

Count the occurrence rate of words
In a formal document, words are separated by spaces, commas, periods, or carriage returns, and the "-" symbol indicates that the characters before and after the carriage return are connected as one word.
There is currently a document MobyDick.txt that meets the above characteristics. Please find out how many different words have appeared in it, the frequency of each word, and identify the word with the highest frequency of occurrence.
Read the document content and break it down into word sequences. Count the number of times each word appears, and the word with the highest number of times is the word with the highest frequency of occurrence.
A |
|
1 |
MobyDick.txt |
2 |
=file(A1).read() |
3 |
=A2.words() |
4 |
=A3.groups(~:Word;count(~):Count) |
5 |
=A4.len() |
6 |
=A4.maxp(Count) |
http://try.scudata.com.cn/try.jsp?splx=ExA006tjdcdcxl1.splx
A2 uses f.read()to read strings from a text file. In SPL, you can use s.words() to break down strings into words, as shown in A3 where the result is as follows:
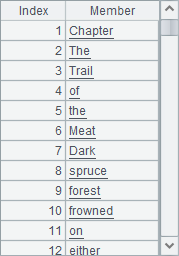
A4 groups the word sequence by different word and calculates the number of times each word appears. The result is as follows:
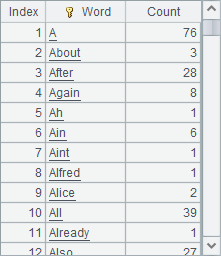
The use of groups in SPL makes it easy to perform grouping statistical calculations, and the results are sorted in ascending order of grouping values. Different capitalization here is considered as different words. If we do not consider capitalization, we can modify the code in A4 to =A3.groups(lower(~):Word;count(~):Count), i.e. convert all words to lowercase before counting.
A5 uses len to obtain the total number of different words:

A6 uses maxp to find which word has the highest frequency of occurrence and its usage frequency:
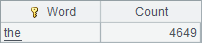
After becoming proficient, you can use one statement to find the word with the highest frequency of occurrence and its frequency of occurrence:
=file("MobyDick.txt").read().words().groups(~:Word;count(~):Count).maxp(Count)
If the amount of document data that needs to be counted is relatively large, or if the computer's memory is small and it can not read all the data at the same time for statistics, a cursor can be used to gradually extract the data and merge the statistical results for calculation, such as:
A |
|
1 |
MobyDick.txt |
2 |
=file(A1).cursor@i() |
3 |
=A2.(~.words()).conj() |
4 |
=A3.groups(~:Word;count(~):Count).maxp(Count) |
http://try.scudata.com.cn/try.jsp?splx=ExA006tjdcdcxl2.splx
A2 generates a cursor for the file, gradually reads data, and adds the @i option to return the result as a sequence of each line of text.
A3 splits each line of text in the cursor into words and returns each word one by one using conj. A4 directly uses groups to perform statistics on the words returned by the cursor, and extracts the data of the word with the highest frequency of occurrence from it:
The above code can also be written as a single statement:
=file("MobyDick.txt").cursor@i().(~.words()).conj().groups(~:Word;count(~):Count).maxp(Count)
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


MobyDick.txt
Chinese version