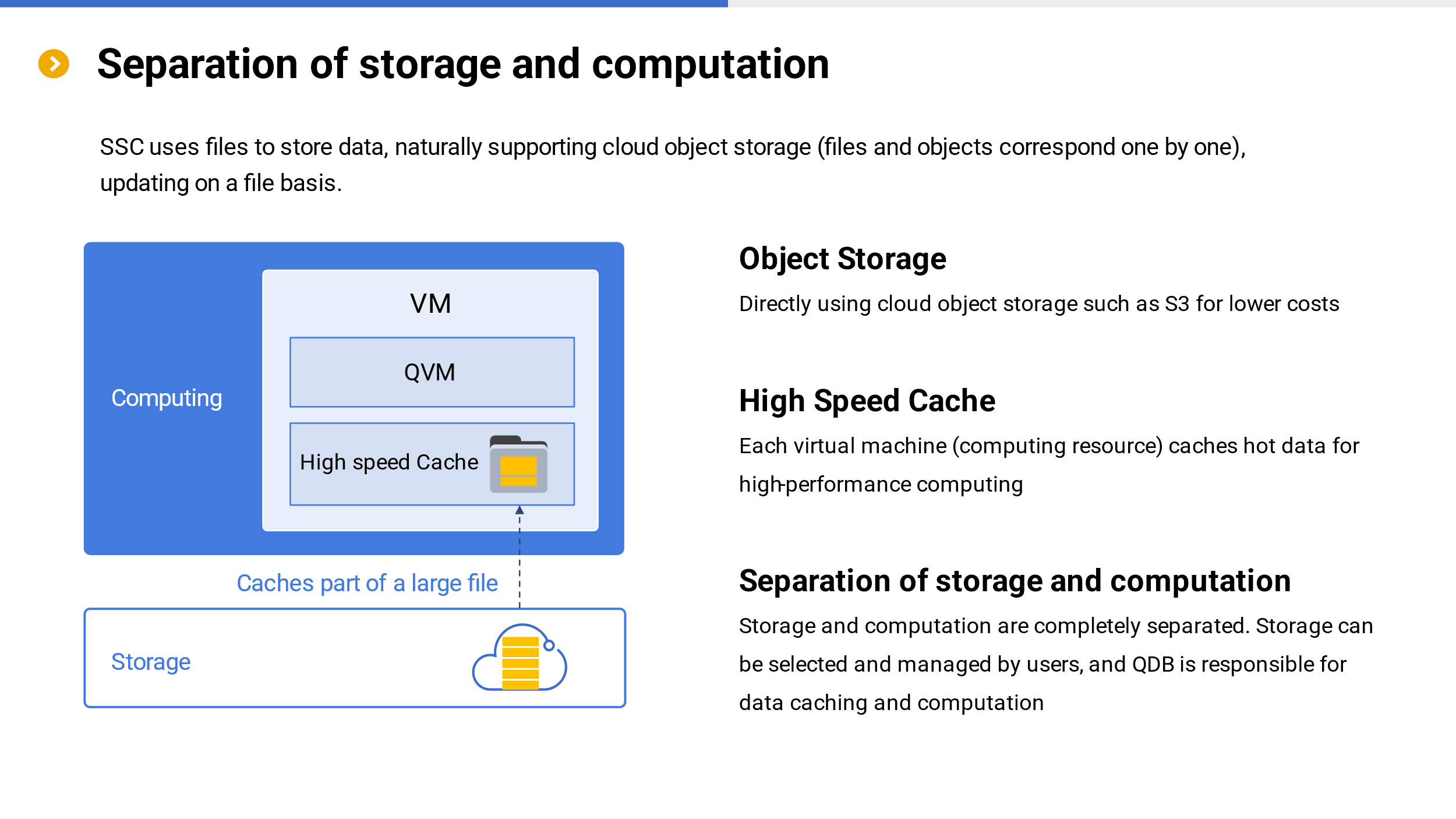
From the architecture, it can be clearly seen that SSC supports the separation of storage and computation. The data is stored in cloud object storage and managed by users themselves, while the computation is carried out by the QVM of SSC on the cloud. The cost of object storage (such as S3) is very low, while SSC defaults to using files to store data, which correspond one-to-one with object storage and can perfectly achieve mutual conversion.
SSC also provides caching on the QVM for local high-performance computing. Caching is determined in real-time by the data used for specific tasks, and only the used data (hot data) are cached. Once the data is cached, it will be stored on the hard disk of the virtual machine where the QVM is located, and will not become invalid until the hard disk is full (first in, first out), which is conducive to cache reuse.
Elastic expansion
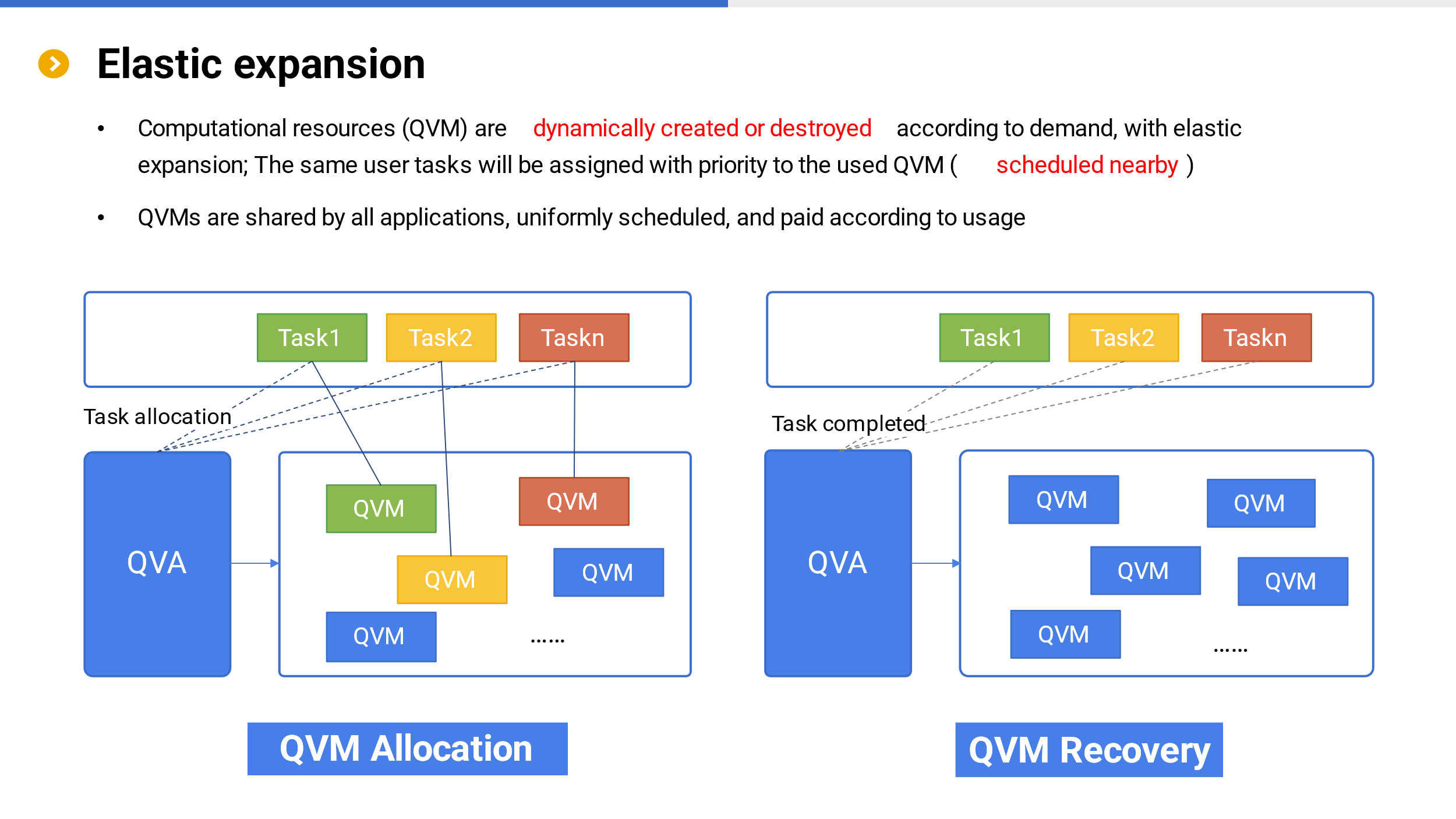
With storage and computing separation support, users can expand storage or computing resources separately as needed. It goes without saying that cloud storage is managed by users themselves. The computation is dynamically created or destroyed by QVA based on requirements, and automatically expands elastically.
Based on the aforementioned caching mechanism, QVA adopts a nearby scheduling strategy when assigning tasks, assigning tasks to historically used and idle virtual machines. Reusing cache not only has high computational efficiency, but also reduces usage costs by eliminating the need to cache data.
Lightweight Serverless
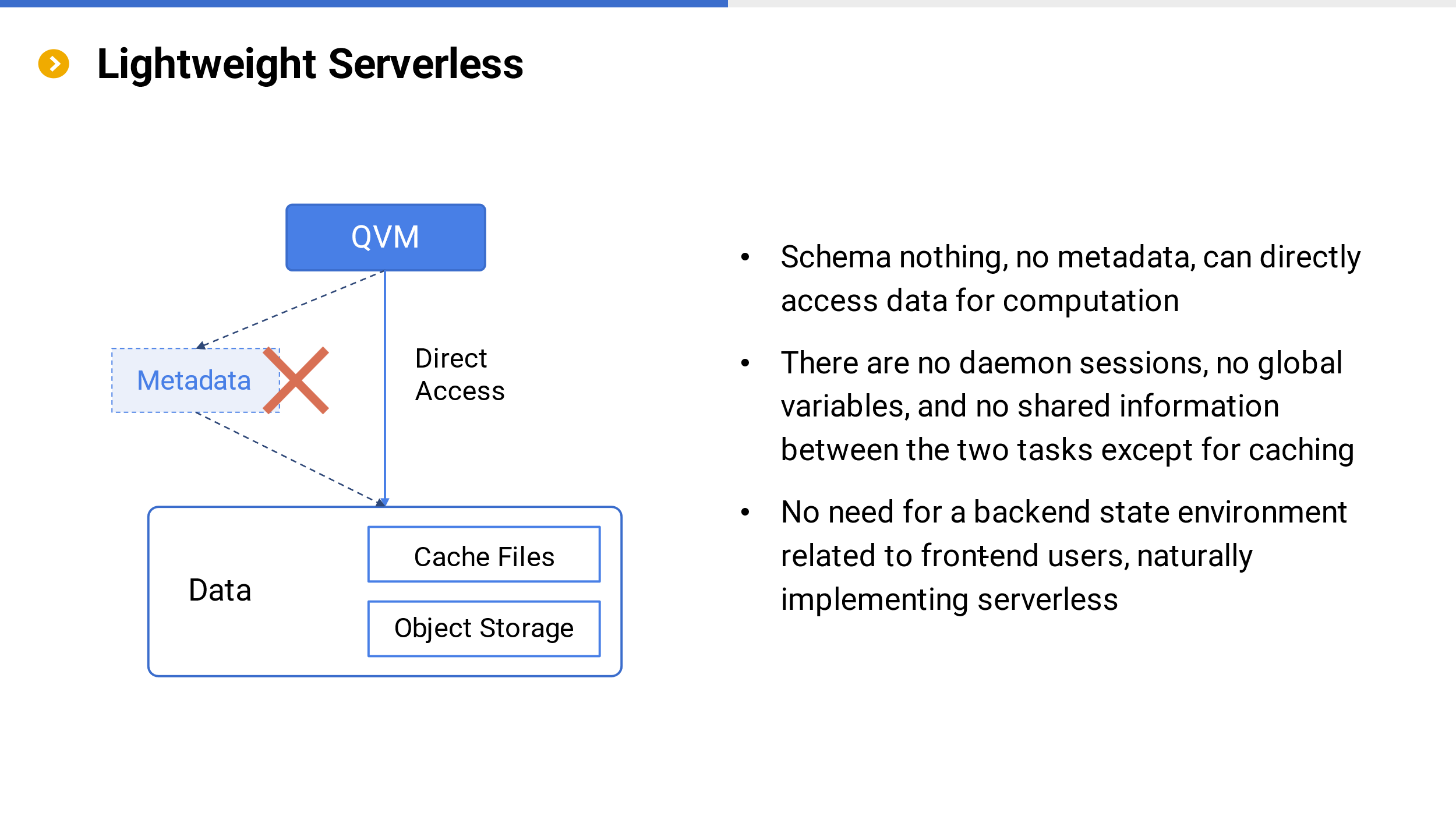
There is no concept of metadata in the SSC system (schema-nothing), which not only allows applications to directly interact with QVM for computation, but also eliminates the need to load metadata when QVM reads data (there is no metadata at all), resulting in more efficient computing efficiency and more open computing power.
We know that the SQL system (Cloud data warehouse) requires metadata, and only by loading metadata can calculations be performed. If metadata is stored on management services (as is the case in most cases), managing services can easily become a bottleneck when multiple tasks are concurrent. In the meantime, it is necessary to consider the scalability of management services. The overall architecture is not only more complex, but also has high operating costs and low computational efficiency. On the other hand, the distribution of metadata in computing services may result in limited elastic scalability due to personalization, and loading metadata may cause slow startup of computing virtual machines, which also affects efficiency.
A system without metadata will be lighter, and the backend does not need to maintain a state environment related to front-end users, naturally implementing serverless.
User Managed Data
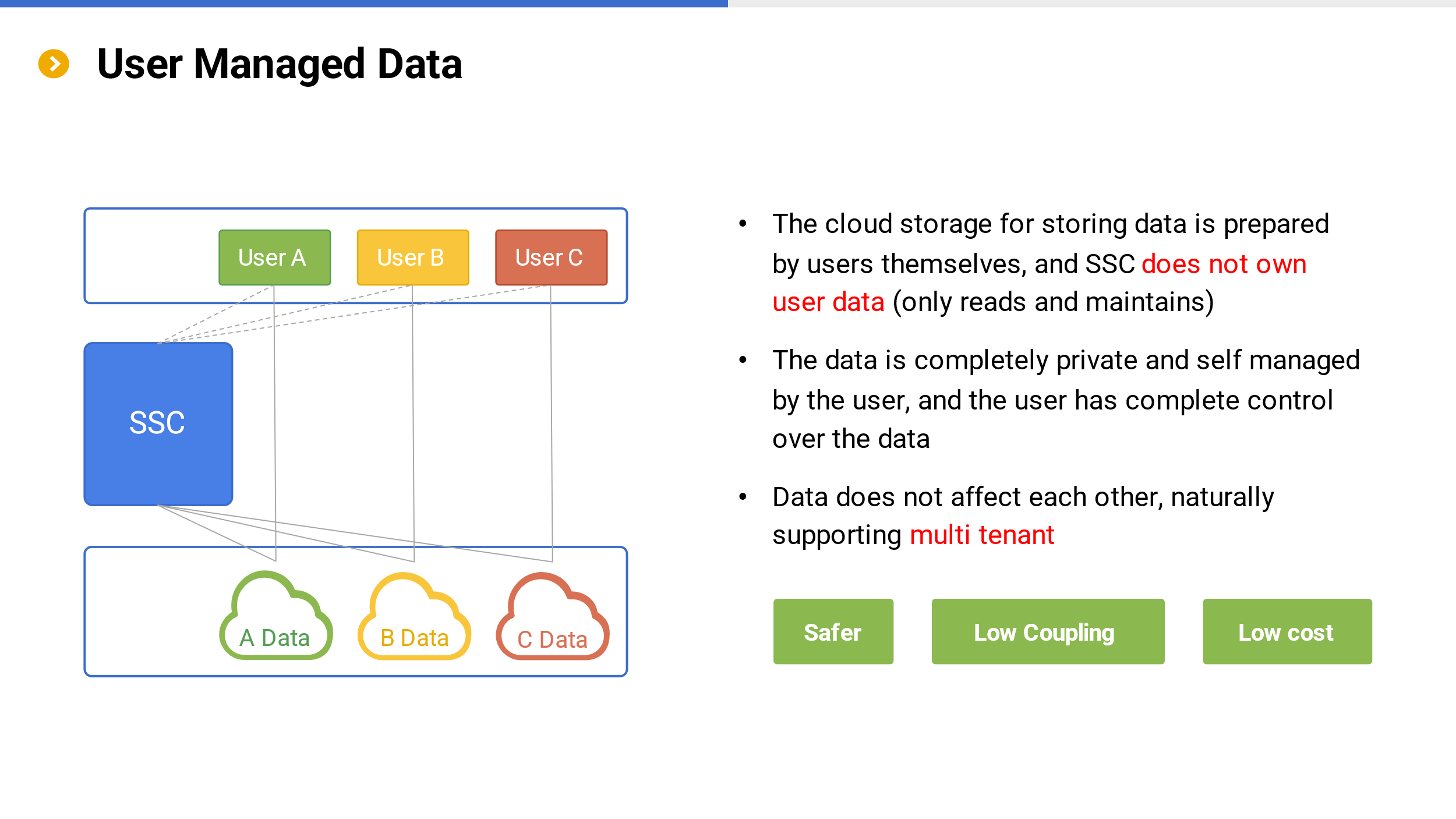
The SSC system does not include user data, and the cloud storage for storing user data is prepared and managed by users themselves. Data does not need to be uploaded to SSC, and SSC does not own user data. It only needs to give corresponding access method to SSC to access.
Managing data by users can bring the following benefits:
Data remains the user’s private asset, with complete management and usage control, making it more secure;
Private user data also brings about natural data isolation between users, thus naturally achieving multi tenancy, as the main difficulty in implementing multi tenancy lies in data isolation. Private user data naturally solves this problem.
Private debug
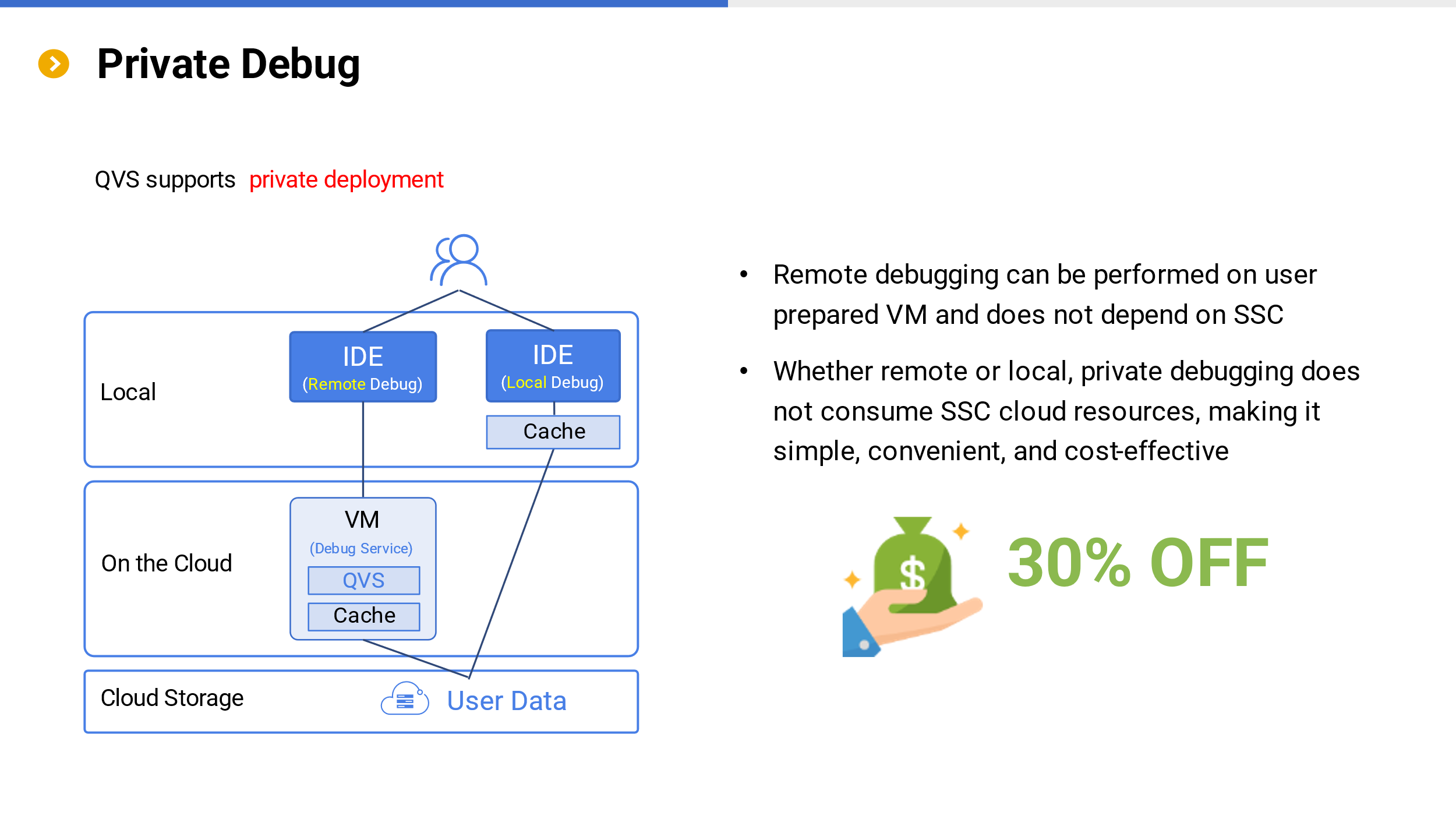
In cloud computing, the cost of debugging programs often accounts for more than 1/3 of the total cost. The reason is that during the debugging process, computing resources are consumed and corresponding data transmission occurs, and cloud data warehouses cannot distinguish whether these computing resources are used for debugging or production, and they will be charged equally. For complex and data intensive computations, debugging costs are significant, and this cost composition is significantly different from the previous development model before cloud deployment. Obviously, due to the heaviness brought about by the closeness of cloud data warehouse, unified management center, metadata, etc., this drawback cannot be avoided.
SSC has adopted a private debugging mode to address this issue. When debugging, users do not consume the storage and computing resources of SSC, and fully utilize users’ own resources, thus effectively reducing usage costs.
Private debugging comes in two ways.
One is remote debugging through the connection between the local IDE and the QVS service deployed on the cloud. This way, data can flow on the cloud without incurring additional traffic costs, while also providing better security.
Another option is to consider development and debugging efficiency while allowing data to be cached locally to a certain extent (local debugging efficiency is definitely higher compared to remote debugging), therefore, development and debugging can be carried out through the IDE directly based on cloud storage, however there may be some traffic costs (depending on the rules of the cloud service provider).
Regardless of the method used, the application cost of SSC in debugging will be lower, and only debugging can save about 30% of the cost.
Openness
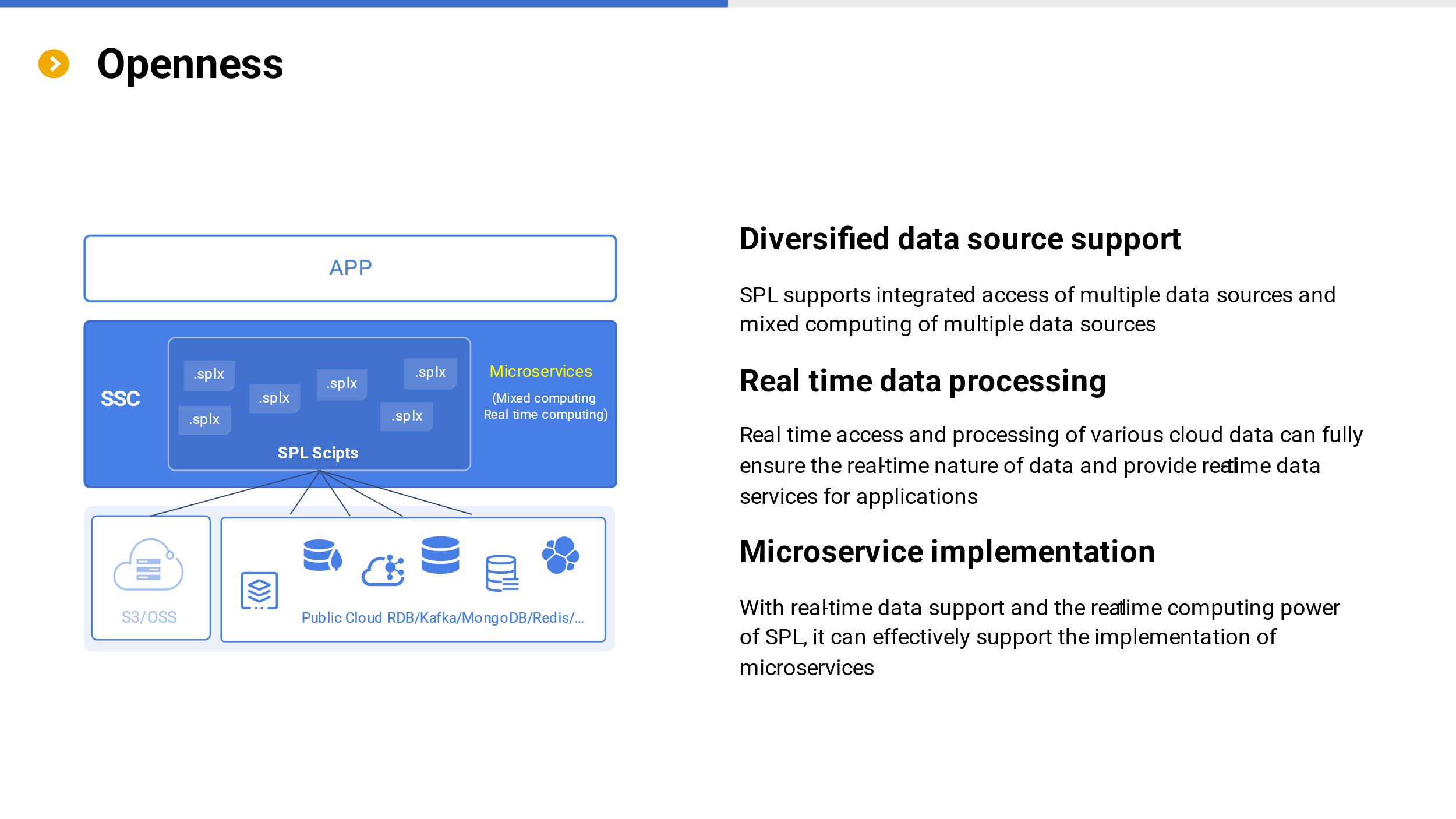
SSC can not only read pre prepared object storage during application, but also can connect to other diverse data sources on the cloud (such as RDB, Kafka, MongoDB, Redis, Elasticsearch, RESTful, etc.) for computation, especially for mixed computation between multiple data sources.
Real time computing based on multiple data sources can fully utilize real-time data and provide real-time data services for applications. With this ability, it can effectively support the implementation of microservices.
High performance low code

In addition to its architectural advantages, the biggest advantage of SSC lies in the low code and high computational performance of SPL. SPL adopts a completely different discrete dataset theory model from SQL, which improves many problems of relational algebra in set operations (such as order utilization, discreteness, etc.), provides procedural calculation support, and built-in richer structured data computing types (table sequence) and operations (ordered calculations, etc.), making it easier to implement complex calculations.
Not only is the code simple, but the computational efficiency of SPL is also higher. In a large number of practical cases, the computational efficiency of SPL often exceeds SQL by several to hundreds of times. High performance means lower hardware costs.
For low code and high performance, please refer to another material specifically introducing SPL: esProc SPL, a data analysis engine reducing application cost by N times (raqsoft.com)
Versatility

In addition to low code and high performance, SPL also features full functionality. Nowadays, almost all cloud data warehouses are still based on the SQL system, and SQL is not easy to implement some complex calculations. For example, calculating user churn rate in e-commerce funnel analysis using SQL is almost impossible, so it is necessary to write UDF or implement it using Java/Python and other technologies. The application method of SQL+other technologies is still feasible within the enterprise, but not on the cloud. The cloud environment will not open up these personalized programming technologies, and everyone can only use SQL with no choice. However, SQL capabilities are limited, and users seem to be trapped in a dead cycle.
SPL’s capabilities are more comprehensive and can be seen as a combination of SQL and other technologies. It’s natural to implement what SQL can do, and what SQL is not easy to do can also be implemented. Using SPL for funnel analysis not only results in shorter and more versatile code, but also higher execution efficiency.
Comprehensive functionality will make the technology stack simpler, resulting in lower operation and maintenance costs.
External interfaces
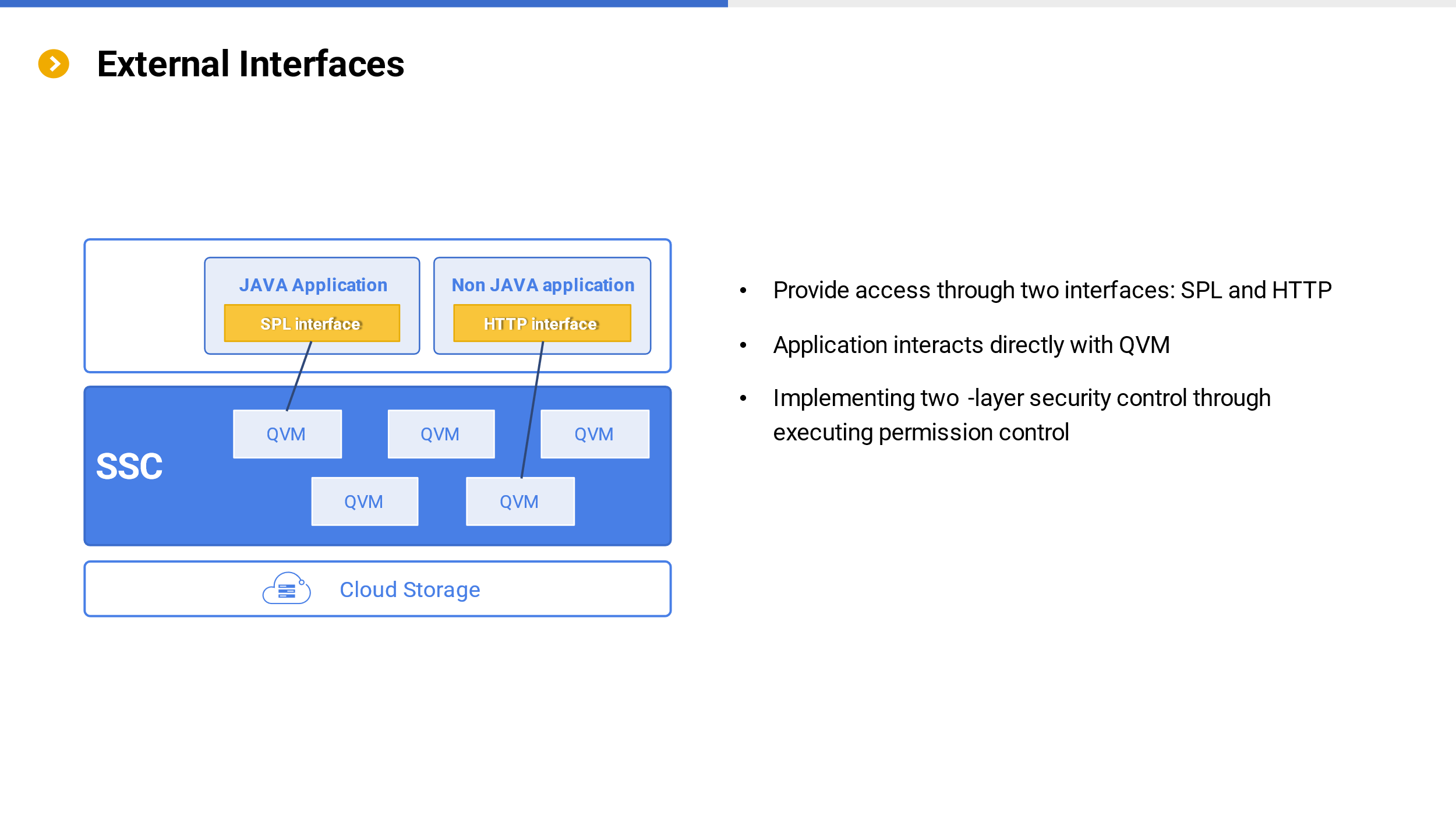
In terms of integration with applications, SSC provides two application interfaces. For Java applications, SPL can be directly integrated into the application and interact with SSC using SPL. For non Java applications, an HTTP interface can be used to connect to SSC.
Regardless of the interface used, the application is directly connected to QVM (computing service).
When interacting with SSC, the application only grants execution permissions, without the authority to modify or delete computing scripts, achieving two-layer security control.
Overall, the goal of SSC cloud computing is to bring more value to users, such as low cost, high performance, openness, flexibility, and comprehensive functionality. These goals can be well achieved through SSC’s architectural advantages and engine capabilities.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version