

Column-wise computing of SPL
In-memory column-wise computing
What is columnar storage
The table sequence in memory generally adopts the row-based storage. For example, the employee table contains three fields ‘id, name and birthday’, which are stored in memory roughly as follows:

Each row (i.e., each record) is stored as an Object array, including three member objects: [Integer,String,Date].
In general, each column (field) contains the same type of data. Under this premise, SPL can store data by column. For example, if the data in the id column are all integers, they can be stored as an int array; if the data in the name column are all strings, they can be stored as string array ‘String[]’; if the data in the birthday column are all date, they can be stored as date array ‘Date[]’. The storage result is shown as below:
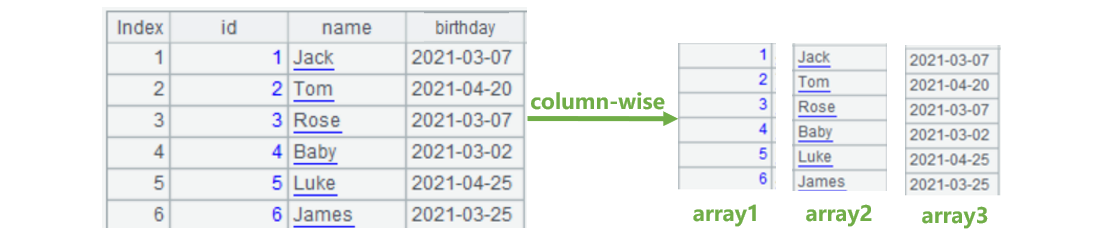
This storage method of SPL is called columnar storage. To implement columnar storage, it is necessary to ensure that all records of any field of table sequence are the same in type. Such field is called the pure field, and the table sequence that requires all fields to be the pure field is called the pure table sequence. If a pure table sequence adopts columnar storage, it is also called the columnar table.
Correspondingly, the sequence that requires its members to be the same in type is called pure sequence.
The SPL code of converting an employee table sequence that meets the above conditions to a pure table sequence is roughly as follows:
| A | B | |
|---|---|---|
| 1 | =file("employee.btx").import@b() | =ifpure(A1) |
| 2 | =A1.i() | =ifpure(A2) |
| 3 | =A2.o() | =ifpure(A3) |
A1: read the file data into memory to generate an ordinary table sequence; B1: judge whether A1 is a pure table sequence and return false;
A2: use the i() function to convert the ordinary table sequence A1 to a pure table sequence. If a certain field in A1 is not the pure field, an error will be reported, such table sequence is called impure table sequence;
B2: judge whether A2 is a pure table sequence and return true.
A3: use the o() function to convert the pure table sequence A2 to ordinary table sequence. B3: judge whether A3 is a pure table sequence and return false.
Note that if a pure table sequence becomes impure due to the change of its field, an error will be reported.
What is column-wise computing
Ordinary table sequence is calculated row by row. For example, it is required to provide the uppercase name and age of employees, the ordinary table sequence is roughly calculated as follows:

First calculate the uppercase name and age of the employee in the first row, then calculate those of the employee in the second row, and do the same for the rest.
Unlike row-wise computing, SPL can perform column-by-column calculation on pure table sequence, which is roughly as follows:
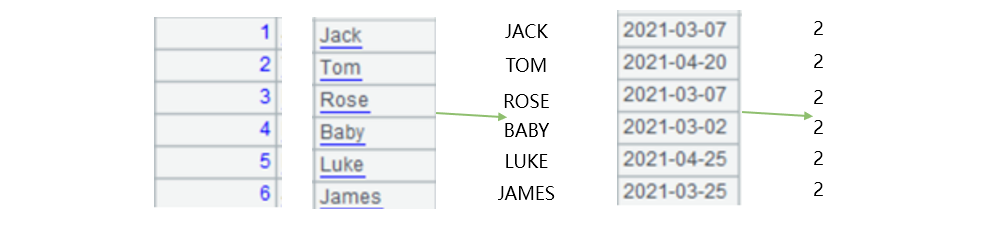
First calculate all the values in the name column to get all uppercase names, and then calculate the birthday column to get all ages. Such method that calculates based on column is called column-wise computing.
The code of column-wise computing is roughly as follows:
| A | B | |
|---|---|---|
| 1 | =file("employee.btx").import@b() | |
| 2 | =A1.i() | =A2.derive@o(upper(name):NAME,age(birthday):ages) |
Performance advantages of column-wise computing
SPL is developed in Java and is sensitive to memory.
Ordinary table sequence adopts the row-based storage; each record in memory is an object array, and each field value is an object in the array.
In contrast, pure table sequence adopts the columnar storage, and each column is an array. Since the number of columns is often much less than that of rows, columnar storage can reduce the number of objects generated.
If the field values are all simple data types, such as int, long, double and boolean, there is no need to generate object in the case of columnar storage. For the row-based storage, however, the generation of object is a must even if the field values are simple data type.
Compared to row-based storage, columnar storage generates fewer objects, which can reduce memory usage and save the object generation time. Moreover, column-wise computing will calculate one column at a time and can reuse a lot of context information, hereby making its overall performance more advantageous.
Column-wise computing and string, date types
Strings and dates are not simple data types, and hence there is still a need to generate object even in columnar storage. In order to improve performance, we need to find a method to convert them to simple data type.
For string, we should try to adopt the sequence-numberization method and convert it to numerical data. For example, the product type field of product table contains the string data, we can create an independent foreign key table first, and then convert the string to the sequence number of foreign key table.
As for date or time type data, we should try to store them as int. SPL provides the days@o function, which can implement such conversion. We can also use the date@o function to convert int back to date or time if needed.
Column-wise computing and new, derive, and run functions
When using the new and derive functions on table sequence, the computing result is a copy of the original table sequence. For pure table sequence, it is recommended to use new@o and derive@o, which can add column directly on the original table. For columnar storage, the computing cost of adding an extra column is very low, which is exactly the opposite of row-wise computing. In row-wise computing, adding one more column will result in the regeneration of all rows, which is very inefficient.
In column-wise computing, it is not recommended to use the run function because using this function during computation will assign value to the original field of pure table sequence, leading to a situation that the calculation is forcibly changed to row-wise computing.
Column-wise computing and switch, join functions
The switch function is to switch the field value to a record (reference address), which is an object rather than a simple variable. Therefore, it is not recommended to use switch function in column-wise computing. For example, the following code is not suitable for column-wise computing:
| A | |
|---|---|
| 1 | =ORDERS.switch(O_CUSTKEY,CUSTOMER:C_CUSTKEY) |
The join function can join the field of association table onto the current table, and hence this function is more suitable for column-wise computing. The above code should be modified as:
| A | |
|---|---|
| 1 | =ORDERS.join(O_CUSTKEY,CUSTOMER:C_CUSTKEY,NAME:CNAME) |
Column-wise computing and temporary variable
It is not recommended to use temporary variable in column-wise computing. For example, the pure table sequence T contains three integer fields f1, f2, and f3, and now we want to calculate the difference between the square of f1 and f2, and the sum of the square of f1 and f3.
The following code uses temporary variable, which is not suitable for column-wise computing:
| A | |
|---|---|
| 1 | =T.new(t=f1*f1,t-f2:r1,t+f3:r2) |
In column-wise computing, simple data type has no object, and one integer is a member of integer array, not an Integer object.
Since the temporary variable ‘t’ must be stored as an object, it cannot form an integer array, resulting in a failure to participate in column-wise computing. So, the above code should be modified as:
| A | |
|---|---|
| 1 | =T.new(f1*f1:t,t-f2:r1,t+f3:r2) |
This code adds a column t, which can avoid using temporary variable. The computing cost of adding one column in column-wise computing is very low.
Functions related to column-wise computing
Using the new, derive, and groups functions on a pure table sequence will still return a pure table sequence. By contrast, after using the conj(), select(), sort(), group(), align(), and j() functions for calculation, it needs to add @v to return a pure table sequence.
When using T.import() to read the data from composite table, we can add @v to generate pure table sequence.
When using T.memory() to read the data from composite table or composite table cursor to generate an in-memory table, we can also add @v to generate the in-memory table of pure table sequence.
Columnar cursor
What is columnar cursor
Cursor is to read the data of database or file in batches into memory for calculation. For the database cursor or composite table cursor, SPL can read data into memory in batches to form a pure table sequence for columnar storage and column-wise computing. Such cursor is called columnar cursor.
Taking the employee composite table and the employee table in database as an example, the code of columnar cursor is roughly as follows:
| A | |
|---|---|
| 1 | =file("employees.ctx").open().cursor@v(id,name;manager=="Tom") |
| 2 | =connect("db").cursor@v("select id,name from employees where manager='Tom'") |
When using columnar cursor for calculation, if the generated table sequence is impure, an error will be reported.
To solve this, we can use the create@v function when generating composite table. In this way, SPL will compare whether the columns are pure during data maintenance, and will also save the data type suitable for use as columnar cursor. The code is:
| A | |
|---|---|
| 1 | =file("employees.ctx").create@v(#id,name,address,manager,…) |
Performance advantages of columnar cursor
Due to the fact that using columnar cursor for calculation will read data into memory in batches to generate a pure table sequence, it has the advantages of low memory usage and high computing performance.
How to use columnar cursor
In a composite table which is used for columnar cursor, we should adopt simple data types as much as possible, such as int, long, double, and boolean, which is more conducive to column-wise computing, reduces memory usage, and improves performance. Moreover, we should try to convert the string type data to sequence number, and convert the date and time type data to int or long.
If the new and run functions are used to assign value to the original field when computing a pure table sequence, the calculation will be forcibly changed to row-wise computing. Therefore, when using columnar cursor, we should not assign value to the original field, nor do we use temporary variable.
When using a columnar cursor for foreign key association calculation, it is not recommended to use the switch function, and instead the join function is recommended.
Functions related to columnar cursor
When the columnar cursor uses the group function, adding the @v option will copy each grouped subset to a new pure table sequence. It should be noted that the group@v of table sequence or cursor does not necessarily run faster than group, and hence choosing which function to use in practice needs to be determined through actual test.
The calculation result of the select function with the @v option is still a columnar cursor. The cs.new or cs.derive function with the @o option is also to add field to original pure table sequence, and will not copy the entire pure table sequence.
Columnar cursor and parallel computing
Like ordinary cursors, the columnar cursor of composite table also supports parallel computing, we only need to add the @mv option and parallel number parameters.
When multiple columnar cursors are merged in parallel, attention should also be paid to synchronous segmentation. Take the orderly merging of an order table and an online product table as an example, the code is roughly as follows:
| A | |
|---|---|
| 1 | =file("ORDERS.ctx").open().cursor@mv(O_ORDERKEY,O_ORDERDATE;;4) |
| 2 | =file("LINEITEM.ctx").open().cursor@v( L_ORDERKEY,L_PRICE,L_QUANTITY;;A1) |
| 3 | =A3.joinx@im(L_ORDERKEY,A2:O_ORDERKEY,O_ORDERDATE) |
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version