

Data maintenance routine
Overview
Composite table is an important file storage format of SPL. To ensure high performance, composite table often requires data to be stored in order. However, the order in which the data are generated is usually different from the order required by composite table, so it needs to adjust the order of data when maintaining composite table data. In addition, the composite table cannot be read when writing data to it, yet some query computation tasks cannot be stopped during data maintenance, which also needs to be ensured using corresponding means.
This routine will give solutions to these problems.
Related terms:
Single composite table: data is stored in one composite table file.
Multi-zone composite table: data is stored in multiple ‘zone tables’ (hereinafter referred to as ‘table’ unless otherwise specified), forming a multi-zone composite table.
Append type: data will only be appended and will not be modified or deleted.
Update type: data may be added, modified, or deleted.
Cold mode: the query service will stop periodically, and data maintenance can be performed during such period.
Hot mode: the query service will not stop, and data maintenance must be performed at the same time.
Data source: refers to the original data storage, or the source from which data is generated.
New data: refers to the newly generated data that will be appended and updated to existing composite table.
Hot data: refers to the real-time new data generated after the last data maintenance.
Chaos period: due to various delays (such as network), the new data generated in the recent period of time may not be fully entered into the data source, which will result in a failure to read all new data when reading new data from data source. This period of time is called chaos period. In other words, all data before the chaos period can definitely be read from data source.
Scenario description
Application characteristics
1. Append type and update type are supported. For append-type, the composite table has no primary key and can have dimension fields; for update-type, the composite table has primary key and is used to modify and delete data.
2. New data can be read from external data source, and the new data script should be written according to specified rules. It may return a table sequence or cursor to meet the needs of new data of different scales.
3. Layering of multi-zone composite table: store the data in layers by time interval, for example, the data before the current day is stored in one table by day, the data of the current day is stored in one table by hour, and the data of the current hour is stored in one table by 10 minutes. In this way, we have three layers of tables, that is, day-layer table, hour-layer table and minute-layer table. The day layer is called the highest layer, the minute layer is called the lowest layer and also the write layer since data can be written directly to this layer, and the hour layer is called the middle layer. The time intervals of the day-layer table, hour-layer table and minute-layer table are one day, one hour, and 10 minutes respectively. The whole data is in a multi-zone composite table composed of the day-layer tables before the current day, the hour-layer tables of the current day and the minute-layer tables of the current hour.
4. This routine provides a query script, which takes the time interval as input parameter to find out the tables that intersect with the time interval to form a multi-zone composite table object and return. For update-type, it doesn’t require a time parameter and will directly return a multi-zone composite table object composed of all tables. When querying, hot data can be supplemented, but it only supports a small amount of data (table sequence). Calling the hot data script written according to specified rules can get the hot data.
5. For update-type and multiple tables, a manual merge script is provided in this routine to merge the updated tables into the first table (called the main table).
6. Before a new table is maintained for the first time, or if a table is not maintained for a long time, it needs to call the initialization script first to write historical data to the composite table in one go, and then the query service can be enabled to perform normal periodic operation.
Cold mode
1. The stop time for query service is sufficient to perform one data maintenance operation.
2. This mode supports single composite table and multi-zone composite table. When the total data volume is so small that the time to rewrite the whole composite table is shorter than the data maintenance period, single composite table can be used.
3. When using multi-zone composite table, the tables are stored by the time interval ‘month’, and there is only one layer.
4. The time interval between two data maintenance operations should not be less than one day (it can be longer) in principle. This routine provides a cold update script, which can be actively called to launch a maintenance operation.
5. New data can also come from prepared files, which are still selected and read by new data script based on time parameter, and a table sequence or cursor is returned.
Hot mode
1. The composite table can be accessed during data maintenance. It needs to provide corresponding means to ensure the data access is error-free.
2. The interval between two data maintenance operations may be as short as minutes.
3. This mode only supports multi-zone composite table, regardless of the data size.
4. Data layering: In order to complete data maintenance as quickly as possible during a maintenance cycle, the data is stored in layers. Use the write thread to quickly write new data to the lowest-layer table. Since the lowest-layer table is small, new data can be quickly written during the maintenance cycle.
5. Use the merge thread to merge the lowest-layer tables into the middle-layer table. After merging the lowest-layer tables, the new middle-layer table can be enabled, the original lowest-layer tables can be deleted, and then the merge thread will continue to merge the middle-layer tables into the highest-layer table. After merging the middle-layer tables, the new highest-layer table can be enabled, and the original middle-layer tables can be deleted.
6. Write layer and write period: The time interval unit of the table to which the new data is written directly is called the write layer. For example, if the data is written once every 10 minutes, then the time interval of the table is 10 minutes, and the write level is minute, and the write period is 10. The write period always takes the write layer as time unit. The write layer supports second, minute, hour and day.
7. Highest layer: The tables can be merged upwards layer by layer into large-segmentation-interval table. The time interval unit of the highest-layer table is called the highest layer. For example, if the time interval of the highest-layer table is one month, then the highest layer is month. The highest layer supports day and month. If the highest layer is month, the data of day table will be directly merged into corresponding month table when merging data into day layer, and the day table does not actually exist.
8. This routine does not support processing the data missed before the chaos period. When reading data, only the data generated before chaos period is read. The data source will ensure the data before chaos period is complete.
9. A start script is provided to start the write thread and merge thread at the same time, and loops to perform data writing and merging based on the write period and merge period.
Application structure diagram
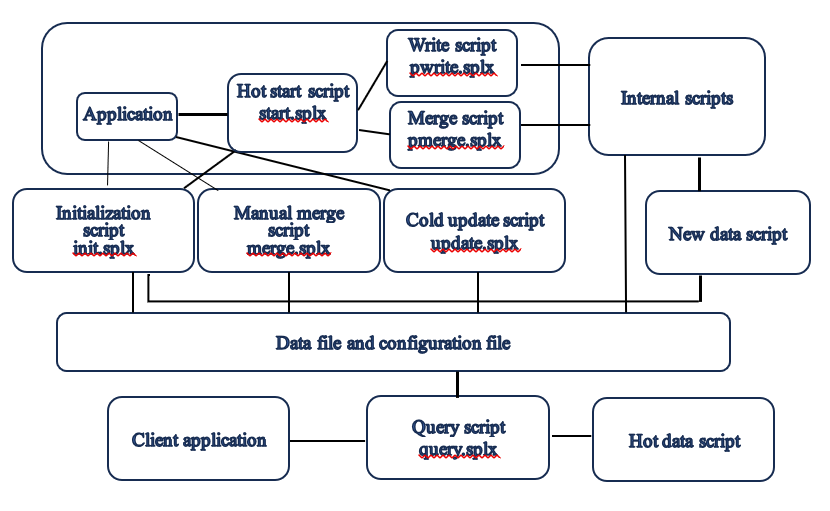
Calculation script: The query script ‘query.splx’, maintenance scripts ‘init.splx, merge.splx, update.splx’, internal scripts, and the new data script and hot data script written by users are collectively called calculation script.
Main program: The application, hot start script ‘start.splx’, write script ‘pwrite.splx’ and merge script ‘pmerge.splx’ are collectively called main program, which always runs in one process. It just needs to deploy one main program suite in the process where the application is located.
Single-process mode: The main program and the calculation script run in the same process.
Multi-process mode: The main program and the calculation script run in different processes, and the server executing the calculation script each time may be temporarily allocated. Multiple processes can access the data source and share a certain set of storage. The generated composite table will be uploaded to the shared storage for access by query script in other processes.
Internal maintenance scripts: including the zoneT.splx, zoneZ.splx, writeHistory.splx, writeHot.splx, mergeHot.splx and modConfig.splx, which are deployed together with the user interfaces init.splx, update.splx, merge.splx and query.splx as well as the new data script and hot data script written by users.
Data file and configuration file: Only deploy one set, which will be shared in multi-process mode.
User interface
Configuration information
Configuration file name: table name.json
[{ "Filename":"test.ctx",
"DataPath":"test/",
"DimKey":"account,tdate",
"TimeField":"tdate",
"OtherFields":"ColName1,ColName2",
"NewDataScript":"read1.splx",
"HotDataScript":"read2.splx",
"LastTime":"2024-01-01 00:00:00",
"Updateable":true,
"DeleteKey":"Deleted",
"Zones":null,
"ChoasPeriod":5,
"DiscardZones":null,
"WritePeriod":5,
"MultiZones":true,
"WriteLayer":"s",
"HighestLayer":"M",
"BlockSize":{"s":65536,"m":131072,"H":262144, "d":1048576} or 1048576
}]
“Filename” refers to the name of composite table file. SPL specifies that the physical file name of table as table number.Filename.
“DataPath” refers to the storage path of composite table.
“DimKey” refers to the dimension field of composite table, that is, the composite table will be sorted by these fields. For update type, the dimension filed will be used as primary key. If there are multiple dimension fields, separate them by English comma.
“TimeField” refers to the time field, which is used in the read script to filter the data that meets the given time interval.
“OtherFields” refers to the name of other fields. If there are multiple other fields, separate them by English comma.
“NewDataScript” refers to the name of script file for reading new data.
“HotDataScript” refers to the name of script file for reading hot data. If the hot data is not required when querying, set this parameter as empty.
“LastTime” refers to the last reading time. Its initial value should be filled with the start time of historical data, and will be automatically modified when executing the write script. Once in use, this configuration information cannot be modified again.
“Updateable” refers to whether it is update-type. If it is empty or filled with false, it means append type. If it is filled with true, the following configuration is also required:
“DeleteKey” refers to the deletion flag field name of composite table. If deletion is not required, set it as empty.
“Zones” refers to the list of table numbers, which is automatically generated by program and initially set as empty.
“MultiZones”: true means there are multiple tables; false means there is one table. If it is set as true, it needs to configure:
“WriteLayer” refers to the write layer, with the letters s, m, H, and d representing second, minute, hour, and day respectively.
“HighestLayer” refers to the highest layer, with the letters d and M representing day and month respectively.
“BlockSize” refers to the block size when creating tables. When MultiZones is true, it needs to be set by layer, the format is {“s”:65536,“m”:131072,“H”:262144, “d”:1048576}; when MultiZones is false, it just needs to set one value, such as 1048576. Since the data volume of low-layer table is small, we can set the block size smaller to save memory space. On the contrary, since the data volume of high-layer table is large, we can set the block size bigger to speed up data reading. The min size should generally not be less than 65,536 bytes, and the max size should not exceed 1,048,576 bytes.
“ChoasPeriod” refers to the chaos period with time unit in seconds. This parameter must be set in hot mode, and set as empty in cold mode. In hot mode, it needs to configure:
“DiscardZones” refers to the list of the table numbers that are already merged and are waiting to be deleted, which is automatically calculated by program and initially set as empty.
“WritePeriod” refers to the write period in the unit of the write layer, which is used by the loop call script in start.
New data script
This is a read script that requires users to write. This script is called by the write script and returns all new data within the specified table and time interval (that includes the start time and doesn’t include the end time in general and can be determined based on business needs).
According to business needs, the data can be read from original data sources such as database or from prepared data file and other sources. If reading from database, filter the data based on the time field name in configuration information and the time interval parameter given in this script; if reading from a data file, match the data file name based on the table name and the given time interval.
According to the previous configuration information, the field order of data is (DimKey|DeleteKey)&TimeField&OtherFields. To ensure consistent field order, it is recommended to read from the configuration file.
It is required to sort data by DimKey in the configuration information.
Input parameters:
tbl: table name
start: start time
end: end time. The default value is the current time.
Return value:
A table sequence or cursor composed of the data within the given time interval.
Hot data script
The interface is same with that of new data script.
Initialization script init.splx
This script is used for initializing a new table or supplementing historical data (when it is a new table or when the maintenance of a table is interrupted for a long time). In cold mode, it needs to actively call this script. In hot mode, this script will be automatically called by start.splx.
Input parameter:
tbl: table name
Hot-mode start script start.splx
To use this script, it needs to first call the initialization script. If a new table is used for the first time, or if it has not been maintained for a long time, the data will be automatically supplemented. Then start the write thread and merge thread respectively to perform data writing and merging periodically based on configuration information. This script, along with pwrite.splx and pmerge.splx must run in the same process to share global variables.
Input parameter:
tbl: table name
Cold update script update.splx
This script takes the end time of last data reading and the current newly given end time of data reading as input parameters to call the new data script to obtain new data. Use the last reading end time to calculate the new table number, merge the original table with the new data and write the merged data to the new table, and then delete the original table. If it is at the beginning of the month and multiple tables are needed, then enable the new tables directly. This script can only be executed when the query service is stopped.
Input parameters:
tbl: table name
end: end time of data reading
Manual merge script merge.splx
For update-type and multiple tables, use this script to merge the month tables updated before the given time into the main table. If the time parameter is null, then merge the month tables updated before the last reading time into the main table. This script can only be executed when the query service is stopped.
Input parameters:
tbl: table name
t: time. If this parameter is not null, merge the tables updated before this time. Otherwise, merge the tables updated before the last read time.
Query script query.splx
For append-type, this script takes the time interval as input parameter to find out the tables that intersect with the time interval to form a multi-zone composite table object and return. For update-type, it doesn’t require a time parameter and will directly return a multi-zone composite table object composed of all tables.
If hot data is required, take the last reading end time and input parameter ‘end’ or ‘now()’ (end is null) as the input parameter to call the hot data script, and return a multi-zone composite table composed of tables and hot data. If hot data is not required, return a multi-zone composite table consisting of tables directly.
Input parameters:
tbl: table name
start: start time. When it is null, it represents all tables before end.
end: end time. When it is null, it represents all tables after start.
Return value:
A multi-zone composite table consisting of tables and hot data (if required).
Storage structure
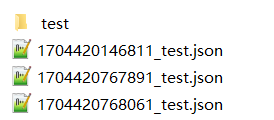
*_test.json refers to the configuration file, whose name is “long value of modification time_table name.json”.
‘test’ refers to the path of storing composite table, which is set in the configuration file.
Below is an example of the composite table files in the test directory:
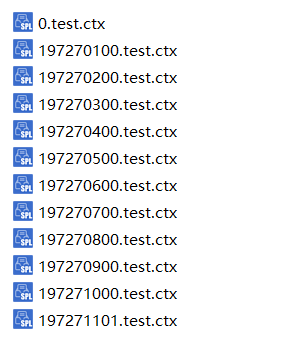
Use the start time of the time interval to which the table belongs to calculate the table number.
Calculation rules: The table number format of day/month layer/single composite table is yyyyMMdd. For the month layer/single composite table, the value of dd is the day of the last merge; the table number of hour/minute layer is dddddHHmm, where dddddd is the number of days between the current date and 1970-01-01, HH is the hour component +1, mm is the minute component +1, and the mm of hour layer is 00. The second-layer table number is long(t)\1000.
Global variables
Table name QConfig is used by query script to store configuration information.
Table name QLastReadTime is used by query script. It refers to the last time the configuration file was read. If there is a new configuration file that meets condition, it will be read again.
Table name Config is used by hot mode start script to store configuration information.
Application examples
Cold-mode and append-type single composite table
The total data volume of the commodity table of a certain supermarket is expected to be in the tens of millions, and can be stored in a single table. The daily increase in data volume is in the hundreds of thousands with no modification or deletion required. Data maintenance is performed from 23:00 every day to 2:00 the next day.
Configuration file name: Commodity.json, and its contents are as follows:
[{ "Filename":"Commodity.ctx",
"DataPath":"Commodity/",
"DimKey":"CommodityID",
"TimeField":"InputDate",
"OtherFields":"Name,QuantityPerUnit,SupplierID,UnitPrice,UnitsInStock,UnitsOnOrder",
"NewDataScript":"read1.splx",
"HotDataScript":"read2.splx",
"LastTime":"2023-01-01 00:00:00",
"MultiZones":false,
"Updateable":false,
"BlockSize":1048576,
"ChoasPeriod":null,
"Zones":null
}]
New data script example 1: read1.splx (read from file. Assume that the file naming rule is table name + date.txt. The data after the end time of the day is stored in the file of the next day. The time 23:00 every day is the end time of the day).
| A | |
| 1 | =periods@o(start,end).(string(~,"yyyyMMdd")).to(2,) |
| 2 | =(((config.DimKey.split@c()|if(config.Updateable,config.DeleteKey,null))&config.TimeField)&config.OtherFields.split@c()).concat@c() |
| 3 | =A1.(file(tbl+~+".txt").cursor@t(A2).sortx(config.DimKey)).mergex(config.DimKey) |
| 4 | return A3 |
A1: Calculate the date on which the file needs to be read based on the start and end time. Here the default assumption is that the data file of the day to which ‘start’ belongs is already read last time.
A2: Construct the field names for the returned data according to the rules.
A3: Read the data file and sort the data according to rules. If there are multiple files, concatenate them into single cursor and return.
New data script example 2: read1.splx (read from database):
| A | |
| 1 | >config=json(file(tbl+".json").read()) |
| 2 | =(((config.DimKey.split@c()|if(config.Updateable,config.DeleteKey,null))&config.TimeField)&config.OtherFields.split@c()).concat@c() |
| 3 | =connect("mysql") |
| 4 | =A3.query("select"+A2+"from"+tbl+"where"+config.TimeField+">=?"+if(end,"and"+config.TimeField+"< ?","")+" order by "+config.DimKey,start${if(end,",end","")}) |
| 5 | =A3.close() |
| 6 | return A4 |
A1: Read the configuration file.
A2: Construct the field names for the returned data according to the rules.
A4: Concatenate the SQL statement based on the table name, field name, sorting field, and time filtering condition, etc., and execute the query. Here the time filtering condition is that the start time is included, and the end time is not included.
Hot data script: read2.splx
Refer to the new data script example 2.
Initialize before using a new table for the first time:
| A | |
| 1 | =call("init.splx","Commodity") |
Perform the write operation once every day at 23:00, and call the write script as follows:
| A | B | |
| 1 | =now() | =23 |
| 2 | =[year(A1),month(A1),day(A1),hour(A1)] | |
| 3 | >A2(4)=if(A2(4)>=B1,B1,B1-24) | |
| 4 | =datetime(A2(1),A2(2),A2(3),A2(4),0,0) | |
| 5 | =call("update.splx","Commodity",A4) | |
A1-A4: Round the current time by 23:00.
Query script:
| A | |
| 1 | =call("query.splx","Commodity",null,now()) |
Because this is a single composite table, there is no need to filter the table numbers by time, and the start time parameter is not given when querying. Since the hot data is required to be returned in this example, the end time parameter is given to read the hot data.
Cold-mode and update-type multi-zone composite table
There is a need to add, delete, and modify data in the order table of a certain supermarket. The monthly data volume is less than 10 million, and needs to be stored in multiple tables. The account closing time is from 23:00 every day to 6:00 the next day. During this period, it just needs to add the new data to the tables once. When querying, it is expected to query data as fast as possible, and it is required to merge the hot data with the tables to form a multi-zone composite table and return.
Configuration file name: orders.json, and its contents are as follows:
[{ "Filename":"orders.ctx",
"DataPath":"orders/",
"DimKey":"userid,orderTime",
"TimeField":"lastModifyTime",
"OtherFields":"orderid,amount,paymentMode",
"NewDataScript":"readOrders.splx",
"HotDataScript":"readOrders.splx",
"LastTime":null,
"MultiZones":true,
"WriteLayer":"d",
"HighestLayer":"M",
"Updateable":true,
"DeleteKey":"Deleted",
"BlockSize":{"d":1048576},
"Zones":null
}]
MultiZones is set as true, indicating that multiple tables are required for storage.
WriteLayer is set as d, indicating that write operation is performed once a day.
HighestLayer is set as M, indicating that the tables are stored by month.
New data script readOrders.splx:
| A | |
| 1 | >config=json(file(tbl+".json").read()) |
| 2 | =(((config.DimKey.split@c()|if(config.Updateable,config.DeleteKey,null))&config.TimeField)&config.OtherFields.split@c()).concat@c() |
| 3 | =connect("mysql") |
| 4 | =A3.query("select"+A2+"from"+tbl+"where"+config.TimeField+">=?"+if(end,"and"+config.TimeField+"< ?","")+" order by "+config.DimKey,start${if(end,",end","")}) |
| 5 | =A3.close() |
| 6 | return A4 |
A1: Read the configuration file.
A2: Construct the field names for the returned data according to the rules.
A4: Concatenate the SQL statement based on the table name, field name, sorting field, and time filtering condition, etc., and execute the query. Here the time filtering condition is that the start time is included, and the end time is not included.
Initialize before using a new table for the first time:
| A | |
| 1 | =call("init.splx","orders") |
Perform the write operation once every day at 23:00, and call the write script as follows:
| A | B | |
| 1 | =now() | =23 |
| 2 | =[year(A1),month(A1),day(A1),hour(A1)] | |
| 3 | >A2(4)=if(A2(4)>=B1,B1,B1-24) | |
| 4 | =datetime(A2(1),A2(2),A2(3),A2(4),0,0) | |
| 5 | =call("update.splx","orders",A4) | |
A1-A4: Round the current time by 23:00.
Query script:
| A | |
| 1 | =call("query.splx","orders") |
For update type, there is no need to filter the table numbers. If the end time parameter is not given, it means the hot data is read to now().
Call the manual merge script:
| A | |
| 1 | =call("merge.splx","orders",now()) |
Hot-mode and append-type multi-zone composite table
A certain e-commerce platform provides 24/7 service, and its order table adds about 10 million pieces of data every day, and there is only new data adding requirement without data deletion or modification requirement. Moreover, it is required to query hot data in real time besides querying all table files, and merge the hot data with the tables to form a multi-zone composite table and return.
The amount of data in this example is large, and new data may be generated every moment. In most situations, query is performed by day or week. Only occasionally will managers make statistics by month and make comparison between months. Therefore, the write layer is set as minute, and the highest layer is set as day.
Configuration file name: orders.json, and its contents are as follows:
[{ "Filename":"orders.ctx",
"DataPath":"orders/",
"DimKey":"userid,orderDate",
"TimeField":"orderDate",
"OtherFields":"orderid,amount,paymentMode,address,mobile,deliveryTime,deliveryFee",
"NewDataScript":"read1.splx",
"HotDataScript":"read2.splx",
"LastTime":"2024-01-01 00:00:00",
"ChoasPeriod":5,
"Updateable":false,
"WriteLayer":"m",
"HighestLayer":"d",
"BlockSize":{"m":131072,"H":262144, "d":1048576},
"Zones":null,
"DiscardZones":null
}]
Call start.splx to start data maintenance:
| A | |
| 1 | =call("start.splx","orders") |
Query script:
| A | |
| 1 | =call("query.splx","orders",datetime("2024-01-01 00:00:00"),,datetime("2024-01-07 00:00:00")) |
Implementation scheme and code analysis
The following codes are written in single-machine mode.
init.splx
This script is used for initializing a new table or supplementing historical data (when a new table is used for the first time or when the maintenance of a table is interrupted for a long time). In cold mode, this script needs to be actively called. In hot mode, it will be automatically called by start.splx.
Input parameter:
tbl: table name
Return value:
Configuration information of tbl.
| A | B | C | |
| 1 | =directory("*_"+tbl+".json").sort(~:-1) | ||
| 2 | >config=json(file(A1(1)).read()) | ||
| 3 | if(!config.Zones) | ||
| 4 | >config.Zones=create(s,m,H,d).insert(0,[],[],[],[]) | ||
| 5 | if(config.ChoasPeriod) | ||
| 6 | >config.DiscardZones=create(s,m,H,d).insert(0,[],[],[],[]) | ||
| 7 | =file(A1(1)).write(json(config)) | ||
| 8 | =file(config.DataPath/config.Filename:0) | ||
| 9 | if(!A8.exists()) | ||
| 10 | =config.DimKey.split@c() | ||
| 11 | =B10.("#"+trim(~)).concat@c() | ||
| 12 | if(!B10.pos(config.TimeField)) | ||
| 13 | =(config.TimeField&config.OtherFields.split@c()).concat@c() | ||
| 14 | else | >C13=config.OtherFields | |
| 15 | =if(config.MultiZones,config.BlockSize.d,config.BlockSize) | ||
| 16 | if(config.Updateable && config.DeleteKey) | ||
| 17 | =A8.create@yd(${B11},${config.DeleteKey},${C13};;B15) | ||
| 18 | else | >C17=A8.create@y(${B11},${C13};;B15) | |
| 19 | =C17.close() | ||
| 20 | =register("zoneT","zoneT.splx") | ||
| 21 | =register("zoneZ","zoneZ.splx") | ||
| 22 | =call("writeHistory.splx",tbl) | ||
| 23 | return A22 | ||
A1: List all configuration files and sort them in reverse order.
A2: Read the first configuration file.
A3: If Zones is empty (that is, the new table is used for the first time).
B4-B7: Initialize Zones and DiscardZones, and save them back to the configuration file.
A8: Table 0.
A9-B19: If table 0 does not exist, create a table 0.
A20-A21: Register esProc functions zoneT and zoneZ.
A22: Supplement historical data (read and write historical data in one go when a new table is used for the first time; or supplement the historical data of the interruption period in one go when the maintenance of a table is interrupted for a long time), and return new configuration information.
A23: Return the configuration information.
zoneT.splx
Convert time to the table number of the corresponding layer.
Input parameters:
tm: time
L: target layer whose values are s, m, H and d, representing second layer, minute layer, hour layer, and day layer respectively.
Return value:
Table number that tm corresponds to target layer.
| A | B | |
| 1 | 1970-01-01 | |
| 2 | if(L=="d") | return year(tm)*10000+month(tm)*100+day(tm) |
| 3 | else if(L=="H") | return (tm-A1)*10000+(hour(tm)+1)*100 |
| 4 | else if(L=="m") | return (tm-A1)*10000+(hour(tm)+1)*100+minute(tm)+1 |
| 5 | else | return long(tm)\1000 |
A1: Base time.
A2-B2: If the target layer is day, return the table number in the format of yyyyMMdd.
A3-B3: If the target layer is hour, return the table number in the format of dddddHH00, where ddddd is the number of days between tm and A1, and HH is the hour component +1.
A4-B4: If the target layer is minute, return the table number in the format of dddddHHmm, where ddddd is the number of days between tm and A1, HH is the hour component +1, and mm is the minute component +1.
A5-B5: If the target layer is second, return long(tm)\1000.
zoneZ.splx
This script is used to convert the low-layer table number to high-layer table number.
Input parameters:
z: low-layer table number
L: target layer whose values are m, H and d, representing the minute layer, hour layer and day layer respectively.
I: low layers whose values are s, m and H, representing the second layer, minute layer and hour layer respectively.
Return value:
Table number that z corresponds to L.
| A | B | C | |
| 1 | if(l=="s" || L=="m") | ||
| 2 | =datetime(z*1000) | ||
| 3 | =zoneT(B2,L) | ||
| 4 | else | if(L=="H") | return (z\100)*100 |
| 5 | else | =z\10000 | |
| 6 | 1970-01-01 | ||
| 7 | =C6+C5 | ||
| 8 | return year(C7)*10000+month(C7)*100+day(C7) | ||
A1-B3: If the low layer is second, first covert second-layer table number to data and time, and then calculate the table number of target layer.
B4-C4: If the target layer is hour, directly change the last two digits to 00.
C5-C8: If the target layer is day, first calculate the actual date based on the base date, and then return the table number in yyyyMMdd format.
writeHistory.splx
This script is used to supplement thereading of the historical data of yesterday and before. The script is called by init.splx, and will only be executed once when the server starts and won’t be executed again.
Input parameter:
tbl: table name
| A | B | C | D | E | |
| 1 | =directory("*_"+tbl+".json").sort(~:-1) | ||||
| 2 | >config=json(file(A1(1)).read()) | ||||
| 3 | =if(!config.LastTime || ifdate(config.LastTime),config.LastTime,datetime(config.LastTime)) | ||||
| 4 | =if(config.ChoasPeriod,elapse@s(now(),-config.ChoasPeriod),now()) | ||||
| 5 | =datetime(date(A4),time("00:00:00")) | ||||
| 6 | if(config.MultiZones && !config.Updateable && A5>A3) | ||||
| 7 | =config.Zones.H.new(~:zd,zoneZ(~,"d","H"):zu)| config.Zones.m.new(~:zd,zoneZ(~,"d","m"):zu)| config.Zones.s.new(~:zd,zoneZ(~,"d","s"):zu) | ||||
| 8 | =B7.group(zu;~.(zd):zd) | ||||
| 9 | = zoneT(A4,"d") | ||||
| 10 | >B8=B8.select(zu< B9) | ||||
| 11 | =config.HighestLayer=="M" | ||||
| 12 | if(B11) | >B8=B8.group(zu\100;~.m(-1).zu,~.(zd).conj():zd) | |||
| 13 | =config.Zones.d.m(-1) | ||||
| 14 | for B8 | =C13\100==B14.zu\100 | |||
| 15 | if(B11 && C14, C13,null) | ||||
| 16 | =file(config.DataPath/config.Filename:C15|B14.zd) | ||||
| 17 | >d=B14.zu%100,m=(B14.zu\100)%100,y=B14.zu\10000 | ||||
| 18 | =if(B11,datetime(y,m+1,1,0,0,0),datetime(y,m,d+1,0,0,0)) | ||||
| 19 | =min(A5,C18) | ||||
| 20 | =call(config.NewDataScript,tbl,A3,C19) | ||||
| 21 | =zoneT(elapse(C19,-1),"d") | ||||
| 22 | =file(config.DataPath/config.Filename:C21) | ||||
| 23 | =C16.reset@y${if(config.Updateable,"w","")}(C22:config.BlockSize.d;C20) | ||||
| 24 | >config.Zones.H=config.Zones.H\B14.zd, config.Zones.m=config.Zones.m\B14.zd, config.Zones.s=config.Zones.s\B14.zd, config.Zones.d=(config.Zones.d\C15)|C21, A3=C19 | ||||
| 25 | =(C15|B14.zd).(movefile@y(config.DataPath/~/"."/config.Filename)) | ||||
| 26 | if(A5>A3) | if(B11) | =periods@m(A3,A5) | ||
| 27 | =config.Zones.d.m(-1) | ||||
| 28 | else | >D26=periods(A3,A5) | |||
| 29 | for D26.to(2,) | ||||
| 30 | =elapse(C29,-1) | ||||
| 31 | =year(D30)*10000+month(D30)*100+day(D30) | ||||
| 32 | =file(config.DataPath/config.Filename:D31) | ||||
| 33 | =call(config.NewDataScript,tbl,A3,C29) | ||||
| 34 | =if(B11 && D27\100==D31\100,D27,0) | ||||
| 35 | =file(config.DataPath/config.Filename:D34) | ||||
| 36 | =D35.reset@y${if(config.Updateable,"w","")}(D32:config.BlockSize.d;D33) | ||||
| 37 | if(D34!=0) | =movefile@y(config.DataPath/D34/"."/config.Filename) | |||
| 38 | >config.Zones.d=config.Zones.d\D34 | ||||
| 39 | >A3=C29, config.Zones.d=config.Zones.d|D31 | ||||
| 40 | >config.LastTime=A3 | ||||
| 41 | else if(!config.MultiZones && A5>A3) | ||||
| 42 | =elapse(A5,-1) | ||||
| 43 | >newZone=year(B42)*10000+month(B42)*100+day(B42) | ||||
| 44 | >oldZone=if(config.Zones.d.len()>0,config.Zones.d.m(-1),0) | ||||
| 45 | =file(config.DataPath/config.Filename:oldZone) | ||||
| 46 | =file(config.DataPath/config.Filename:newZone) | ||||
| 47 | =call(config.NewDataScript,tbl,A3,A5) | ||||
| 48 | =B45.reset@y${if(config.Updateable,"w","")}(B46:config.BlockSize;B47) | ||||
| 49 | if(oldZone!=0) | =movefile@y(config.DataPath/oldZone/"."/config.Filename) | |||
| 50 | >config.Zones.d=[newZone] | ||||
| 51 | >config.LastTime=A5 | ||||
| 52 | else if(config.Updateable) | ||||
| 53 | =0 | config.Zones.d | config.Zones.H | config.Zones.m| config.Zones.s | ||||
| 54 | =file(config.DataPath/config.Filename:B53) | ||||
| 55 | =file(config.DataPath/config.Filename:1) | ||||
| 56 | =call(config.NewDataScript,tbl,A3,A5) | ||||
| 57 | =B54.reset@y${if(config.Updateable,"w","")}(B55:config.BlockSize.d;B56) | ||||
| 58 | =movefile@y(config.DataPath/1/"."/config.Filename,0/"."/config.Filename) | ||||
| 59 | =(config.Zones.d | config.Zones.H | config.Zones.m| config.Zones.s).(movefile@y(config.DataPath/~/"."/config.Filename)) | ||||
| 60 | >config.Zones.d=[],config.Zones.H=[],config.Zones.m=[],config.Zones.s=[] | ||||
| 61 | >config.LastTime=A5 | ||||
| 62 | =file(long(now())/"_"/tbl/".json").write(json(config)) | ||||
| 63 | return config | ||||
A1-A2: Read the configuration file.
A3: Last read time.
A4: Chaos period time.
A5: Calculate the end time of current data reading based on the chaos period time.
A6: If it is an append-type multi-zone composite table, read the data one by one by the time interval of the highest-layer table.
First process the time interval of the existing low-layer tables.
B7: Read hour-layer, minute-layer and second-layer tables, and calculate their corresponding day-layer table numbers.
B8: Group B7 by their corresponding day-layer table number respectively.
B9: Calculate the corresponding day-layer table number based on the chaos period time.
B10: Select the tables from yesterday and before.
B11: Determine whether the highest layer is month.
B12: If the highest layer is month.
C12: Regroup B8 by month and retain the max table number of each month.
C13: Read the last table number in the existing highest-layer table numbers.
B14: Loop by B8.
C14: Determine whether the current new table number and C13 are in the same month.
C15: If the highest layer is month and C14 is satisfied, then C13 is also used for merging.
C16: Generate a multi-zone composite table using the low-layer tables and C15.
C17-C18: Based on the highest-layer table number corresponding to the current group, calculate the end value of its corresponding time interval.
C19: Take the smaller value of A5 and C18 to serve as the end time of current data reading.
C20: Read the new data.
C21: Calculate the new table number based on C19.
C22: Generate new table.
C23: Merge the new data with the low-layer tables, and write the merged data to the new table.
C24: Delete the merged table numbers from the configuration information, add the new table number to the configuration information, and update A3 to serve as the end time of new data reading.
C25: Delete the merged tables from the hard disk.
B26: If there is still unread historical data, then proceed to process the time interval where no lower-layer table exists.
C26-D28: If the highest layer is month, calculate the end time of each month between A3 and A5. Otherwise, calculate the end time of each day.
C29: Loop from the second member of D26 (the first member is the start time).
D30-D36: Read the data one by one by the time interval of the highest-layer table, and write them to the table.
D37-E38: If the merged month table exists, delete it and remove it from the list of table numbers at the same time.
D39: Update A3 to serve as the new end time of data reading and add the newly generated table number to the list of table numbers.
B40: Update the last read time in the configuration information.
A41: If it is a single composite table.
B42-B48: Read new data, merge the new data with original table, and write the merged data to new table.
B49: Delete the original table.
B50: Store the new table number into configuration information.
B51: Update the last read time in the configuration information.
A52: If it is update-type.
B53-B57: Read new data, merge the new data with all low-layer tables, and write the merged data to table 1.
B58: Rename table 1 to table 0 and overwrite it.
B59: Delete all merged low-layer tables.
B60: Delete all merged low-layer tables from the configuration information.
B61: Update the last read time in the configuration information.
A62: Write the configuration information to the new configuration file.
A63: Return the configuration information.
start.splx
This script is the hot-mode start script. To use it, it needs to first call the initialization script, which will supplement data automatically when a new table is used for the first time, or when the maintenance of a table is interrupted for a long time. Then start the write thread and merge thread respectively to perform data write and merge operations periodically based on configuration information. This script, along with pwrite.splx and pmerge.splx must run in the same process to share global variables.
Input parameter:
tbl: table name
| A | |
| 1 | =call("init.splx",tbl) |
| 2 | =env(${tbl}Config,A1) |
| 3 | =call@r("pwrite.splx",tbl) |
| 4 | =call@r("pmerge.splx",tbl) |
A1: Call the initialization script.
A2: Declare the global variable ${tbl}Config and assign the configuration information to it.
A3: Start the write thread.
A4: Start the merge thread.
pwrite.splx
This script is called cyclically based on the write period defined in configuration information to perform write operation of new data. This script is called by the hot-mode start script ‘start.splx’.
Input parameter:
tbl: table name
| A | B | C | |
| 1 | =elapse@s(now(),-${tbl}Config.ChoasPeriod) | ||
| 2 | =if(ifdate(${tbl}Config.LastTime),${tbl}Config.LastTime,datetime(${tbl}Config.LastTime)) | ||
| 3 | >e=A1 | ||
| 4 | >i=1 | ||
| 5 | if(${tbl}Config.WriteLayer=="s") | ||
| 6 | =datetime(year(A1),month(A1),day(A1),hour(A1),minute(A1),second(A1)) | ||
| 7 | =datetime(year(A2),month(A2),day(A2),hour(A2),minute(A2)+1,0) | ||
| 8 | >e=min(B6,B7) | ||
| 9 | >i=1 | ||
| 10 | else if(${tbl}Config.WriteLayer=="m") | ||
| 11 | =datetime(year(A1),month(A1),day(A1),hour(A1),minute(A1),0) | ||
| 12 | =datetime(year(A2),month(A2),day(A2),hour(A2)+1,0,0) | ||
| 13 | >e=min(B11,B12) | ||
| 14 | >i=60 | ||
| 15 | else if(${tbl}Config.WriteLayer=="H") | ||
| 16 | =datetime(year(A1),month(A1),day(A1),hour(A1),0,0) | ||
| 17 | =datetime(year(A2),month(A2),day(A2)+1,0,0,0) | ||
| 18 | >e=min(B16,B17) | ||
| 19 | >i=3600 | ||
| 20 | else if(${tbl}Config.WriteLayer=="d") | ||
| 21 | >e=datetime(year(A1),month(A1),day(A1),0),0,0) | ||
| 22 | if(${tbl}Config.HighestLayer=="M") | ||
| 23 | =datetime(year(A2),month(A2)+1,0,0,0,0) | ||
| 24 | >e=min(e,C23) | ||
| 25 | >i=24*3600 | ||
| 26 | else | return | end tbl+"write layer definition error" |
| 27 | if(e>A2) | ||
| 28 | =call("writeHot.splx",tbl,e,${tbl}Config) | ||
| 29 | =lock(tbl+"Config") | ||
| 30 | =call@r("modConfig.splx",tbl,e, B28) | ||
| 31 | =env(${tbl}Config,B30) | ||
| 32 | =lock@u(tbl+"Config") | ||
| 33 | goto A1 | ||
| 34 | else | =elapse@s(A2,${tbl}Config.WritePeriod*i+${tbl}Config.ChoasPeriod) | |
| 35 | =sleep(max(interval@ms(now(),B34),0)) | ||
| 36 | goto A1 | ||
A1: Chaos period time.
A2: End time of last data reading.
A5-A26: Round A1 according to the time unit of different write layers, calculate the end time of the time interval of their corresponding upper-layer tables based on A2, take the smaller one of the two values to serve as the end time of current data reading, and assign this value to variable e.
A27: If e is greater than A2.
B28: Call the write script to execute write operation.
B29-B32: Lock, update the configuration information modifications returned by B28 to the configuration file, return new configuration information, and update the global variable.
B33: Go to A1 to execute the next round of write operation.
A34: Otherwise:
B34-B36: Calculate the length of time to wait before executing the next round of write operation and sleep. Then go to A1 to execute the next round of write operation.
pmerge.splx
This script is called cyclically based on the layer information defined in configuration information to perform merge operation. This script is called by the hot-mode start script ‘start.splx’.
Input parameter:
tbl: table name
| A | B | |
| 1 | >tm=max(elapse@s(now(),-${tbl}Config.ChoasPeriod-3600), if(ifdate(${tbl}Config.LastTime),${tbl}Config.LastTime,datetime(${tbl}Config.LastTime))) | |
| 2 | =${tbl}Config.WriteLayer | |
| 3 | if A2=="s" | =datetime(year(tm),month(tm),day(tm),hour(tm),minute(tm)+1, ${tbl}Config.WritePeriod) |
| 4 | else if A2=="m" | >B3=datetime(year(tm),month(tm),day(tm),hour(tm)+1, ${tbl}Config.WritePeriod,0) |
| 5 | else if A2=="H" | >B3=datetime(year(tm),month(tm),day(tm)+1, ${tbl}Config.WritePeriod,0,0) |
| 6 | else | return |
| 7 | =call("mergeHot.splx",tbl,${tbl}Config) | |
| 8 | =lock(tbl+"Config") | |
| 9 | =call("modConfig.splx",tbl,null, A7) | |
| 10 | =env(${tbl}Config,A9) | |
| 11 | =lock@u(tbl+"Config") | |
| 12 | =sleep(max(0,long(B3)-long(now())) | |
| 13 | goto A1 | |
A1: Use max (now-chaos period-1 hour, last read time) to calculate the base time of the current round of merging.
A3-B6: Calculate the time of next round of merging based on the time unit of write layer.
A7: Call the merge script to execute merge operation.
A8-A11: Lock, update the configuration information modifications returned by A7 to the configuration file, return the new configuration information, and update the global variable.
A12: Sleep based on the previously calculated time of next round of merging.
A13: Go to A1 to execute the next round of merge operation.
writeHot.splx
This script takes the end time of last data reading and the current given end time of data reading as time interval to call the new data script to obtain new data, and calculates the table number based on the start time, and writes the new data directly to the new table.
Input parameters:
tbl: table name
end: end time of data reading
config: configuration file information
Return value:
A table sequence consisting of fields ‘new’ and ‘discard’, which represent the newly generated table numbers and the table numbers that are already merged and waiting to be deleted respectively.
| A | B | C | |
| 1 | =if(ifdate(config.LastTime),config.LastTime,datetime(config.LastTime)) | ||
| 2 | if(end>elapse@s(now(),-config.ChoasPeriod)|| end< =A1) | ||
| 3 | return | end | |
| 4 | =call(config.NewDataScript,tbl,A1,end) | ||
| 5 | =config.DimKey.split@c() | ||
| 6 | =A5.("#"+trim(~)).concat@c() | ||
| 7 | if(!A5.pos(config.TimeField)) | ||
| 8 | =(config.TimeField&config.OtherFields.split@c()).concat@c() | ||
| 9 | else | >B8=config.OtherFields | |
| 10 | >newZone=zoneT(A1,config.WriteLayer) | ||
| 11 | =file(config.DataPath/config.Filename:newZone) | ||
| 12 | =(config.WriteLayer=="d" && config.HighestLayer=="M") | ||
| 13 | if(A12) | =config.Zones.${config.WriteLayer}.m(-1) | |
| 14 | = B13 && B13\100==newZone\100 | ||
| 15 | =create(new,discard).insert(0,create(${config.WriteLayer}).insert(0,[]),create(${config.WriteLayer}).insert(0,[])) | ||
| 16 | if(A12 && B14) | ||
| 17 | =file(config.DataPath/config.Filename:B13) | ||
| 18 | =B17.reset@y${if(config.Updateable,"w","")}(A11:config.BlockSize.WriteLayer;A4) | ||
| 19 | >A15.discard.${config.WriteLayer}.insert(0,B13) | ||
| 20 | else | if(config.Updateable && config.DeleteKey) | |
| 21 | =A11.create@yd(${A6},${config.DeleteKey},${B8};;config.BlockSize.${config.WriteLayer}) | ||
| 22 | else | >C21=A11.create@y(${A6},${B8};;config.BlockSize.${config.WriteLayer}) | |
| 23 | =C21.append@i(A4) | ||
| 24 | =C21.close() | ||
| 25 | >A15.new.${config.WriteLayer}.insert(0,newZone) | ||
| 26 | return A15 | ||
A1: Last read time.
A2-C3: If the given end time of data reading is unreasonable, return directly.
A4: Take the last read time and the current given end time of data reading as parameter to call the new data script.
A5-B9: Construct the dimension field and other fields for later use.
A10: Calculate the new table number based on the last read time.
A11: New table file.
A12-B14: If the write layer is day and the highest layer is month, read the last table number from the list of table numbers to check whether it is in the same month as the current new table number.
A15: Generate a table sequence consisting of fields ‘new’ and ‘discard’ to store the newly generated table number and the table numbers that are already merged and waiting to be deleted.
A16: If the write layer is day and the highest layer is month, and the table number that is in the same month as the current new table number exists:
B17-B19: Merge the original month table with new data, write the merged data to new month table, and put the original month table into the to-be-deleted list.
A20: Otherwise:
B20-B24: Create a new table and write new data to the new table.
A25: Add the new table number to A15.
A26: Return A15.
mergeHot.splx
This script takes max (now-chaos period-1 hour, last read time) as the judgment basis to merge the low-layer tables prepared before this time, and then write them to the corresponding high-layer table. This operation is performed only when all low-layer tables corresponding to the high-layer table are ready.
Input parameters:
tbl: table name
config: configuration information
Return value:
A table sequence consisting of fields ‘new’ and ‘discard’, which represent the newly generated table numbers and the table numbers that are already merged and waiting to be deleted respectively.
| A | B | C | D | |
| 1 | if(config.WriteLayer=="d") | |||
| 2 | return | end | ||
| 3 | else if(config.WriteLayer=="s") | |||
| 4 | >L=["m","H","d"] | |||
| 5 | else if(config.WriteLayer=="m") | |||
| 6 | >L=["H","d"] | |||
| 7 | else | >L=["d"] | ||
| 8 | >tm=max(elapse@s(now(),-config.ChoasPeriod-3600), if(ifdate(config.LastTime),config.LastTime,datetime(config.LastTime))) | |||
| 9 | =create(new,discard).insert(0,create(s,m,H,d).insert(0,[],[],[],[]),create(s,m,H,d).insert(0,[],[],[],[])) | |||
| 10 | for L | = zoneT(tm,A10) | ||
| 11 | =if(A10=="d":"H",A10=="H":"m";"s") | |||
| 12 | >zz = config.Zones.${B11}|A9.new.${B11} | |||
| 13 | if zz.len()>0 | |||
| 14 | =zz.group(zoneZ( ~, A10,B11):zu;~:zd) | |||
| 15 | =C14.select(zu< B10) | |||
| 16 | if(C15.len()==0) | |||
| 17 | next A10 | |||
| 18 | =(A10=="d" && config.HighestLayer=="M") | |||
| 19 | if(C18) | =config.Zones.${A10}.m(-1) | ||
| 20 | >C15=C15.group(zu\100;~.m(-1).zu,~.(zd).conj():zd) | |||
| 21 | for C15 | =(D19\100==C21.zu\100) | ||
| 22 | =if(C18 && D21,D19,null) | |||
| 23 | =file(config.DataPath/config.Filename:D22|C21.zd) | |||
| 24 | =file(config.DataPath/config.Filename:C21.zu) | |||
| 25 | =D23.reset@y${if(config.Updateable,"w","")}(D24:config.BlockSize.${A10}) | |||
| 26 | =A9.new.${B11}^C21.zd | |||
| 27 | =C21.zd\D26 | |||
| 28 | >A9.new.${B11}=A9.new.${B11}\D26 | |||
| 29 | =D26.(movefile@y(config.DataPath/~/"."/config.Filename)) | |||
| 30 | >A9.discard.${B11}=A9.discard.${B11}|D27, A9.new.${A10}=A9.new.${A10}|C21.zu, A9.discard.${A10}=A9.discard.${A10}|D22 | |||
| 31 | return A9 | |||
A1-B7: Calculate the layers that need to be looped.
A8: Use max (now-chaos period-1 hour, last read time) as the base time for merging.
A9: Generate a table sequence consisting of fields ‘new’ and ‘discard’ to store the newly generated table numbers and the table numbers that are already merged and waiting to be deleted.
A10: Loop by L.
B10: Calculate the table numbers corresponding to the target layer based on the base time.
B11-B12: Read the list of low-layer table numbers.
B13: If the low-layer table numbers are not empty.
C14: Group the low-layer table numbers by their corresponding high-layer table number.
C15: Select the groups whose high-layer table number is smaller than B10 (indicating that all lower-layer tables corresponding to such group are ready).
C16-D17: If C15 is empty, continue to loop to the upper layer.
C18-D20: If the target layer is day and the highest layer is month, take the last table number of the target layer for later use, and re-group C15 by month.
C21: Loop by C15.
D21-D25: If the target layer is day, the highest layer is month, and the table number of current month exists, merge the tables of current month with the lower-layer table and write the merged data to the new month table, otherwise only merge the lower-layer tables.
D26: Take the intersection of the merged table numbers and newly generated table number.
D27: Delete D26 from the list of the merged table numbers.
D28: Delete D26 from the list of newly generated table numbers.
D29: Delete the file corresponding to D26 from the hard disk.
D30: Add the newly generated table numbers and the merged table numbers to A9.
A31: Return A9.
modConfig.splx
After calling the write script or merge script each time, receive the return value and pass it to the configuration modifying script to modify the configuration file. This script must be locked when executing to ensure serial execution.
Input parameters:
tbl: table name
LastTime: the end time of last data reading
Zones: list of table numbers to be modified, which is the return value of the write script or merge script.
Return value:
New tbl configuration information
| A | B | C | |
| 1 | =directory("*_"+tbl+".json").sort(~:-1) | ||
| 2 | >config=json(file(A1(1)).read()) | ||
| 3 | if(LastTime) | ||
| 4 | >config.LastTime=LastTime | ||
| 5 | if(!LastTime || Zones.discard.#1.len()>0) | ||
| 6 | =config.DiscardZones.fname() | ||
| 7 | for B6 | ||
| 8 | =config.DiscardZones.${B7}.(movefile(config.DataPath/~/"."/config.Filename)) | ||
| 9 | =C8.pselect@a(~==false) | ||
| 10 | >config.DiscardZones.${B7}=config.DiscardZones.${B7}(C9) | ||
| 11 | =Zones.discard.fname() | ||
| 12 | for A11 | ||
| 13 | >config.DiscardZones.${A12}=config.DiscardZones.${A12}|Zones.discard.${A12} | ||
| 14 | >config.Zones.${A12}=config.Zones.${A12}\Zones.discard.${A12} | ||
| 15 | =Zones.new.fname() | ||
| 16 | for A15 | ||
| 17 | >config.Zones.${A16}=config.Zones.${A16}|Zones.new.${A16} | ||
| 18 | =file(long(now())/"_"/tbl/".json").write(json(config)) | ||
| 19 | =long(elapse@s(now(),-120)) | ||
| 20 | =A1.select(#>2 && long(left(~,13))< A19) | ||
| 21 | =A20.(movefile@y(~)) | ||
| 22 | return config | ||
A1: List configuration files and sort them in reverse order.
A2: Read the first configuration file.
A3-B4: If the given new read time is not empty, update to config.
A5-C10: If the given new read time is empty, or the table number to be deleted is not empty (indicating that it is a merge operation), delete the original discarded table number first.
A11-B14: Delete the newly discarded table number from the list and from the hard disk.
A15-B17: Add the new table number to the list.
A18-A21: Sort the configuration files by time, and delete the configuration files whose number is greater than 2 and whose time is earlier than 2 minutes ago.
A22: Return new configuration information.
update.splx
This script takes the end time of last data reading and the current given end time as input parameter to call the new data script to obtain new data, calculates new table number based on the new end time of data reading, merges the original table with the new data and write the merged data to new table, and deletes the original table. If it is at the beginning of a month and multiple tables are needed, then enable the new table directly. This script can only be executed when the query service is stopped.
Input parameters:
tbl: table name
end: end time of data reading
| A | B | C | |
| 1 | =directory("*_"+tbl+".json").sort(~:-1) | ||
| 2 | >config=json(file(A1(1)).read()) | ||
| 3 | =if(config.LastTime,datetime(config.LastTime),null) | ||
| 4 | if((A3 && end< elapse(A3,1)) || end>now()) | ||
| 5 | return | end "unreasonable end time" | |
| 6 | =call(config.NewDataScript,tbl,A3,end) | ||
| 7 | =elapse(end,-1) | ||
| 8 | >newZone=year(A7)*10000+month(A7)*100+day(A7) | ||
| 9 | >oldZone=if(config.Zones.d.len()>0,config.Zones.d.m(-1),0) | ||
| 10 | =config.BlockSize | ||
| 11 | if(config.MultiZones && config.HighestLayer=="M") | ||
| 12 | if(oldZone!=0 && oldZone\100!=newZone\100) | ||
| 13 | >oldZone=0 | ||
| 14 | >A10=config.BlockSize.d | ||
| 15 | =file(config.DataPath/config.Filename:newZone) | ||
| 16 | =file(config.DataPath/config.Filename:oldZone) | ||
| 17 | =A16.reset@y${if(config.Updateable,"w","")}(A15:A10;A6) | ||
| 18 | if(oldZone!=0) | =movefile@y(config.DataPath/oldZone/"."/config.Filename) | |
| 19 | >config.Zones.d=(config.Zones.d\oldZone)|newZone | ||
| 20 | >config.LastTime=end | ||
| 21 | =file(long(now())/"_"/tbl/".json").write(json(config)) | ||
A1-A2: Read the configuration file.
A3: Last read time.
A4-C5: If the time difference between the given end time and the last read time is less than one day, or the given end time is later than the current time, it will abort and give a prompt “unreasonable end time”.
A6: Call the new data script, and read new data based on the time interval from last read time to the current given end time.
A7-A8: Calculate the new table number based on the current given end time.
A9-C13: If it is a multi-zone composite table and the highest layer is month, and the last existing table number and the current new table number are not in the same month, then enable the new table, and set the original table number to 0.
A15: New table file.
A16: Original table file.
A17: Merge the original table with new data and write the merged data to the new table.
A18-B18: Delete the original table.
A19: Update the list of table numbers.
A20: Update the last read time.
A21: Write the configuration information to file.
merge.splx
For update-type, use this script to merge the day/month tables updated before the given time into the main table. If the time parameter is empty, then merge the day/month tables updated before the last read time into the main table. This script can only be executed when the query service is stopped.
Input parameters:
tbl: table name
t: time. If this parameter is not empty, merge the tables updated before this time. Otherwise, merge the tables updated before the last read time.
Notes:
This script is executed in cold mode, and the merged tables will be deleted directly.
| A | |
| 1 | =directory("*_"+tbl+".json").sort(~:-1) |
| 2 | >config=json(file(A1(1)).read()) |
| 3 | =config.Zones.d |
| 4 | =if(t,t,datetime(config.LastTime)) |
| 5 | =year(A4)*10000+month(A4)*100+day(A4) |
| 6 | =A3.select(~< A5) |
| 7 | =file(config.DataPath/config.Filename:(0|A6)) |
| 8 | =file(config.DataPath/config.Filename:1) |
| 9 | =A7.reset@w(A8:config.BlockSize.d) |
| 10 | =movefile@y(config.DataPath/1/"."/config.Filename,0/"."/config.Filename) |
| 11 | =A6.(movefile@y(config.DataPath/~/"."/config.Filename)) |
| 12 | >config.Zones.d=config.Zones.d\A6 |
| 13 | =file(A1(1)).write(json(config)) |
A1: List all configuration files and sort them in reverse order.
A2: Read the first configuration file.
A3: The highest-layer table numbers.
A4: If the given time parameter is empty, use the last read end time.
A5: Calculate the table number corresponding to the highest layer based on A4.
A6: Select the highest-layer table number smaller than A5.
A7-A9: Merge table 0 and A6 table into temporary table 1.
A10: Rename table 1 to table 0 and overwrite it.
A11: Delete the merged tables.
A12: Delete the numbers of merged tables from the list.
A13: Write the configuration information back to file.
query.splx
For append-type, this script takes the time interval as input parameter to find out the tables that intersect with the time interval to form a multi-zone composite table object. For update-type, it doesn’t require a time parameter and will directly use all tables to form a multi-zone composite table object.
If hot data is required, take the last read end time and input parameter ‘end’ as input parameter to call the hot data script, and return a multi-zone composite table composed of tables and hot data. If hot data is not required, return a multi-zone composite table consisting of tables directly.
Input parameters:
tbl: table name
start: start time
end: end time
Return value:
A multi-zone composite table consisting of tables and hot data (if required).
| A | B | C | D | |
| 1 | =now() | |||
| 2 | =directory("*_"+tbl+".json").sort(~:-1) | |||
| 3 | =long(elapse@s(A1,-60)) | |||
| 4 | =A2.select@1(#>1 || long(left(~,13))< A3) | |||
| 5 | =long(left(A4,13)) | |||
| 6 | =lock(tbl+"Config") | |||
| 7 | if(!ifv(${tbl}QLastReadTime)|| A5>${tbl}QLastReadTime) | |||
| 8 | =env(${tbl}QConfig, json(file(A4).read())) | |||
| 9 | =env(${tbl}QLastReadTime,A5) | |||
| 10 | =lock@u(tbl+"Config") | |||
| 11 | =if(ifdate(${tbl}QConfig.LastTime),${tbl}QConfig.LastTime,datetime(${tbl}QConfig.LastTime)) | |||
| 12 | if(${tbl}QConfig.Updateable || !${tbl}QConfig.MultiZones) | |||
| 13 | >result=0|${tbl}QConfig.Zones.d| ${tbl}QConfig.Zones.H| ${tbl}QConfig.Zones.m | |||
| 14 | else | =zoneT(datetime(${tbl}QConfig.LastTime),"s") | ||
| 15 | >z=${tbl}QConfig.Zones.s|B14 | |||
| 16 | >sz=zoneT(start,"s") | |||
| 17 | >ez=zoneT(end,"s") | |||
| 18 | >sp = z.pselect@z(~< =sz) | |||
| 19 | >ep = ifn(z.pselect( ~>ez), z.len())-1 | |||
| 20 | =ifn(sp,1) | |||
| 21 | =if (sp >= z.len() || B20>ep,0,z.to(B20, ep)) | |||
| 22 | if(sp) | >result=B21 | ||
| 23 | else | =zoneZ(z(1),"m","s") | ||
| 24 | >z=${tbl}QConfig.Zones.H| ${tbl}QConfig.Zones.m|C23 | |||
| 25 | >sz=zoneT(start,"m") | |||
| 26 | >ez=zoneT(end,"m") | |||
| 27 | >sp = z.pselect@z(~< =sz) | |||
| 28 | >ep = ifn(z.pselect( ~>ez), z.len())-1 | |||
| 29 | =ifn(sp,1) | |||
| 30 | =if (sp >= z.len() || C29>ep,0,z.to(C29, ep)) | |||
| 31 | if(sp) | >result=C30&B21 | ||
| 32 | else | =zoneZ(z(1),"d") | ||
| 33 | >z=${tbl}QConfig.Zones.d|D32 | |||
| 34 | >sz=zoneT(start,"d") | |||
| 35 | >ez=zoneT(end,"d") | |||
| 36 | >sp = z.pselect@z(~< =sz) | |||
| 37 | >ep = ifn(z.pselect( ~>ez), z.len())-1 | |||
| 38 | =ifn(sp,1) | |||
| 39 | =if (sp >= z.len() || D38>ep,0,z.to(D38, ep)) | |||
| 40 | >result=D39&C30&B21 | |||
| 41 | =file(${tbl}QConfig.DataPath/${tbl}QConfig.Filename:result).open() | |||
| 42 | if(${tbl}QConfig.HotDataScript && end>A11) | |||
| 43 | =call(${tbl}QConfig.HotDataScript,tbl,A11,end) | |||
| 44 | =A41.append@y(B43) | |||
| 45 | return B44 | |||
| 46 | else | return A41 | ||
A2: List all configuration files and sort in the reverse order of their generation.
A3: Calculate the long value of the time one minute ago.
A4: Select the first file whose number is greater than 1 or that is generated before A3.
A5: The generation time of file A4.
A6: Read the lock of configuration file.
A7: If the last read time is empty, or a new configuration file that satisfies the read condition is generated, then:
B8: Read the configuration file and assign it to the global variable ${tbl}QConfig.
B9: Assign the read time to the global variable ${tbl}QLastReadTime.
A10: Unlock.
A11: Last read end time.
A12-B13: If it is update-type or single composite table, concatenate all table numbers into a sequence by time and assign it to ‘result’.
A14: If it is append-type and multi-zone composite table, then:
B14: Second-layer table number corresponding to the end time of last data reading.
B15: First add B14 to the end of second-layer table number.
B16-B17: Calculate the second-layer table numbers corresponding to query’s start and end time.
B18: Find the position of the first table number that is less than or equal to the query start time from back to front.
B19: Find the position of first table number that is greater than the query end time from front to back and subtract 1.
B20: If the query start time is earlier than the first table number, assign 1 to the start position.
B21: Select the list of table numbers that intersect with the time interval of query. For the table that does not intersect with the interval, fill 0.
B22-C22: If the query start time is later than the first table number, assign B21 to ‘result’ directly.
B23: Otherwise:
C23: Calculate the corresponding minute-layer table number based on second-layer’s first table number.
C24: First concatenate the hour- and minute-layer table numbers into a sequence by time, and add C23 to the end of the sequence.
C25-C26: Calculate the minute-layer table numbers corresponding to the query start and end time.
C27: Find the position of the first table number that is less than or equal to the query start time from back to front.
C28: Find the position of first table number that is greater than the query end time from front to back and subtract 1.
C29: If the query start time is earlier than the first table number, assign 1 to the start position.
C30: Select the list of table numbers that intersect with the time interval of query. For the table that does not intersect with the interval, fill 0.
C31-D31: If the query start time is later than the first table number, assign C30&B21 to ‘result’ directly.
C32: Otherwise:
D32: Calculate the corresponding day-layer table numbers based on hour- and minute-layer’s first table number.
D33: Read the day-layer table numbers and add D32 to the end.
D34-D35: Calculate the day-layer table numbers corresponding to the query start and end time.
D36: Find the position of the first table number that is less than or equal to the query start time from back to front.
D37: Find the position of first table number that is greater than the query end time from front to back and subtract 1.
D38: If the query start time is earlier than the first table number, assign 1 to the start position.
D39: Select the list of table numbers that intersect with the time interval of query. For the table that does not intersect with the interval, fill 0.
D40: Assign D39&C30&B21 to ‘result’.
A41: Generate a multi-zone composite table based on ‘result’ and open the table.
A42: If hot data is required, and ‘end’ is greater than the end time of last data reading, then:
B43. Take the end time of last data reading and the end as input parameter to call the hot data script to obtain hot data.
B44: Merge the hot data with A41 to generate a multi-zone composite table.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version