

SPL Reporting: Lightweight, Low-Cost, Realtime Hot Data Reporting Solution
Realtime hot data reports are reports that can query all data, including both hot and cold, in real-time. In earlier times when businesses are based on one single TP database, there isn’t too much difficulty in generating such reports. But as data gets accumulated and needs to be split to special AP databases, things become different. After separation of cold data and hot data, developing a real-time report based on all data involves multi-database mixed computations. Moreover, the AP database and the TP database are different in type, and this further complicates the reporting.
The HTAP database combines TP and AP to achieve the earlier single-database architecture in order to avoid the cross-database mixed computation. However, migrating data to a new HTAP database poses high risks and involves high costs, and it may not be able to replicate the capabilities of the original TP database and AP database.
Using a logical data warehouse engine such as Trino or a stream processing engine such as Flink and Kafka, which is responsible for data transmission, can to some extent achieve real-time synchronization and mixed-source computations. The framework, however, is heavy and complicated, involving metadata management and the other cumbersome tasks. The code of performing stream computing isn’t concise enough, and real-time synchronization is highly resource-consuming. As a result, the construction and application costs are both very high.
SPL solution
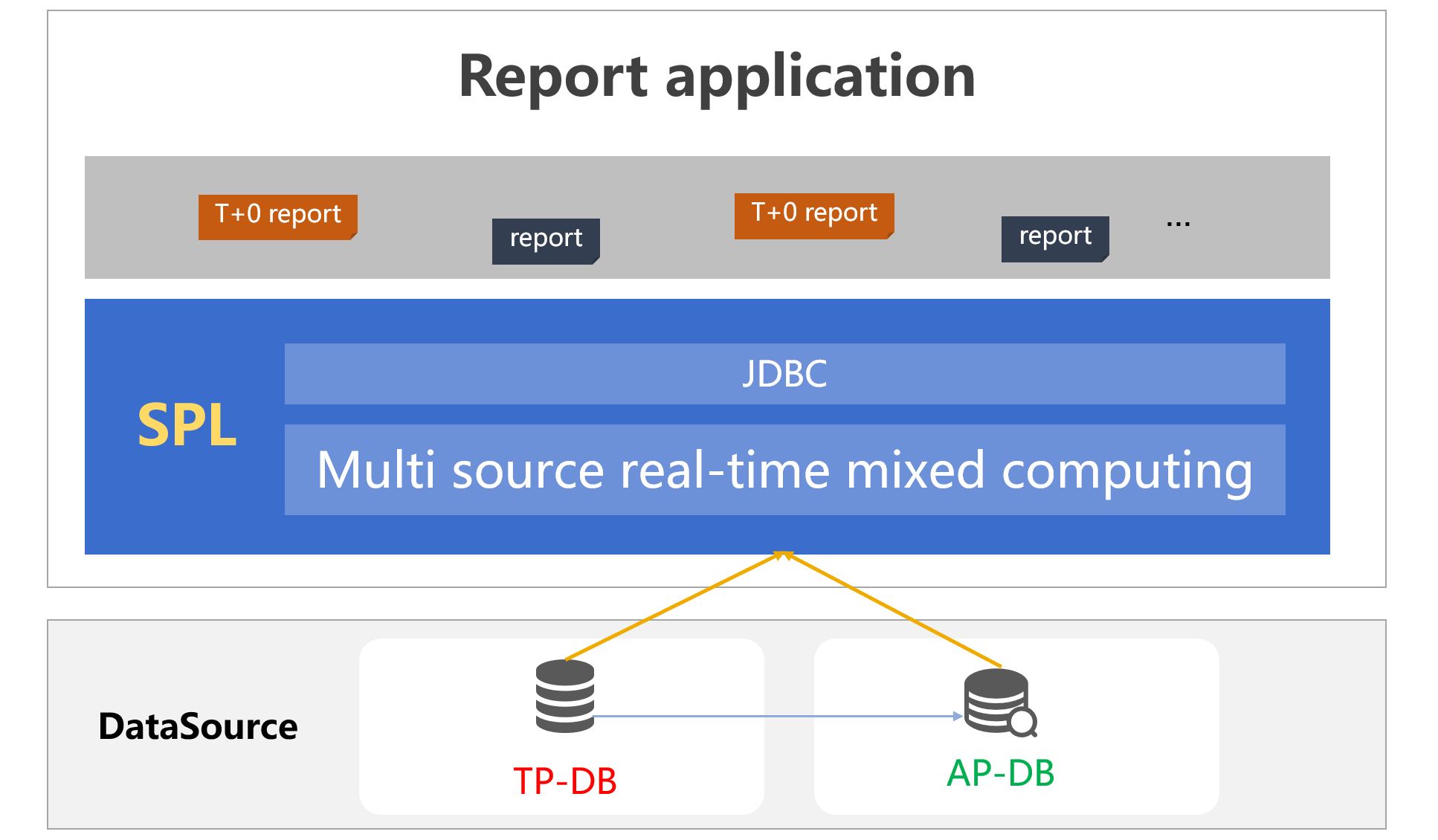
SPL connects to the TP source and AP source via its native DataSource interface. Data in each of the two sources is processed separately and transmitted to SPL to be mixed together and computed, and results are passed to the report in real-time.
SPL has intrinsic mixed-source computing ability. It can directly access and retrieve data from any sources, ranging from AP databases to streaming mechanism such as Kafka, to various data warehouses and big data platforms, and to files and cloud object storages, and perform the mixed-source computation.
Find more about mixed-source computing in SPL Reporting: Make Lightweight, Mixed-Source Reports without Logical Data Warehouse.
SPL is very lightweight. There is almost no need to modify the original framework. This means the computation does not involve database migration and complicated framework changes. To enjoy the convenience of real-time query service, we just need to integrate SPL into the reporting application (seamlessly).
Moreover, SPL’s retrieving hot data from the TP database before performing the mixed-source computation is an ad hoc action. This framework does not require high realtimeness in dumping data into the AP database. We can first collate the data before synchronize them to the AP database in order to achieve better computing performance for the AP database.
Without further ado, let’s look at some examples where T+0 computations are implemented in SPL.
Examples
1. Business scenario
An ecommerce platform wants to monitor customer purchase actions in real-time and build a real-time product sales conversion rate report to help adjust the marketing strategy. The report should display the following indicators:
Each product’s views, purchase volume and conversion rate (purchase volume/views) per hour.
Real-time total sales for each product.
2. Target report
Generate a report updated in real-time, whose content is as follows:
PID |
Views |
PurVOL |
CnvRT(%) |
TSales(¥) |
P001 |
500 |
100 |
20 |
15,000 |
P002 |
300 |
50 |
16.67 |
7,500 |
Views and Purchase volume: Obtained by summing up the real-time user clickstream data and the real-time order data respectively.
Total sales: Obtained from computing the real-time order data and historical order data.
Conversion rate: Obtained from computing the ratio of purchase volume to views in real-time.
3. Source of data
TP database (order data): It stores the latest order data; supports transaction operations and real-time writes.
Kafka stream data: Record the real-time customer action data (such as product view, add to cart and pay actions).
Hadoop storage (historical order data): It stores historical order data in the ORC format.
(1) TP database - orders table (the latest order data)
order_id |
user_id |
product_id |
quantity |
total_price |
order_time |
1001 |
2001 |
3001 |
2 |
400.00 |
2024-12-19 10:15:00 |
1002 |
2002 |
3002 |
1 |
150.00 |
2024-12-19 10:20:00 |
1003 |
2001 |
3003 |
3 |
600.00 |
2024-12-19 10:25:00 |
(2) Kafka stream data – customer action data (in the past hour)
product_id |
views |
P001 |
500 |
P002 |
300 |
(3) Hadoop storage - his_orders table (historical order data)
order_id |
user_id |
product_id |
quantity |
total_price |
order_time |
1001 |
2001 |
3001 |
2 |
400.00 |
2023-12-01 12:10:00 |
1002 |
2002 |
3002 |
1 |
150.00 |
2023-12-01 14:00:00 |
1003 |
2001 |
3003 |
3 |
600.00 |
2023-12-01 16:30:00 |
4. Write the script
Write SPL script realTimeOrder.splx (read the historical script from Hive):
A |
||
1 |
=connect("mysqlDB") |
|
2 |
=A1.query@x("SELECT product_id, SUM(quantity) AS total_sales, SUM(total_price) AS total_revenue FROM orders WHERE order_time > now()-1h GROUP BY product_id") |
/Real-time order data |
3 |
=kafka_open("/kafka/order.properties", "topic_order") |
|
4 |
=kafka_poll(A3).value |
/Real-time customer action data |
5 |
=kafka_close(A3) |
|
6 |
=hive_open("hdfs://192.168.0.76:9000", "thrift://192.168.0.76:9083","default","hive") |
/Connect to Hive |
7 |
=hive_table@o(A6) |
/ Get the ORC table and file |
8 |
>hive_close(A6) |
|
9 |
=A7.select(tableName=="his_orders") |
|
10 |
=file(A9.location).hdfs_import@c() |
/Historical order data |
11 |
=A10.select(interval(order_time,now())<=730) |
|
12 |
=A11.groups(product_id;SUM(total_price):historical_revenue) |
|
13 |
=join(A2:o,product_id;A4:v,product_id;A12:ho,product_id) |
/Join the three parts of data |
14 |
=A13.new(o.product_id:product_id,v.views:views,o.total_sales/v.views:conversion_rate,o.total_revenue+ho.historical_revenue:total_revenue) |
|
15 |
return A14 |
The historical data can also be directly read from the HDFS, and the script will be like this:
A |
||
1 |
=connect("mysqlDB") |
/TP source |
2 |
=A1.query@x("SELECT product_id, SUM(quantity) AS total_sales, SUM(total_price) AS total_revenue FROM orders WHERE order_time > now()-1h GROUP BY product_id") |
/Real-time order data |
3 |
=kafka_open("/kafka/order.properties", "topic_order") |
/Kafka |
4 |
=kafka_poll(A3).value |
/Real-time customer action data |
5 |
=kafka_close(A3) |
|
6 |
=file("hdfs://localhost:9000/user/86186/orders.orc") |
/Access HDFS directly |
7 |
=A6.hdfs_import@c() |
/Historical order data |
8 |
=A7.select(interval(order_time,now())<=730) |
|
9 |
=A8.groups(product_id;SUM(total_price):historical_revenue) |
|
10 |
=join(A2:o,product_id;A4:v,product_id;A9:ho,product_id) |
/Join the three parts of data |
11 |
=A10.new(o.product_id:product_id,v.views:views,o.total_sales/v.views:conversion_rate,o.total_revenue+ho.historical_revenue:total_revenue) |
|
12 |
return A11 |
The script is clear and concise.
5. Integrate SPL script into the reporting application
It is simple to integrate the SPL script into the reporting application. Just need to import two SPL jar files – esproc-bin-xxxx.jar and icu4j-60.3.jar (generally located in [installation directory]\esProc\lib) to the application, and then copy raqsoftConfig.xml (located in the same directory) to the application’s class path.
raqsoftConfig.xml is SPL’s core configuration file. Its name must not be changed.
Configure the external library in raqsoftConfig.xml. To use Kafka:
<importLibs>
<lib>KafkaCli</lib>
</importLibs>
MySQL source also needs to be configured. Configure the connection information under DB node:
<DB name="mysqlDB">
<property name="url" value="jdbc:mysql://192.168.2.105:3306/raqdb?useCursorFetch=true"/>
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="type" value="10"/>
<property name="user" value="root"/>
<property name="password" value="root"/>
…
</DB>
SPL encapsulates the standard JDBC interface. The report can access SPL by configuring the JDBC data source. For example, the configurations of report data sources are as follows:
<Context>
<Resource name="jdbc/esproc"
auth="Container"
type="javax.sql.DataSource"
maxTotal="100"
maxIdle="30"
maxWaitMillis="10000"
username=""
password=" "
driverClassName=" com.esproc.jdbc.InternalDriver "
url=" jdbc:esproc:local:// "/>
</Context>
The standard JDBC call is the same as that for an ordinary database, so we will not elaborate further.
Then call the SPL script from the report data set in the way of calling the stored procedure to get SPL’s computing result.
Call the order data computation script realTimeOrder.splx:
call realTimeOrder()
To output the final result set to the report.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version