

How to solve TP database overload problem? Using AP database is not as good as using SPL
At the beginning of information system construction, usually only one database is used, and the database combines TP (transaction processing) and AP (analytical processing) together. As the scale of business and the amount of data continue to grow, the database faces increasing pressure. In order not to affect transaction, a common practice in the industry is to move data (usually cold data) out of the database and use a dedicated database to handle AP business. This method effectively reduces the burden on TP database and ensures the smooth operation of transaction business.
Normally, a professional AP database runs fast and does solve the performance problem to some extent, but it will cause some other problems.
Problems faced by AP database
The first is cost.
Currently, mainstream AP databases mainly adopt MPP framework, which is different from that of TP database. Although MPP can achieve better performance, both the software and hardware costs are high. Specifically, MPP will consume a lot of hardware resources, resulting in high hardware cost, and it needs to pay expensive license fee if a commercial software is used; Each node of MPP needs to be maintained separately, and both the uniform distribution and consistency assurance of data under a distributed framework will increase the operation complexity. These factors will drive up the cost of using AP database.
Adding an AP database will make management more complicated. To be specific, the management of the original TP database is already very complicated, including, design the metadata, make data meet constraints before loading into database, and control the access privilege, etc., and all these tasks are also required when an AP database is added, and more resources are needed due to difference of type of AP database. As a result, two sets of systems often require more than double the O&M cost, which brings cost problem.
In addition, migrating data from TP database to AP database is not easy and will face a dilemma.
The purpose of adding AP database is to move all AP businesses from TP database to AP database, yet migrating all AP businesses would pose significant risks. Not to mention whether the functionality of AP database is complete, many businesses that are originally implemented in one database may need to be redesigned after separation. Different database types and SQL compatibility differences will increase the difficulty of migration. All of these will make migrating all AP business in one go too risky.
Therefore, the safe approach is to migrate gradually, but it will encounter new problems.
We all have such experience that as the use of the database deepens and the business keeps growing, the originally normal query will become slower and slower. The reasons for this are not only the increase in data volume, but also many factors such as table quantity, indexes, metadata, and storage space. For a centrally managed database system, it is difficult to determine whether the database is effective for its own business before its load reaches a certain level.
Migrating just a little bit of business at initial stage will definitely run fast. However, it makes it difficult to determine whether the selected database is correct. As the migration proceeds gradually, a situation where the later-migrated business affects the previous business may arise, which still causes great risks. If it is found at a later stage that the AP database cannot handle its own business or needs to be scaled out a lot, then a dilemma will occur because it has accumulated a lot of work then.
In addition to the aforementioned cost and dilemma problems, there is also a more troublesome real-timeness problem.
Some businesses that used to run smoothly in one database cannot be implemented after separating some data from original database; the most typical business is the real-time query. Real-time query is naturally supported within one TP database, yet it is completely different after separating data into databases. For databases of the same type, it is sometimes possible to query across databases to implement real-time query in an indirect way. Although the performance is usually not high and the effect is poor, real-time query can at least be implemented. However, for AP database that is almost impossible to be the same in type as TP database, implementing real-time query becomes extremely difficult, resulting in a situation that real-time query business that was frequently utilized in the past has to be implemented through the way of T+1 or even T+N, and the impact on this business is self-evident.
In fact, real-time query is essentially the cross-source computing problem. If a system is open, cross-source computing can be easily implemented. However, the closedness of database requires that the data can be calculated only after they are loaded into database, it makes it extremely difficult to implement real-time query, which means that although the TP database overload problem is solved, it causes new problem, resulting in a decrease in degree in satisfying requirements.
Surely, we can also resort to HTAP database to implement real-time query, because the main goal of HTAP is to implement query and analysis in one database (does it feel like TP database?). HTAP is of course an option, but the reality is that the majority of HTAP databases have strong capabilities in terms of TP, but their capabilities in AP are often weak, which differs little from original TP databases in many cases. More importantly, using HTAP database will still face the direct cost and migration problems. The original TP database is just under pressure and not unusable; it would be a waste if it was completely abandoned.
Therefore, we need to find a relatively lightweight AP solution that will not incur high costs, preferably allowing for gradual migration while addressing real-time query problem.
Fortunately, we can use SPL as a solution to reduce the burden on TP database.
Open SPL solves various problems of AP business migration
As an open-source computing engine dedicated to AP business, SPL has the following characteristics: simply, lightweight, low usage cost, and its open computing ability and file storage support gradual migration of business without any impact on the business before and after business migration, and its mixed computing ability on multiple data sources naturally supports real-time query, making it easy to meet any business requirements even after separating AP business.
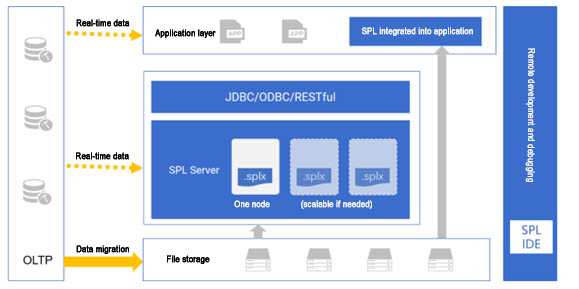
SPL application framework
Lightweight and low cost
One of the main differences between SPL and database is its simply and lightweight nature, which can reduce cost.
SPL has very low hardware requirements and the overall performance is very light. SPL can run on any operating system as long as a JVM environment with JDK 1.8 or higher version, including common VMs and Container, is available, and it only takes up less than 1G of installation space. Moreover, since SPL provides many high-performance mechanisms, the same effect as MPP cluster can often be achieved with only one SPL node, which will directly reduce the software and hardware costs (more details about high performance will be explained later).
What’s even more special is that SPL can not only be deployed independently but can also be integrated into applications, providing powerful computing ability within application. In this way, application can obtain powerful computing ability without having to rely on database. When migrating data from TP database to AP database, it can be initiated within the application. At the same time, SPL can serve as the data mart/front-end computing engine for this application.
SPL’s agile syntax also has advantages when implementing complex calculations. At the beginning of migration, we will usually choose the businesses with low performance and high resource consumption. Such businesses are often complicated, and it is often easier to remould in SPL than to modify SQL. This will bring lower development and debugging costs (to be explained in more detail later).
The lightweight of SPL is also reflected in its storage schema.
Compared with the closed storage of databases, SPL directly uses files to store data. In fact, SPL does not bind storage, users can use any medium to store data, but compared to other forms of storage, files have many incomparable advantages. Files are stored directly on the file system, either locally or on the network (cloud). Using file storage eliminates concerns about capacity issues. Since the storage is very cheap, we can copy as many files as we want, as it is nothing more than a few more files. The same is true for file backups for security purposes. There is almost no upper limit for file storage.
However, many open format files do not have high performance. For this reason, SPL provides dedicated high-performance file formats. Users can directly convert the source data and store as SPL files, and can also copy the data at will according to performance requirements during use.
Another advantage of file storage is the ability to organize data flexibly. Sometimes, we can achieve higher performance by using different algorithms after organizing the data according to computing objectives. Compared to database, which cannot intervene in storage, files are much more flexible. Specifically, the data can not only be stored redundantly in multiple copies, the same copy of data can also be designed in different organizational forms (such as ordered by different fields) to adapt to different computing scenarios.
Files in the file system can be managed in a multi-level directory structure, and we can set up different directories for different businesses or modules; a certain directory and subdirectories are dedicated to serving a single business, eliminating the coupling with each other; data modification will not affect other businesses; if a certain business goes down, the corresponding data (directory) can be safely deleted, making overall management very neat.
Gradual migration
With the support of file storage and openness, we can proceed with gradual migration.
As mentioned above, the reason why AP business is separated is because the pressure of one database that combines TP and AP businesses is large. Yet, although the database is under great pressure, it is still usable and can work well as long as the pressure is released. Since migrating all AP business in one go is too risky, the safe approach is to migrate gradually. Gradual migration can not only reduce risk but also conform to the characteristics of SPL. In the initial stage, migrating some statistical query scenarios with lower performance and high resource consumption will significantly reduce the workload of database.
More importantly, using SPL to migrate files will not result in a situation where the business migrated later affects the business migrated earlier, because the file storage does not create any relationship between files, and adding new file will not affect the use of existing files. Moreover, the original problems caused by the complex and closed system of database will not exist at all in SPL system, so we can safely proceed with migration.
With this gradual migration approach, the risk is low and the performance is controllable, so there is no need to migrate all AP businesses in one go.
Solve real-timeness problem
SPL has strong openness. In addition to file storage, SPL also supports multiple data sources, and any data source is logically equivalent for SPL. Besides the ability to connect to multiple data sources, SPL can also perform mixed calculation, which makes it easy to implement real-time query.

Due to its open computing ability, SPL can retrieve data from different databases respectively, and thus it can handle scenarios involving different types of databases well. SPL implements real-time query by performing a mixed calculation of cold data stored in file system (AP database) and the hot data stored in TP database. During calculation, SPL’ agile syntax and procedural computation can greatly simplify complex calculations in real-time query and increase development efficiency. Moreover, SPL is an interpreted-execution language, which supports hot deployment.
The following is the SPL code to perform a mixed query of the historical cold data stored in files and the hot data stored in production database:
| A | |
|---|---|
| 1 | =connect("oracle") |
| 2 | =A1.query@x("select sellerid, sum(amount) totalamount, count(amount) countamount,max(amount) maxamount,min(amount) minamount from sales group by sellerid") |
| 3 | =file("his_sales.btx").cursor@b() |
| 4 | =A3.groups(sellerid;sum(amount):totalamount,count(amount):countamount,max(amount):maxamount,min(amount):minamount) |
| 5 | =[A3,A4].conj().groups(sellerid;sum(totalamount):totalamount,sum(countamount):countamount,max(maxamount):maxamount,min(minamount):minamount) |
We can see that the real-time query that is difficult to implement after the separation of databases can be implemented with just a few lines of script, thereby completely solving all problems caused by the separation of databases.
Currently, there are already many practices in migrating business from TP to SPL; we summarize common practical scenarios at
SPL practice: migrate computing tasks out of database , you can refer to it to accomplish your own migration work.
Higher performance
In practice, SPL also utilizes the engineering mechanisms currently adopted in professional AP databases, such as compression, columnar storage, index, and vector-based calculation to ensure excellent performance. As mentioned above, SPL provides high-performance file storage that supports these mechanisms, eliminating the need for a closed database management system. The file storage can be directly distributed on any file system, making it more open.
More importantly, due to the inherent defects of SQL, SPL doesn’t continue to use SQL system but adopts an independent programming language, i.e., Structured Process Language. Moreover, SPL provides more data types and operations, and innovates fundamentally (as it is difficult to address theoretical defects with engineering methods). As we know, the software cannot speed up hardware. Yet, using low-complexity algorithms can reduce the computation amount of hardware, and the performance will be improved naturally. SPL offers many such high-performance algorithms. For example, for the complicated multi-step ordered operation mentioned above, it is easy to implement in SPL and, it is simple to code and the running speed is fast.
By means of such high-performance guarantee mechanisms, SPL requires fewer hardware resources, thus achieving the cluster effect with only a single machine. Further, SPL provides multi-thread parallel and distributed computing mechanisms, which make it highly scalable to further guarantee performance.
In the following cases, SPL achieves the cluster effect on only a single machine:
Open-source SPL turns pre-association of query on bank mobile account into real-time association
Open-source SPL Speeds up Query on Detail Table of Group Insurance by 2000+ Times
Open-source SPL improves bank’s self-service analysis from 5-concurrency to 100-concurrency
Open-source SPL speeds up intersection calculation of customer groups in bank user profile by 200+ times
Lower development cost
Since SPL does not adopt SQL system, there will be a learning cost before using it. Many people familiar with SQL may think the migration cost of using SPL will be higher.
In fact, this is not the case. From a long-term perspective, the development cost of SPL is lower!
Because SPL is not compatible with SQL, it does require recoding when migrating SQL, which will incur certain modification cost. However, SPL is easy to learn, and its syntax is concise, so the cost of modifying SQL is not very high. In contrast, although AP database also uses SQL, it will involve a lot of SQL modifications when migrating from TP database to AP database due to the types of databases are different and, since AP-related calculation logics are generally complex, it often needs to recode during modification. Moreover, the development and debugging of SQL itself is not easy and the workload of modification is not low, which is far from being as simple as “seamless migration” claimed by vendors. Overall, the modification cost of using SPL will not be much higher than using AP database, which is acceptable.
More importantly, SPL will bring long-term benefits.
Since the language ability of SQL is not complete, it is difficult for SQL to implement some complex calculations independently. For example, for the calculation of maximum number of days that a stock keeps rising, and more complex e-commerce funnel calculation (such calculations are not rare and often appear in practice), it is extremely difficult to implement in SQL, and often needs to resort to Python or Java. Consequently, it will make the technology stack complex and bring inconvenience to the operation and maintenance. TP, AP, and HTAP databases all have this problem.
In contrast, SPL provides richer data types and complete computing libraries, making it easy to handle scenarios that are difficult or even impossible to implement in SQL.
For example, when performing a funnel analysis for an e-commerce company to calculate the user churn rate, coding in SQL is very complicated, and the coding ways vary greatly when the types of databases are different. Moreover, the lack of migration ability would increase the modification cost. For example, the code of Oracle to implement a three-step funnel analysis is:
with e1 as (
select uid,1 as step1,min(etime) as t1
from event
where etime>= to_date('2021-01-10') and etime<to_date('2021-01-25')
and eventtype='eventtype1' and …
group by 1),
e2 as (
select uid,1 as step2,min(e1.t1) as t1,min(e2.etime) as t2
from event as e2
inner join e1 on e2.uid = e1.uid
where e2.etime>= to_date('2021-01-10') and e2.etime<to_date('2021-01-25')
and e2.etime > t1 and e2.etime < t1 + 7
and eventtype='eventtype2' and …
group by 1),
e3 as (
select uid,1 as step3,min(e2.t1) as t1,min(e3.etime) as t3
from event as e3
inner join e2 on e3.uid = e2.uid
where e3.etime>= to_date('2021-01-10') and e3.etime<to_date('2021-01-25')
and e3.etime > t2 and e3.etime < t1 + 7
and eventtype='eventtype3' and …
group by 1)
select
sum(step1) as step1,
sum(step2) as step2,
sum(step3) as step3
from
e1
left join e2 on e1.uid = e2.uid
left join e3 on e2.uid = e3.uid
Coding in SPL:
| A | |
|---|---|
| 1 | =["etype1","etype2","etype3"] |
| 2 | =file("event.ctx").open() |
| 3 | =A2.cursor(id,etime,etype;etime>=date(“2021-01-10”) && etime<date(“2021-01-25”) && A1.contain(etype) && …) |
| 4 | =A3.group(uid).(~.sort(etime)) |
| 5 | =A4.new(~.select@1(etype==A1(1)):first,~:all).select(first) |
| 6 | =A5.(A1.(t=if(#==1,t1=first.etime,if(t,all.select@1(etype==A1.~ && etime>t && etime<t1+7).etime, null)))) |
| 7 | =A6.groups(;count(~(1)):STEP1,count(~(2)):STEP2,count(~(3)):STEP3) |
Obviously, this code is more concise. In fact, the way to code in SPL is more versatile (for multi-step funnel calculation, it just needs to add parameters instead of adding sub-queries like SQL), and the performance is higher.
Besides conventional structured data computing library, SPL also provides the ordered operation that SQL is not good at, the grouping operation that retains the grouped sets, as well as various association methods, and so on. And, SPL syntax provides many unique features, such as the option syntax, cascaded parameter and advanced Lambda syntax, making complex calculations easier to implement.
Concise syntax, along with complete language ability, directly makes the development work very efficient, and eliminates the need to resort to other technologies, hereby making the technology stack simpler. With everything done in one system, it will naturally be very simple and convenient to operate and maintain. Therefore, for migrating AP businesses, especially when it comes to more complex calculations, there is a high probability that using SPL is more efficient and less expensive to develop than SQL.
In conclusion, when the TP database is overloaded, it is necessary to reduce its pressure but, it is not necessary to migrate all AP businesses in one go, and the goal can be achieved as long as the pressure is effectively reduced. Migrating AP business in a gradual way is a good approach, yet there will always be problems of one kind or another when migrating AP business to another database, such as high migration cost, difficult management and poor real-timeness. Fortunately, SPL’s openness and high performance can solve such problems effectively. Besides, SPL also provides complete, lightweight and high-performance computing capabilities, and consistent technology stack. From this point of view, it is a wise choice to replace AP database with SPL to reduce the burden of TP database.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version