

1.2 Structured data
Constant data table
SPL
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | Rebecca | Male | 80 | 1.75 | 1974-11-20 |
| 2 | Ashley | Male | 60 | 1.68 | 1980-07-19 |
| 3 | Rachel | Female | 51 | 1.64 | 1970-12-17 |
| 4 | Emily | Female | 49 | 1.6 | 1985-03-07 |
| 5 | =create(name,gender,weight,height,birthday) | ||||
| 6 | =A5.record([A1:E4]) | ||||
SQL
CREATE TABLE emp (
name VARCHAR2(50),
gender VARCHAR2(10),
weight NUMBER(5,2),
height NUMBER(5,2),
birthday DATE);
INSERT INTO emp (name, gender, weight, height, birthday) VALUES ('Rebecca', 'Male', 80, 1.75,
TO_DATE('1974-11-20', 'YYYY-MM-DD'));
INSERT INTO emp (name, gender, weight, height, birthday) VALUES ('Ashley', 'Male', 60, 1.68,
TO_DATE('1980-07-19', 'YYYY-MM-DD'));
INSERT INTO emp (name, gender, weight, height, birthday) VALUES ('Rachel', 'Female', 51, 1.64,
TO_DATE('1970-12-17', 'YYYY-MM-DD'));
INSERT INTO emp (name, gender, weight, height, birthday) VALUES ('Emily', 'Female', 49, 1.6,
TO_DATE('1985-03-07', 'YYYY-MM-DD'));
Python
info = [["Rebecca","Male",80,1.75,"1974-11-20"],
["Ashley","Male",60,1.68,"1980-07-19"],
["Rachel","Female",51,1.64,"1970-12-17"],
["Emily","Female",49,1.6,"1985-03-07"]]
data = pd.DataFrame(info,columns=['name','gender','weight','height','birthday'])
1.2.2 Retrieve members
SPL
| A | |
|---|---|
| 1 | =file(“EMPLOYEE.csv”).import@tc() |
| 2 | =A1(3) |
| 3 | =A1([2,6,5]) |
| 4 | =A1.to(2,4) |
| 5 | =A1.step(2,2) |
| 6 | =A1.m(-1) |
| 7 | =A1.m([1,3],5:7,-2) |
SQL
1. Take the 3rd member
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE rnum = 3;
2. Take the 2nd, 6th, and 5th members
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE rnum IN (2,5,6)
ORDER BY CASE rnum WHEN 2 THEN 1 WHEN 6 THEN 2 WHEN 5 THEN 3 END;
3. Take the 2nd to 4th members
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE rnum BETWEEN 2 AND 4;
4. Take even-positioned members
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE MOD(rnum,2)=0;
5. Take the last member
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE rnum=( SELECT COUNT(*)
FROM EMPLOYEE);
6. Take the 1st and 3rd members, the 5th to 7th members, and the second-to-last member.
SELECT * FROM (
SELECT EMPLOYEE.*, ROWNUM AS rnum
FROM EMPLOYEE)
WHERE (rnum IN (1,3)) OR (rnum BETWEEN 5 AND 7) OR (rnum=(
SELECT COUNT(*)-1
FROM EMPLOYEE));
Python
emp = pd.read_csv('EMPLOYEE.csv')
result1 = emp.iloc[2]
result2 = emp.iloc[[1, 5, 4]]
result3 = emp.iloc[1:4]
result4 = emp.iloc[1::2]
result5 = emp.iloc[-1]
result6 = emp.iloc[[0, 2, *range(4, 7), -2]]
1.2.3 Field reference
1. Extract field by record
2. Extract multiple fields
3. Extract field by dynamic field name
4. Extract field by position
5. Extract all fields
6. Extract field by the set of records
SPL
| A | |
|---|---|
| 1 | =file(“EMPLOYEE.csv”).import@tc() |
| 2 | =A1(1) |
| 3 | =A2.NAME |
| 4 | =A2.([NAME,GENDER]) |
| 5 | =A2.field(“NAME”) |
| 6 | =A2.([#2,#3]) |
| 7 | =A2.array() |
| 8 | =A1.(NAME) |
SQL
Although SQL has the concept of record, record cannot exist independently and can only exist as a new table with only one record. Therefore, SQL cannot extract field by record.
Python
emp = pd.read_csv('EMPLOYEE.csv')
emp1 = emp.iloc[0]
result1 = emp1.NAME
result2 = emp1[['NAME', 'GENDER']].values
result3 = emp1['NAME']
result4 = emp1.iloc[[1,2]].values
result5 = emp1.values
result6 = emp.NAME
1.2.4 Comparison of records
1. Compare pointers by records in different data tables.
2. Compare values by records in different data tables.
SPL
| A | B | |
|---|---|---|
| 1 | =file(“EMPLOYEE.csv”).import@tc(EID,NAME,SALARY) | |
| 2 | =file(“EMPLOYEE.csv”).import@tc(EID,NAME,SALARY) | |
| 3 | =file(“EMPLOYEE.csv”).import@tc(EID,NAME) | |
| 4 | =A1(1)==A2(1) | /false |
| 5 | =cmp(A1(1),A2(1)) | /0 |
| 6 | =cmp(A1(1),A2(2)) | /-1 |
| 7 | =cmp(A1(1),A3(1)) | /1 |
A4: Compare pointers by records in different table sequences.
A5-A7: Compare values by records in different table sequences.
SQL
SQL does not support direct comparison by record.
Python
Pandas does not support direct comparison by record; it needs to convert records to list before comparing.
1.2.5 Set operations
1. Intersection
2. Difference
3. Union
4. Union All
SPL
| A | B | |
|---|---|---|
| 1 | =file(“EMPLOYEE.csv”).import@tc() | |
| 2 | =A1.select(GENDER==“F”) | |
| 3 | =A1.select(DEPT==“Sales”) | |
| 4 | =A2^A3 | =[A2,A3].isect() |
| 5 | =A2\A3 | =[A2,A3].diff() |
| 6 | =A2&;A3 | =[A2,A3].union() |
| 7 | =A2|A3 | =[A2,A3].conj() |
SQL
1. Intersection
SELECT * FROM EMPLOYEE
WHERE GENDER = 'F'
INTERSECT
SELECT * FROM EMPLOYEE
WHERE DEPT = 'Sales';
2. Difference
SELECT * FROM EMPLOYEE
WHERE GENDER = 'F'
MINUS
SELECT * FROM EMPLOYEE
WHERE DEPT = 'Sales';
3. Union
SELECT * FROM EMPLOYEE
WHERE GENDER = 'F'
UNION
SELECT * FROM EMPLOYEE
WHERE DEPT = 'Sales';
4. Union All
SELECT * FROM EMPLOYEE
WHERE GENDER = 'F'
UNION ALL
SELECT * FROM EMPLOYEE
WHERE DEPT = 'Sales';
Python
Pandas does not have the data type ‘set’ composed of records.
1.2.6 Generic data table
1) The field value is set
SPL
| A | B | C | |
|---|---|---|---|
| 1 | 1 | 91993.67 | [82] |
| 2 | 2 | 96754.54 | [88,12] |
| 3 | 3 | 28409.55 | [73,71] |
| 4 | 4 | 32972.12 | [29,82] |
| 5 | 5 | 51869.75 | [60,1] |
| 6 | =create(order_id,order_price,part_no) | ||
| 7 | =A6.record([A1:C5]) | ||
| 8 | =A6(2).part_no(1) | /88 |
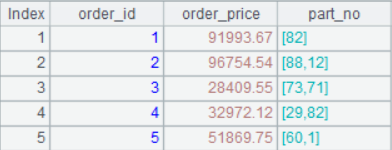
The above table can be regarded as a part of the order table, including the order number, the order price, and the part number under the order.
Result of A7:
SQL
CREATE OR REPLACE TYPE NUMBER_LIST_TYPE AS VARRAY(5) OF NUMBER;
--This type has been created before, so it can be omitted here.
CREATE TABLE order_gen (ORDER_ID NUMBER,ORDER_PRICE NUMBER,PART_NO NUMBER_LIST_TYPE);
INSERT ALL
INTO order_gen (ORDER_ID,ORDER_PRICE,PART_NO) VALUES (1,91993.67,number_list_type (82))
INTO order_gen (ORDER_ID,ORDER_PRICE,PART_NO) VALUES (2,96754.54,number_list_type (88,12))
INTO order_gen (ORDER_ID,ORDER_PRICE,PART_NO) VALUES (3,28409.55,number_list_type (73,71))
INTO order_gen (ORDER_ID,ORDER_PRICE,PART_NO) VALUES (4,32972.12,number_list_type (29,82))
INTO order_gen (ORDER_ID,ORDER_PRICE,PART_NO) VALUES (5,51869.75,number_list_type (60,1))
SELECT * FROM dual;
SELECT COLUMN_VALUE FROM TABLE(
SELECT PART_NO FROM (
SELECT PART_NO, ROWNUM AS rnum FROM order_gen)
WHERE rnum = 2)
WHERE ROWNUM = 1;
The results of the table order_gen are as follows:
ORDER_ID ORDER_PRICE PART_NO
-----------------------------------------------------------------------
1 91993.67 NUMBER_LIST_TYPE(82)
2 96754.54 NUMBER_LIST_TYPE(88, 12)
3 28409.55 NUMBER_LIST_TYPE(73, 71)
4 32972.12 NUMBER_LIST_TYPE(29, 82)
5 51869.75 NUMBER_LIST_TYPE(60, 1)
Python
info = [[1,91993.67,[82]],
[2,96754.54,[88,12]],
[3,28409.55,[73,71]],
[4,32972.12,[29,82]],
[5,51869.75,[60,1]]]
data = pd.DataFrame(info,columns=['order_id','order_price','part_no'])
data_list1 = data.iloc[1].part_no[0] #88
Results of data:
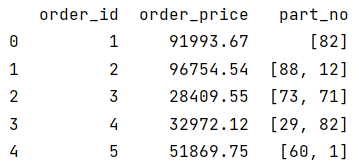
2) The field value is record
SPL
| A | |
|---|---|
| 1 | [{“order_id”:1,“part_no”:[47,10],“cust_info”:{“cust_id”:10001,“gender”:“M”,“age”:31}},{“order_id”:2,“part_no”:[46,30,23],“cust_info”:{“cust_id”:10005,“gender”:“F”,“age”:35}},{“order_id”:3,“part_no”:[94,91,91],“cust_info”:{“cust_id”:10005,“gender”:“F”,“age”:35}},{“order_id”:4,“part_no”:[19,62],“cust_info”:{“cust_id”:10002,“gender”:“F”,“age”:28}},{“order_id”:5,“part_no”:[9,68],“cust_info”:{“cust_id”:10005,“gender”:“F”,“age”:35}},{“order_id”:6,“part_no”:[67,20,12],“cust_info”:{“cust_id”:10005,“gender”:“F”,“age”:35}},{“order_id”:7,“part_no”:[74],“cust_info”:{“cust_id”:10001,“gender”:“M”,“age”:31}},{“order_id”:8,“part_no”:[34],“cust_info”:{“cust_id”:10002,“gender”:“F”,“age”:28}},{“order_id”:9,“part_no”:[49],“cust_info”:{“cust_id”:10003,“gender”:“M”,“age”:30}},{“order_id”:10,“part_no”:[99,43,63],“cust_info”:{“cust_id”:10005,“gender”:“F”,“age”:35}}] |
| 2 | =A1(2).cust_info |
| 3 | =A2.gender |
SPL supports recognizing the data of json format as table sequence. The result of A1 is as follows:
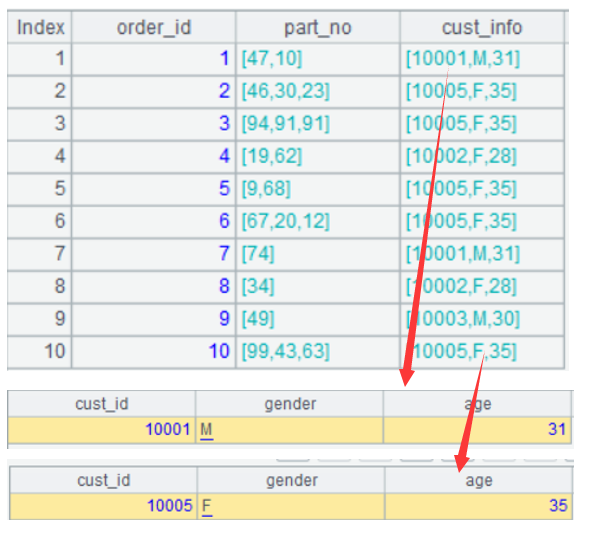
A2 is a record:

A3 is to retrieve the gender field of cust_info.

SQL
It is difficult for SQL to generate a table with record directly based on the JSON string.
Python
data=[
{"order_id":1,"part_no":[47,10],"cust_info":{"cust_id":10001,"gender":"M","age":31}},
{"order_id":2,"part_no":[46,30,23],"cust_info":{"cust_id":10005,"gender":"F","age":35}},
{"order_id":3,"part_no":[94,91,91],"cust_info":{"cust_id":10005,"gender":"F","age":35}},
{"order_id":4,"part_no":[19,62],"cust_info":{"cust_id":10002,"gender":"F","age":28}},
{"order_id":5,"part_no":[9,68],"cust_info":{"cust_id":10005,"gender":"F","age":35}},
{"order_id":6,"part_no":[67,20,12],"cust_info":{"cust_id":10005,"gender":"F","age":35}},
{"order_id":7,"part_no":[74],"cust_info":{"cust_id":10001,"gender":"M","age":31}},
{"order_id":8,"part_no":[34],"cust_info":{"cust_id":10002,"gender":"F","age":28}},
{"order_id":9,"part_no":[49],"cust_info":{"cust_id":10003,"gender":"M","age":30}},
{"order_id":10,"part_no":[99,43,63],"cust_info":{"cust_id":10005,"gender":"F","age":35}}
]
df=pd.DataFrame(data)
cust_info_rec=df.iloc[1].cust_info #{'cust_id':10005,'gender':'F','age':35}
rec_gender=cust_info_rec['gender'] #F
Python regards cust_info as a dictionary to generate DataFrame, df results:
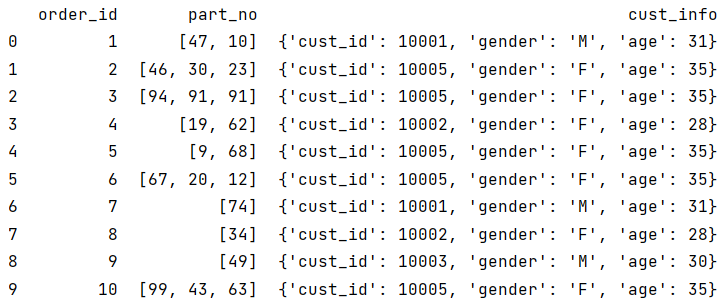
IntheDataFrame,eachrowisactuallyaSeries.However,thedataformatofcust_infohereisjustadictionary,notaSeries.Therefore,itcanonlyusedictionaryrulestoretrievegender,thatis,rec_gender=cust_info_rec[‘gender’],insteadofusingtheSeriesmethodtoretrivedata,suchascust_info_rec.gender.
3) The field value is a table sequence
There is a json file as shown below. Now we want to read the file as table:
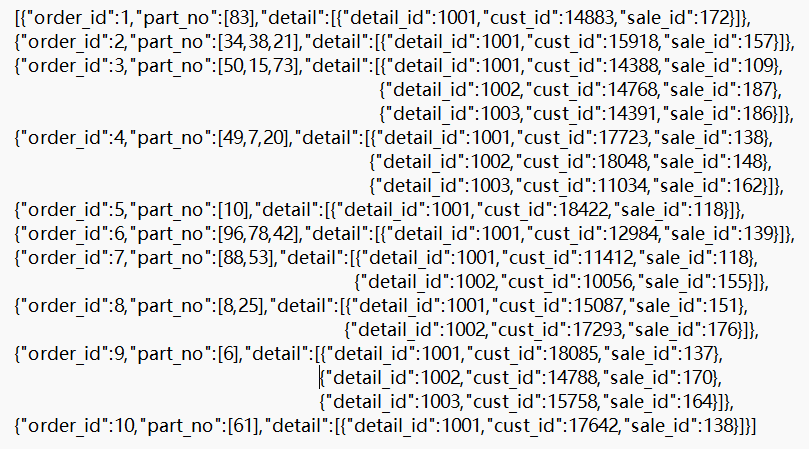
SPL
| A | |
|---|---|
| 1 | =file(“table_data.txt”).read() |
| 2 | =json(A1) |
| 3 | =A2(3).detail |
| 4 | =A3(2) |
| 5 | =A4.cust_id |
A1: Read the json file.
A2: Convert the json string to a table sequence:
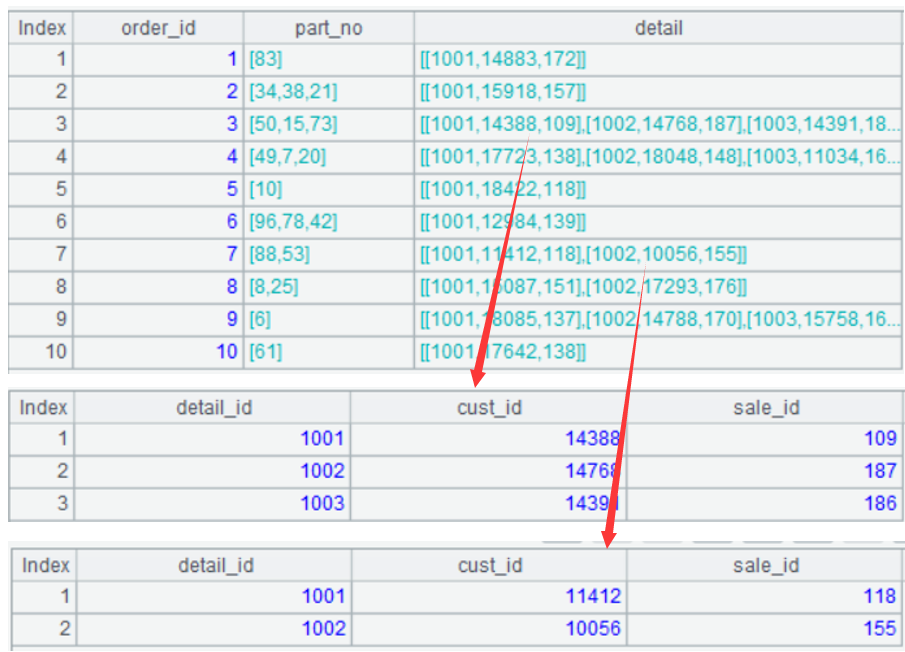
A3: detail information of the third record:

A4: The second record in the detail information of the third record.

A5: The cust_id field of the second record in the detail information of the third record.
SQL
It is difficult for SQL to generate a table with sub table directly from the json file.
Python
df=pd.read_json('table_data.txt')
detail_info_table=df.loc[2].detail #detailinformationofthethirdrecord
detail_2=detail_info_table[1] #Thesecondrecordinthedetailinformationofthethirdrecord
detail_2_cust_id=detail_2['cust_id'] #Thecust_idfieldofthesecondrecordinthedetailinformationofthethirdrecord
Python reads detail as a list of dictionaries, and the df result is as follows:
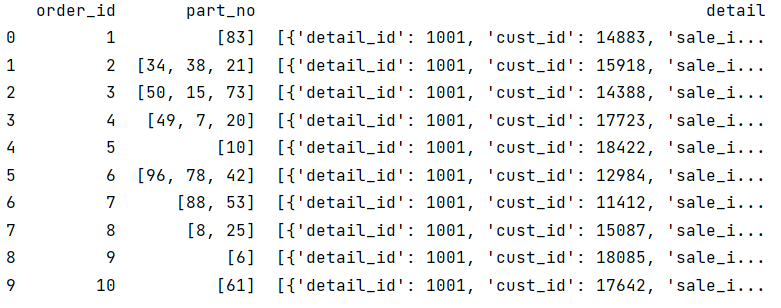
detail_info_table: detail information of the third record:
[{'detail_id': 1001, 'cust_id': 14388, 'sale_id': 109},
{'detail_id': 1002, 'cust_id': 14768, 'sale_id': 187},
{'detail_id': 1003, 'cust_id': 14391, 'sale_id': 186}]
detail_2: The secord record in detail_info_table:
{'detail_id': 1002, 'cust_id': 14768, 'sale_id': 187}
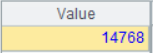
detail_2_cust_id is the cust_id in detail_2.
14768
Similar to the previous example, detail_info_table is a list of dictionaries, not the data structure DataFrame. Therefore, when retrieving the second piece of information from detail_info_table, it can only use the list’s retriving method detail_info_table[1], instead of retriving with detail_info_table.loc[1]. The result detail_2 is a dictionary, not a Series. So, when retrieving the cust_id from detail_2, we can only use dictionary’s retriving method detail_2[‘cust_id’], instead of detail_2.info.
1.2.7 Generic record sequence
The structures of the employee table and the family member table are different, but both have a GENDER field. Now we want to count the number of females in these two tables.
SPL
| A | |
|---|---|
| 1 | =file(“EMPLOYEE.csv”).import@tc() |
| 2 | =file(“FAMILY.csv”).import@tc() |
| 3 | =A1|A2 |
| 4 | =A3.count(left(GENDER,1)==“F”) |
SPL allows records from different table sequences to form a new set, such as A3, and can also perform calculation on the new set.
The result of A3 is a set of records, each member of which is a record:
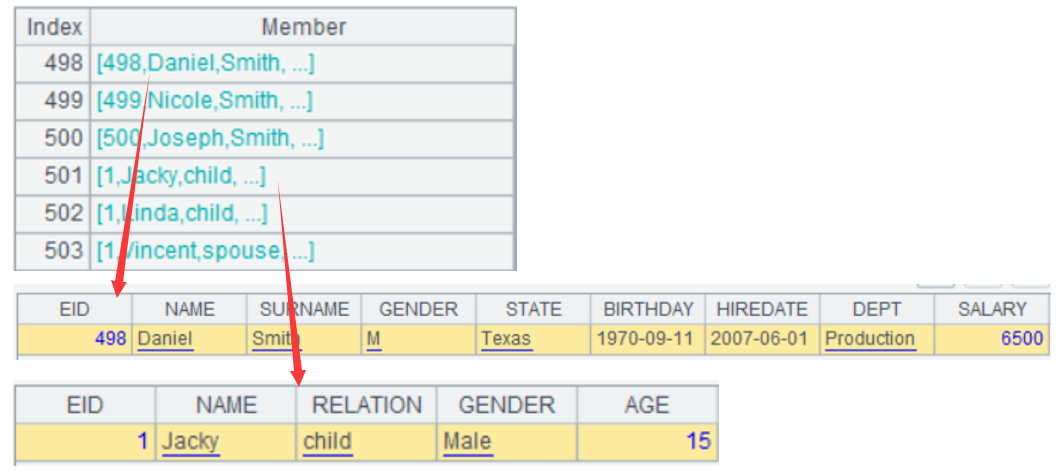
SQL
SQL forbids to union two tables with different structures directly.
Python
emp = pd.read_csv("EMPLOYEE.csv")
fam = pd.read_csv("FAMILY.csv")
df = pd.concat([emp,fam])
cnt = len(df[df['GENDER'].str[0]=='F'])
Python does not support simple union of DataFrames with different structures. When unioning, the data structures of the two tables need to be converted to same structure.
df results:
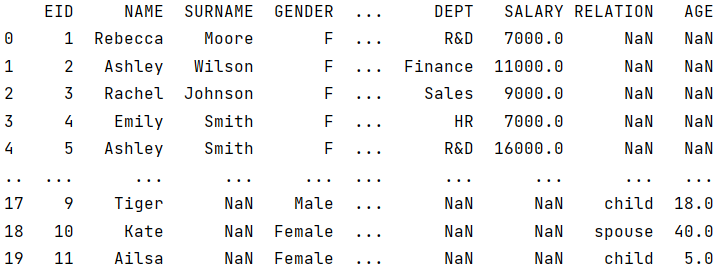
2.1 Current value reference
Example codes for comparing SPL, SQL, and Python
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

