

8.3 Mixed association
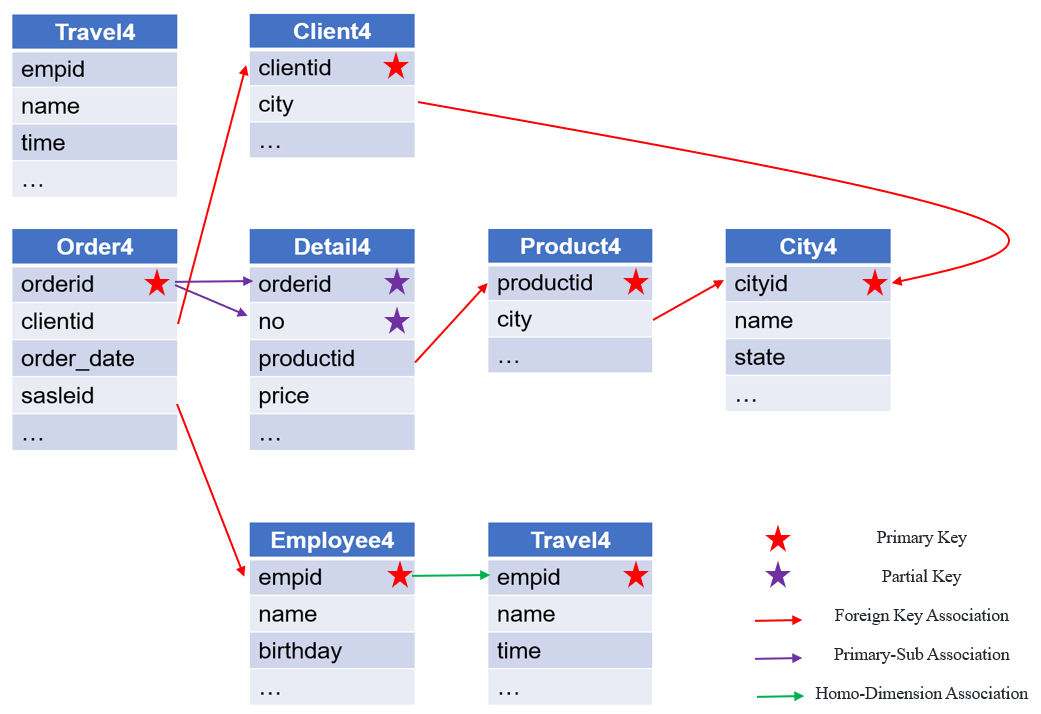
Based on the order table, order detail table, product information table, employee information table, travel information table, client information table, and city information table, calculate the sales of California products sold in each state by post-90s sales representative who travels for more than 10 days.
The associative relations are shown below:
SPL
| A | |
|---|---|
| 1 | =file(“Employee4.csv”).import@tc() |
| 2 | =file(“Travel4.csv”).import@tc() |
| 3 | =A2.join(empid,A1:empid,birthday) |
| 4 | =A3.select((y=year(birthday),y>=1990&&y<2000&&time>=10)) |
| 5 | =file(“Client4.csv”).import@tc() |
| 6 | =file(“City4.csv”).import@tc() |
| 7 | =A5.join(city,A6:cityid,state) |
| 8 | =file(“Product4.csv”).import@tc() |
| 9 | =A8.join(city,A6:cityid,state) |
| 10 | =file(“Detail4.csv”).import@tc() |
| 11 | =file(“Order4.csv”).import@tc() |
| 12 | =A10.join(productid, A9:productid,state:product_state) |
| 13 | =A12.group(orderid) |
| 14 | =A11.switch(orderid, A13:orderid;saleid, A4:empid;clientid, A7:clientid) |
| 15 | =A14.select(saleid).new(saleid.empid:empid,saleid.name:sale_name,clientid.state:sale_location,orderid.select(product_state==“California”).sum(price):price) |
| 16 | =A15.groups(empid,sale_name,sale_location;sum(price):price).select(price) |
When facing such complex association relations, SPL can handle easily as its homo-dimension, primary-sub and foreign key associations are all very clear. SPL can also associate two associations simultaneously.
SQL
SELECT e.empid,e.name,c2.state,sum(d.price) AS total_amount
FROM Order4 o
JOIN Employee4 e ON o.saleid=e.empid
JOIN Travel4 t ON e.empid = t.empid
JOIN Detail4 d ON o.orderid = d.orderid
JOIN Product4 p ON d.productid = p.productid
JOIN City4 c ON p.city = c.cityid
JOIN Client4 cl ON o.clientid = cl.clientid
JOIN City4 c2 ON cl.city = c2.cityid
WHERE e.birthday >= TO_DATE('1990-01-01', 'YYYY-MM-DD')
AND e.birthday < TO_DATE('2000-01-01', 'YYYY-MM-DD')
AND t.time >= 10
AND c.state = 'California'
GROUP BY e.empid,e.name,c2.state;
Python
emp4 = pd.read_csv("../Employee4.csv")
trv4 = pd.read_csv("../Travel4.csv")
emp_inf = pd.merge(emp4,trv4,on=["empid","name"])
years = pd.to_datetime(emp_inf.birthday).dt.year
emp_inf_c = emp_inf[(years>=1990) & (years<2000)&(emp_inf.time>=10)]
clt4 = pd.read_csv("../Client4.csv")
city4 = pd.read_csv("../City4.csv")
sale_location = pd.merge(clt4,city4,left_on='city',right_on='cityid')
pdt4 = pd.read_csv("../Product4.csv")
pdt_location = pd.merge(pdt4,city4,left_on='city',right_on='cityid')
detail4 = pd.read_csv("../Detail4.csv")
order4 = pd.read_csv("../Order4.csv")
detail_pdt = pd.merge(detail4,pdt_location,on='productid',how="left")
order_sale_location = pd.merge(order4,sale_location,on='clientid',how="left")
order_sale_location_emp = pd.merge(order_sale_location,emp_inf_c,
left_on='saleid',right_on='empid',how="left",suffixes=('_c', '_e'))
order_inf = order_sale_location_emp[order_sale_location_emp.empid.notnull()]
order_detail = pd.merge(order_inf,detail_pdt,on='orderid',how="left",suffixes=('_s', '_p'))
order_detail_Hljp = order_detail[order_detail.state_p=="California"]
res = order_detail_Hljp.groupby(['empid','name_e','state_s'],as_index=False).price.sum()
When the association relations are too complex, it is best for Python to handle one association at a time to avoid error.
What to use for data analysis programming, SQL, Python, or esProc SPL?
Example codes for comparing SPL, SQL, and Python
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

